V
主页
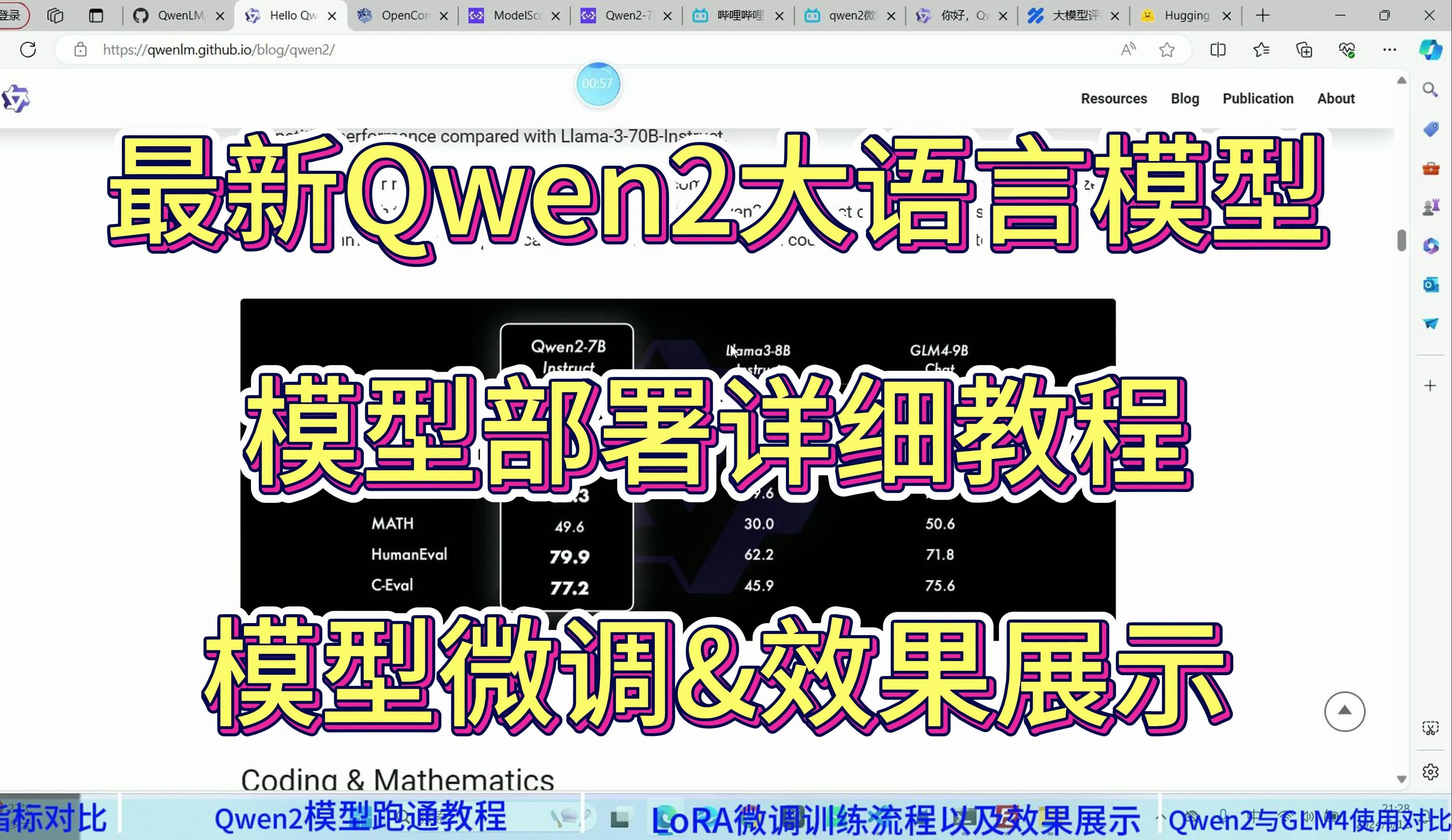
最新Qwen2大模型环境配置+LoRA模型微调+模型部署详细教程!真实案例对比GLM4效果展示!
发布人
该视频会详细从0到1去教会你如何部署Qwen2并且将其使用LoRA微调成独属于你自己的大模型,并且与另一个刚发布不久的GLM4进行了一个使用对比,感兴趣的小伙伴记得三连支持一下哦
打开封面
下载高清视频
观看高清视频
视频下载器
【喂饭教程】20分钟学会微调大模型Qwen2,环境配置+模型微调+模型部署+效果展示详细教程!草履虫都能学会~
【还不会微调Llama3?】这绝对是B站最全的llama3教程!迪哥手把手带你Llama3微调-量化-部署-应用一条龙!草履虫都能打造自己的专属大模型!
大模型微调实践:动手微调一个好玩/好用的大模型
60分钟速通LORA训练!绝对是你看过最好懂的AI绘画模型训练教程!StableDiffusion超详细训练原理讲解+实操教学,LORA参数详解与训练集处理技巧
qwen大模型地部署和微调法律大模型(只需5G内存)
20分钟学会qwen大模型本地部署+微调法律大模型(只需5G内存)
强推!B站最全的【大模型微调】实战教程,微调-量化-部署-应用一条龙解读!草履虫都能学会!!!
快速查找论文、GitHub项目复现通用教程,含深度学习图像分类、检测、分割 ,大模型、文本处理等项目复现教程
LoRA_04_基于PEFT进行llama3模型微调实战
微调LLM中的魔鬼细节|大型语言模型lora调教指南
最新开源大语言模型GLM-4模型详细教程—环境配置+模型微调+模型部署+效果展示
几百次大模型LoRA和QLoRA 微调实践的经验分享
GraphRAG太烧钱?Qwen2-7b本地部署GraphRAG,无需Ollama,从环境搭建到报错解决全流程
【保姆级教程】6小时掌握开源大模型本地部署到微调,从硬件指南到ChatGLM3-6B模型部署微调实战|逐帧详解|直达技术底层
Qwen2大模型保姆级部署教程,快速上手最强国产大模型
在服务器上部署通意千问Qwen-7B开源大模型
提示词、RAG、微调哪个会让大模型表现更好?1、实践中如何选择微调、rag、提示词工程 2、提示词工程使用方式 3、RAG VS 微调 4、rag评估框架
Windows基于LLaMA-Factory来微调训练finetune千问2(Qwen2)大模型,让大模型掌握绅士内容
大模型微调数据构造(补充课程)
【直播录屏】Qwen2大模型微调
如何轻松部署Qwen2:本地与云端部署指南! Qwen2、Llama3、GPT4o,模型深度对比。
千问Qwen2 7B模型8g显存运行效果,23Token/s
LlamaFactory:微调QWe (千问)模型 简单微调多数模型的便捷方法
【实战】通义千问1.8B大模型微调,实现天气预报功能
主流大模型哪个更适合日常使用,llama 3.1/Qwen2/GLM4大对比
qwen2 大语言模型发布了,具体如何本地安装部署,和 1100 亿参数 130G 大小的阿里千问1.5差距如何?
家庭PC本地部署LLama3 70B模型测试,对比70B和8B模型的效果,看看人工智障距离人工智能还有多远
【官方教程】ChatGLM-6B 微调:P-Tuning,LoRA,Full parameter
【大模型微调】使用Llama Factory实现中文llama3微调
都发布一个月了【还不会微调Llama3吗】!迪哥十分钟带你微调-量化-部署-应用一条龙解读!草履虫都能学会!!!
增强大模型问答能力!通义千问7B基于本地知识库问答操作指南
Qwen2-7B-微调-训练-评估
如何训练一个写小说的大模型?
通俗易懂理解全量微调和LoRA微调
通义千问-大模型SFT微调生成JSON
如何知道一个大模型在推理和训练时需要多少显存?
Qwen2很好,但我选GLM4
最新QWEN2.5大模型详细教程-环境配置、模型下载、本地数据库、RAG增强
llamafactory大模型微调llama.cpp量化gguf模型中转ollama微调量化后推理调用llamafactory本地windows部署报错解决方案
KAN>Mamba,将KAN融入UNet中,性能超越UMamba,详解模型结构、项目运行、创新部分