V
主页
在服务器上部署通意千问Qwen-7B开源大模型
发布人
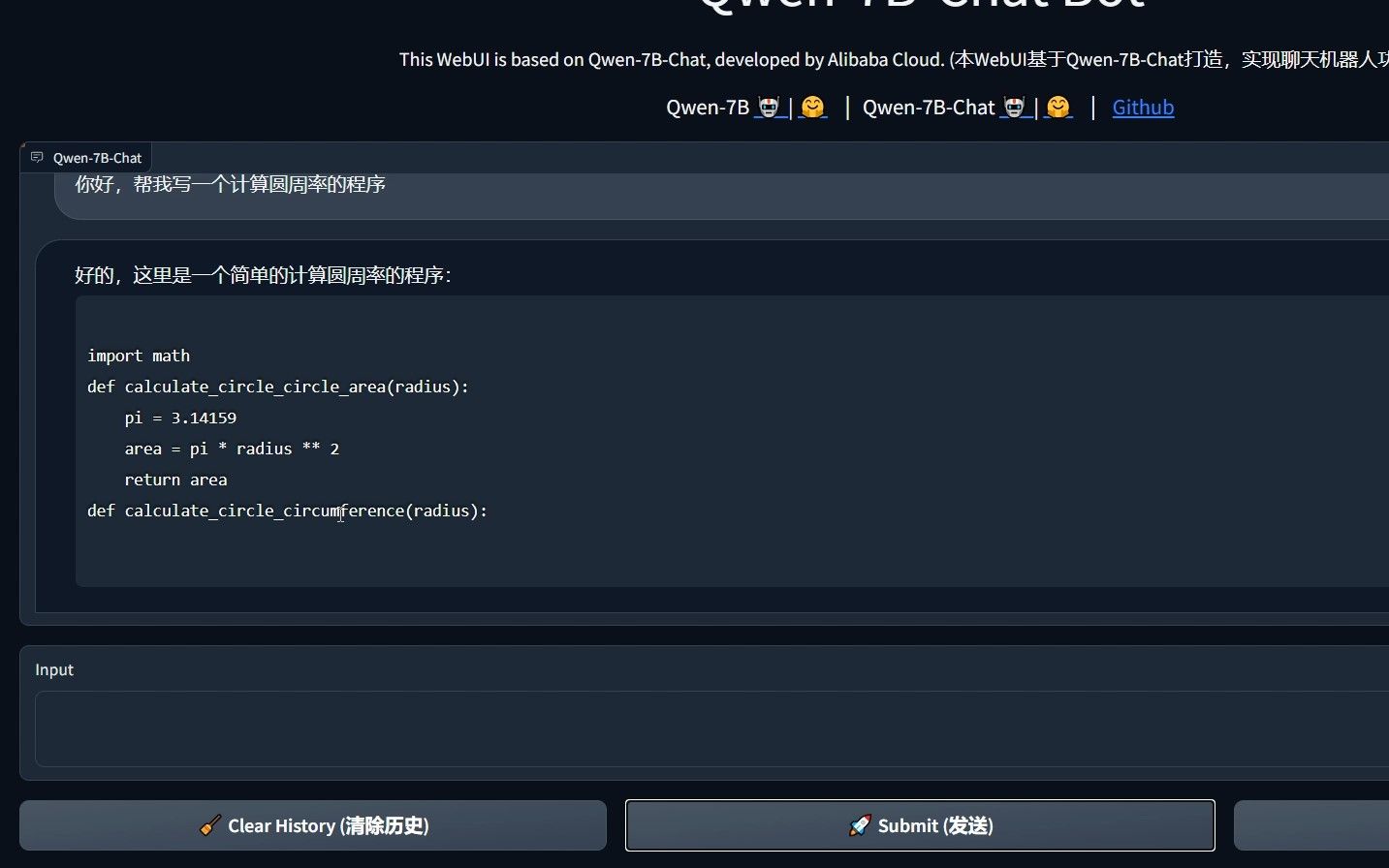
在阿里云上部署通意千问开源版Qwen-7B-Chat,学会后可以部署自己的通意千问。 视频中出现的指令: pip install transformers_stream_generator 带gradio的快速部署脚本: https://github.com/Jokerdajinbao/Qwen-7B-Chat-FastWeb https://gitee.com/JokerBao/Qwen-7B-FastWeb 官方的web_demo: git clone https://github.com/QwenLM/Qwen-7B.git 安装LFS: apt-get update apt-get install git-lfs git init git lfs install 拉取完整模型: git clone https://www.modelscope.cn/qwen/Qwen-7B-Chat.git
打开封面
下载高清视频
观看高清视频
视频下载器
阿里云服务器-OLLAMA部署QWEN2-72B RapidAI/llm EXAM测试
qwen2 大语言模型发布了,具体如何本地安装部署,和 1100 亿参数 130G 大小的阿里千问1.5差距如何?
最新的Qwen1.5系列大模型已经托管在Ollama平台,这绝对是最简单高效的本地私有化部署的方法,快进来看看吧
AI入门测试02-腾讯云服务器上部署chatglm3-6b大语言模型
可在笔记本跑的大模型 | 超轻量级大模型 | 千问大模型笔记本可部署 | Qwen1.5笔记本部署 | 大模型毕设的福利
qwen-7b 根本停不下来!
[测试] qwen 0.5b 1.8b 7b 14b 模型翻译文本测试 14b 效果不错 7b 可以接受
千问Qwen2 7B模型8g显存运行效果,23Token/s
手把手教你云端部署AI大模型应用
Ollama+Gemma+open-webui,手把手包会服务器部署
私有化部署AI模型成本分析,通义千问720亿参数,qwen1.5-72B-chat模型部署
阿里通义千问Qwen-7B的原理及ReAct用法
炼丹平台AutoDL的使用教程(适合小白)
英伟达4090实测通义千问Qwen-72B-Chat 模型性能
魔搭 通义千问-14B-chat AutoDL 自己租 GPU 进行本地部署 并对外提供 API 服务
手把手教学,部署自己的ChatGPT镜像站,从此不受任何约束!
实现任意大模型本地web、api部署,语音对话
万元预算本地流畅跑Qwen1.5_72B AWQ
阿里开源Qwen-72B-Chat AWQ 4bit量化生产环境演示 #小工蚁
国产开源多模态大模型 阿里云通义千问-VL本地部署+测试
本地运行通义千问32B!不吃配置保护隐私,可兼容AMD显卡或纯CPU
本地部署 Llama3 – 8B/70B 大模型!最简单的3种方法,支持CPU /GPU运行 !100% 保证成功!! | 零度解说
4060Ti 16G显卡安装通义千问Qwen1.5-14B大模型
阿里开源通义千问模型运行要多少GPU内存?
ChatGLM3-6B 对比 Qwen-14B,到底谁更强?
本地运行通义千问72B!兼容AMD显卡或纯CPU【LM Studio】
5分钟小白玩转服务器:一键搭建各种网站、设置数据库、监控服务器状态…
开源大模型私有化部署流程详解|Qwen大模型零门槛本地部署&ollama部署流程|
【保姆级教程】6小时掌握开源大模型本地部署到微调,从硬件指南到ChatGLM3-6B模型部署微调实战|逐帧详解|直达技术底层
详细版—LLaVA模型在服务器上部署和启动的过程!
Qwen 1.5 (通义千问升级版) | 新手入门
Qwen1.5系列6个模型如何选择? AWQ还是GPTQ?#小工蚁
使用ollama部署大模型并映射到公网API调用01
组装个双3090服务器,冲击百亿大模型!
GraphRAG太烧钱?Qwen2-7b本地部署GraphRAG,无需Ollama,从环境搭建到报错解决全流程
QwenAgent:基于阿里通义千问qwen 14b的初级agent雏形,结合BrowserQwen的浏览器扩展程序,辅助您进行网页及PDF文档总结、数据分析
Qwen2本地部署和接入知识库 支持N卡/A卡/纯CPU
最新Qwen2大模型环境配置+LoRA模型微调+模型部署详细教程!真实案例对比GLM4效果展示!
【HomeLab】Qwen-72B 大模型 离线 私有 本地部署 演示
CPU-双GPU联合部署Qwen1.5-72B-Chat 大模型 xinference(llama.cpp)-oneapi-fastGPT搭建本地AI助手