V
主页
用 300 元的显卡推理 Qwen1.5-14B 效果展示
发布人
配套的博客:https://blog.lucien.ink/archives/546 或 https://lucien.blog.csdn.net/article/details/136793257
打开封面
下载高清视频
观看高清视频
视频下载器
200元显卡大战Qwen2.5-32B,垃圾佬也想跑本地大模型,P104双卡Linux下Ollama跑Local LLM
双4090部署qwen72b大模型 每秒150tokens
整了一张Tesla M40 24G显卡玩玩 &安装教程
4、P40是否支持6B,7B,14B大模型规模实测
qwen大模型推理速度最快的服务搭建
为什么说14b是qwen2.5的更优解
以13B的基座模型击败恐怖如斯的GPT4,北大凭什么?
使用英伟达的 tensorrt-llm 对 qwen 进行加速
[测试] qwen 0.5b 1.8b 7b 14b 模型翻译文本测试 14b 效果不错 7b 可以接受
120块显卡p104-100跑图速度对比4000块的4060
9、双P40计算卡能否在本地跑14B
【穷训】2W服务器训练7B模型
部署本地大模型和知识库,最简单的方法
英伟达K80计算卡改造打游戏,视频剪辑
千元新玩具 计算卡可以玩游戏啦!TESLA P40秒变比肩2080TI显卡
组装一台自己的GPU炼丹主机,不贵,千元出头。AI主机也能捡垃圾。
Tesla P40单卡部署Qwen1.5-32B
垃圾佬的快乐~400块钱M40显卡24G显存,ESXI直通SD-WEB ,AI生图超高性价比
600元的P100 16G AI画画真香 stable diffusion
微软发布2.7B小模型,碾压谷歌Gemini!性能直接打平比自己大25倍的大模型?
单卡魔改2080ti跑Qwen1.5 14B AWQ速度测试
300元无矿的Tesla P4计算卡 ?仅75瓦还能畅玩3A游戏?ITX利器?我买回来一测便知!
4x2080ti 22G 组装低成本AI服务器跑Qwen1.5-110B-int4竟如此丝滑?
最强垃圾王Tesla P40 24GB
400元无矿的显卡?8G显存性能直逼700+的1660(附魔改教程)
QwenAgent:基于阿里通义千问qwen 14b的初级agent雏形,结合BrowserQwen的浏览器扩展程序,辅助您进行网页及PDF文档总结、数据分析
4060Ti 16G显卡安装Ollama+ChatTTS打造智能语音秘书(突破30秒限制)
Qwen2 72B Instruct 全量模型本地运行实测
仅需300块就能拥有秒杀众一线显卡!Tesla P4上手实测,性能远超你想象
通义千问Qwen1.5-32B发布,实际体验能追上ChatGPT吗?
70 行代码实现 AI 搜索
单卡2080Ti跑通义千问32B大模型(ollama和vllm推理框架)
五分钟!快速体验Qwen-Audio语音识别,阿里最新开源的大语音模型
ChatGLM3-6B 对比 Qwen-14B,到底谁更强?
无GPU本地运行开源大模型,速度可达8token/s
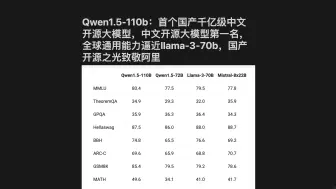
Qwen1.5-110b:首个国产千亿级中文开源大模型,中文开源大模型第一名,全球通用能力逼近llama3-70b,国产开源之光致敬阿里
通义千问110B本地8卡魔改2080ti推理速度测试报告
Qwen1.5-32B 多卡推理
低成本运行通义千问72B,实现高效高质翻译任务,媲美GPT4
炸裂!💥最强开源模型新王通义千问2.5 72B被我用4GB老显卡本地跑通了!