V
主页
Make-A-Character 阿里最新技术,在几分钟内生成高质量的文本到 3D 角色,开箱体验!
发布人
阿里最新开源的3D角色生成,Make-A-Character框架。 体验(排队很久。。):https://www.modelscope.cn/studios/XR-3D/InstructDynamicAvatar/summary 代码(尚未开源):https://github.com/Human3DAIGC/Make-A-Character 首页:https://human3daigc.github.io/MACH/ 该框架利用大语言模型(LLM)来提取各种面部属性(例如,脸型、眼睛形状)。这些语义属性被映射到相应的视觉线索,进而指导使用稳定扩散和 ControlNet 生成参考肖像图像。通过一系列 2D 人脸解析和 3D 生成模块,生成目标人脸的网格和纹理,再结合其他功能进行整合。参数化表示可以轻松生成生成的 3D 头像动画。
打开封面
下载高清视频
观看高清视频
视频下载器
MotionShop阿里最新动态3D人物替换技术,开箱体验!
M2UGen多模态音乐理解和生成开源!音乐问答,通过文本、图像、视频和音频生成音乐、音乐编辑
UDiffText,扩散模型文本控制精准生成
我从来不用自己剪视频,因为我会用AI
AnyDoor 阿里图片区域替换技术,开源了!实现虚拟换衣,页面元素替换!
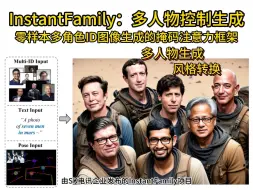
InstantFamily 多人物控制生成,零样本多角色ID图像生成的掩码注意力框架
IC-Light Controlnet作者最新开源,文本条件和参考图重新光照模型,开箱体验!
AtomoVideo 阿里高保真图像到视频(I2V)生成框架
ReplaceAnything as you need:阿里超高质量图片内容替换,开箱体验!
DiffusionGPT 字节最新开源文本到图像生成系统,输入绘图想法即可!
即将开源的AI 3D模型生成
MagicVideo-V2 字节视频生成,多阶段高美感视频生成,为开源,持续关注
字节最新3d技术ImageDream
超越GPT-4o!Allen AI重磅发布Molmo:最强多模态AI模型!碾压Llama 3.2!
最新视频生成大模型Vchitect-2.0开源,书生筑梦大模型支持生成20秒长度的视频
火火火!多模态生成发文量大涨!最新成果统一Transformer和Diffusion,含金量这一次直接爆表!
LUMIERE google最新视频生成技术,引入时空扩散模型,超强视频生成和编辑能力!
StyleSketch 面部草图生成,一种从面部图像中提取高分辨率风格化草图方法开源!
PIXART 华为用于4K文本到图像生成的扩散Transformer的弱到强训练
CoTracker,Meta最新开源目标追踪模型,处理遮挡等场景
Seed-Music字节发布高质量、可控的音乐生成统一框架,10s唱歌克隆
国内免翻墙使用chatgpt4.0教程,无需账号,无限次数,安卓手机也可使用。
【多模态+大模型+知识图谱】2024完整版:这绝对是B站最全的教程,论文创新点终于解决了!——人工智能/深度学习/aigc/计算机视觉
mvcontrolnet canny算子直接生成3D模型!
AniClipart 剪贴画动画生成模型,基于文本到视频先验引导的运动序列框架
YOLOv10多模态 结合Transformer与NMS-Free 融合可见光+红外光(RGB+IR)双输入【代码见评论区】
AniPortrait 腾讯开源虚拟人项目,对比阿里EMO,由音频驱动的真实肖像动画合成
MOFA-Video 腾讯联合高校基于SVD多类型控制信号视频生成,开源!
MusePose 姿势驱动虚拟人,腾讯最新开源端到端虚拟人技术!
ToonCrafter 卡通插值视频生成,香港高校和腾讯AI lab开源项目!
LTX Studio保持角色一致性的AI视频生成, 一个可以发挥您想象力的讲故事平台,已开启内测!
【大模型LLM】Meta最新发布的Llama3.2来了!Llama3.2的八点重要信息总结,支持多模态,手机也能用!
Open-Vocabulary SAM 最新图像分割模型开源,超2w个类别
基于SVD首尾帧进行关键帧插值,进行视频生成
CG鹿男 学生作品(制作修改过程展示)
ReconFusion,3张照片重建3D真实场景!
HandRefiner修复扩散模型生成过程中手异常问题,已开源!
Dynamic Typography SVG 动态字体版式,使得文本更加生动,驱动单字母视频化开源!
扩散模型角色一致性有了新的解法了!
VASA-1 微软发布虚拟人项目,单张图片驱动多情绪,界面化实时生成,对标EMO!