V
主页
Multi-Head Attention | 算法 + 代码
发布人
课件地址 : https://u5rpni.axshare.com
打开封面
下载高清视频
观看高清视频
视频下载器
这真的是AI吗?看来成片指日可待!
ViT| Vision Transformer |理论 + 代码
多头注意力(Multi-Head Attention)
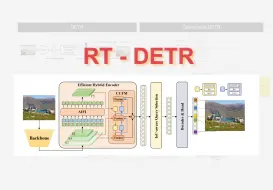
RT-DETR |1、abstract 算法概述
DETR |2、模型结构讲解
RT-DETR | 5、CCFM 收尾工作 | 理论+代码精讲
Diffusion | DDPM 代码精讲
深度学习 | ICML2024顶会 | NSA对MHSA多头自注意力全新升级,时间序列所有任务通用,适用于计算机视觉CV方向和NLP方向通用的即插即用注意力模块
AI邓丽君《苹果香》【Hi Res无损音质】六星街里还传来 巴扬琴声吗
Deformable DETR| 3、Deformable Attention、MSDeformAttention、流程讲解
【ChatGPT4.0手机版】国内无需魔法,无限次数使用教程来了!
B站最全收录!同济大佬将目前热门的六大时间序列预测任务:Time-LLM、Informer、LSTM、CNN-LSTM-Attention等通俗易懂的方式讲明白
Cross Attention is al you need!交叉注意力机制13篇必读
插值算法 | 最近邻插值法
yolo v11 | Detect Head 检测头
花了我6800,大模型算法工程师稳了!构建专属大模型的大模型入门到就业教程,人工智能、神经网络、transformer、视觉模型、NLP、提示工程
Deformable DETR | 1、Abstract 算法概述
Swin Transformer | Abstract
【ResNet+Transformer】基于PyTorch的迁移学习残差网络Resnet,细胞分类任务、ViT、DERT目标检测
Transformer 很 难 ? 50行代码手撸一个!(上)
DenseNet
GNN+Transformer到底有多强?迪哥精讲迪哥精讲图神经网络融合transformer,绝对是今年的研究热点!
yolov8 | 损失函数 之 4、正样本匹配 代码精讲(下)
[动手写神经网络] 手动实现 Transformer Encoder
yolov1 算法精讲(上)
损失函数 | 目标检测 - 定位损失
Transformer本质上在解决什么事?迪哥手把手带你从零基础开始搭建Transformer!论文解读+源码复现,草履虫都能学会!-人工智能/深度学习/大模型
Batch Normalization
【文献汇报】多尺度注意力Transformer
【强推!】 这绝对是AI+医疗最好的【医疗机器学习】全套教程,不愧是MIT教授31小时全学会通关了!!!-人工智能|AI医疗|人工智能医疗
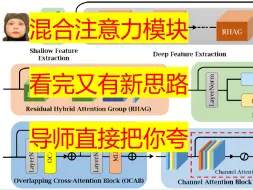
【即插即用】CVPR 2023 混合注意力模块
Swin Transformer (下)
深度学习基础 | 训练策略 | EMA (参数的)指数移动平均
NMS 非极大值抑制 | IoU 交并比
优化器 |SGD |Momentum |Adagrad |RMSProp |Adam
【大模型面试】Flash Attention面试连环炮,淘汰80%面试竞争者
从入门到精通一口气学完CNN、RNN、GAN、GNN、DQN、Transformer、LSTM等八大深度学习神经网络!丨零基础篇
训练日志 | logging |(1)基础使用
模型结构图绘制 -- Axure 软件使用教程
Dataset 与 DataLoader(下)| DataLoader 参数详解