V
主页
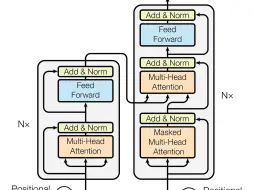
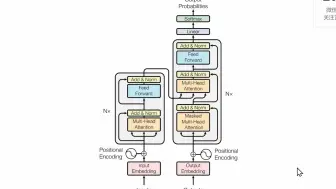
多头注意力(Multi-Head Attention)
发布人
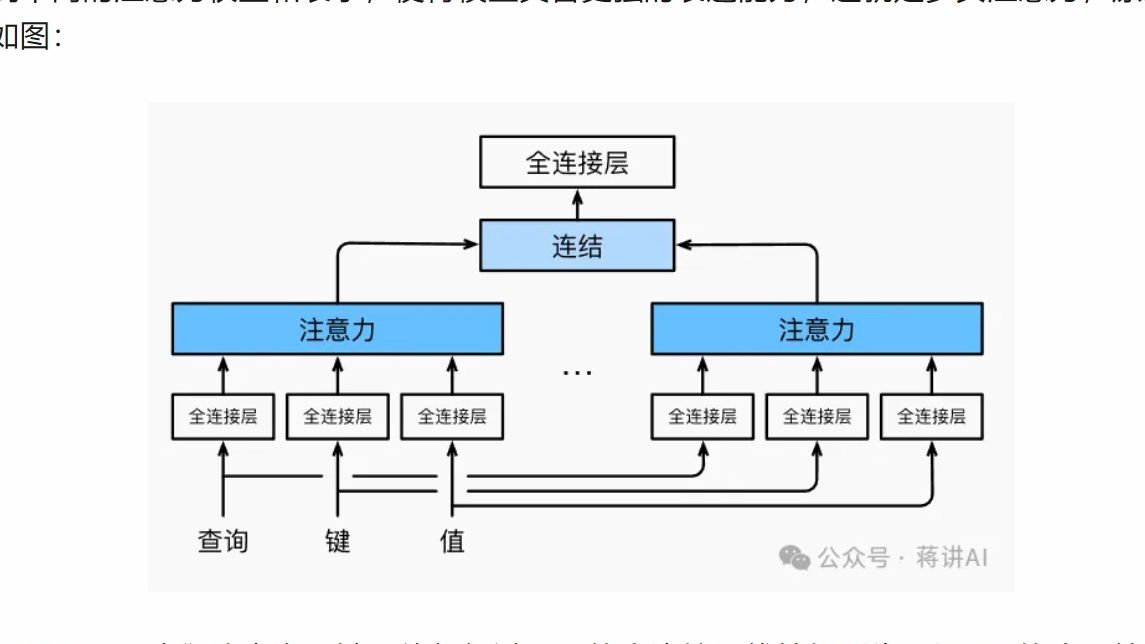
多头注意力提升了模型的特征表达能力,增强了其对复杂数据结构的理解能力。由于其每个头可以关注不同的特征或模式,所以整体上提供了更加丰富的上下文信息,有助于捕捉复杂的依赖关系,让模型能更好地理解全局信息,提高泛化性。
打开封面
下载高清视频
观看高清视频
视频下载器
[动手写 Transformer] 手动实现 Transformer Decoder(交叉注意力,encoder-decoder cross attentio)
注意力(attention)机制
小波变换+Transformer荣登Nature!预测误差降低36%!
剑指Softmax注意力梯度下降,基于指数变换的注意力实在厉害! 深度学习这下真大升级!
Cross Attention is al you need!交叉注意力机制13篇必读
直接带你把Transformer手搓一遍,这次总能学会Transformer了吧!
【全126集】目前B站最系统的Transformer教程!入门到进阶,全程干货讲解!拿走不谢!(神经网络/NLP/注意力机制/大模型/GPT/RNN)
西交|深度学习研讨班-4|从Attention到Transformer再到Mamba
直观理解Vision Transformer(ViT)及Diffusion Models使用扩散模型进行图像合成,
小波变换+注意力机制新突破! 再登Nature!附15种创新思路
【文献汇报】多尺度注意力Transformer
超全超简单!同济大佬53集带你零基础吃透GNN图神经网络:GCN图卷积、PYG、图注意力机制、图相似度、轨迹预测实战一口气学完!-人工智能/神经网络/深度学习
即插即用-2024ICLR 自适应多尺度时序注意力机制模块!可拥有时序预测,异常检测!
【B站强推!】这可能是B站目前唯一能将【3D点云+三维重建】讲清楚的教程了,看完小白也能信手拈来,建议收藏!计算机视觉|点云
2024即插即用通道和位置注意力机制,涨点起飞
(CVPR 2024)即插即用多尺度注意力机制MAB模块,即用即涨点起飞
【深度学习 搞笑教程】33 Seq2Seq网络 Attention注意力机制 | 草履虫都能听懂 零基础入门 | 持续更新
【即插即用】2023 高效多尺度注意力模块
【即插即用】2023 线性注意力模块
绝了!用降噪耳机原理升级注意力? 微软亚研&清华独创Transformer
2024最新即插即用卷积模块MSPANet打败Resnet、SE、CBAM,CNN框架模型涨点!
Transformer架构及代码精讲
B站最全收录!同济大佬将目前热门的六大时间序列预测任务:Time-LLM、Informer、LSTM、CNN-LSTM-Attention等通俗易懂的方式讲明白
什么是层归一化LayerNorm,为什么Transformer使用层归一化
已经厌倦了Softmax注意力?试试不依赖位置编码的新注意力 保证做长度泛化轻轻松松
Transformer真的不难啊!100集带你逐层分解Transformer模型——注意力机制、神经网络、位置编码、编码器、解码器等!算法原理+实战,通俗易懂!
预测误差降低36%!小波变换+Transformer荣登Nature!
即插即用双重交叉注意力机制DCA,涨点起飞
小波变换+注意力机制再登Nature!这15种创新突破,你还不知道?
【共享LLM前沿】假如我从11月1号开始学大模型!9小时学会搭建对话机器人办公助手、大模型预训练微调、四大多模态大模型!
全网最全收录!目前热门的六大时序预测任务:CNN-LSTM-Attention神经网络时序预测、Time-LLM结合大模型时序预测、informer、LSTM.
Transformer的大规模预训练
(CIKM'24) 交通流量预测模型 DEC-Former:从解耦的视角重新思考注意力机制在时空建模中的应用
即插即用-打败传统CNN和Transformer的创新模块!指标提升,参数减少、模型涨点
【算法精讲】长短期记忆网络LSTM到底在干啥?(35分钟搞懂原理及代码)
【文献汇报】2024 多尺度卷积增强Transformer
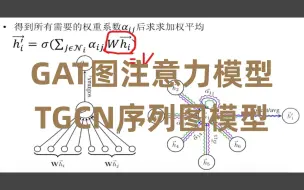
计算机博士终于把图注意力模型(GAT)与序列图模型(TGCN)讲得如此透彻了!
【ResNet+Transformer】基于PyTorch的迁移学习残差网络Resnet,细胞分类任务、ViT、DERT目标检测
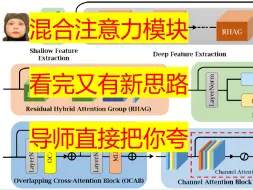
【即插即用】CVPR 2023 混合注意力模块
深度学习论文被评“创新性不足、工作量不够”怎么办? -人工智能/深度学习/机器学习