V
主页
Bonsai | Writing Great Reward Functions
发布人
https://www.youtube.com/watch?v=0R3PnJEisqk&t=136s 本视频分享仅供交流学习使用,切勿任何商业用途
打开封面
下载高清视频
观看高清视频
视频下载器
Google || Munchausen Reinforcement Learning
Pytorch复现论文MADDPG(Multi Agent Deep Deterministic Policy Gradients)
PyTorch论文复现 | Proximal Policy Optimization (PPO)
(Sergey Levine)Offline Reinforcement Learning
Deep Robust Reinforcement Learning and Regularization
Deep Reinforcement Learning and Atari 2600
Maximum Entropy Reinforcement Learning
ICAPS 2020: Tutorial on "Regularization in Reinforcement Learning"
Multi-Agent Deep Reinforcement Learning for Connected Autonomous Driving
ICML 2020 Causal Reinforcement Learning
ICML 2020 Sample Efficient Reinforcement Learning of Undercomplete POMDPs
FinRL_ A Deep Reinforcement Learning Library for Automated Trading in Quantitati
[3] MDPs and Dynamic Programming
Marc Bellemare | A Distributional Perspective on Reinforcement Learning
Sergey Levine | Unsupervised Reinforcement Learning
DeepMind | The Role of Multi-Agent Learning in Artificial Intelligence Research
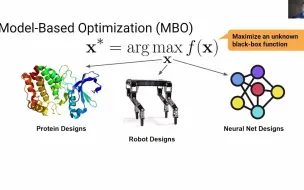
Conservative Objective Models for Effective Offline Model-Based Optimization
Challenges for Deep Reinforcement Learning in Complex Environments
An Analysis of Reinforcement Learning with Function Approximation
L1 MDPs, Exact Solution Methods, Max-ent RL (Foundations of Deep RL Series)
双热点强强联合的发文方向:Transformer+强化学习!
2021 DeepMind x UCL RL Lecture Series - Deep Reinforcement Learning-12
L4 TRPO and PPO (Foundations of Deep RL Series)
Value-Based Deep RL Requires Explicit Regularization
【李宏毅】强化学习课程完整版千万不要错过!简单明了的PPO算法讲解!深度强化学习、人工智能、机器学习、大模型
John Schulman | Policy Gradient Methods: Tutorial and New Frontiers
【人工智能基础】第50讲:PPO算法
2021 DeepMind x UCL RL Lecture Series - Deep Reinforcement Learning-13
Alexander Grishin: Controlling the overestimation bias
这可能是我见过强化学习和模型预测控制最好的教程!四大名校教授精讲动态系统和仿真、最优控制、策略梯度方法、MPC
2021 DeepMind x UCL RL Lecture Series - Planning & models-8
John Schulman: Reinforcement Learning from Human Feedback:Progress and Challenge
John Schulman | Natural Policy Gradients, TRPO, PPO
IsaacLab实现四足机器人AMP,视频训了1000轮,开源链接在简介
2021 DeepMind x UCL RL Lecture Series - Approximate Dynamic Programming-10
【大模型+强化学习】怎么理解大模型训练中的RLHF(人类反馈强化学习)?ChatGPT背后的数学原理
基于MADDPG的多无人机目标合围
【中英字幕】强化学习和模型预测控制18讲!四大名校教授精讲模型预测控制、最优控制、强化学习入门
2021 DeepMind x UCL RL Lecture Series - Multi-step & Off Policy-11
2021 DeepMind x UCL RL Lecture Series - Exploration & Control-2