V
主页
京东 11.11 红包
强化学习论文分享20230612
发布人
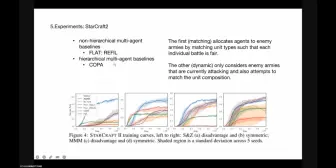
MULTI-AGENT COLLABORATION VIA REWARD ATTRIBUTION DECOMPOSITION >内容简介:提出了协同Q学习(CollaQ)方法,它在StarCraft多智能体挑战中实现了最先进的性能,并支持即兴团队协作。首先将多智能体协作问题形式化为奖励分配的联合优化,并展示在一定条件下,每个智能体具有近似最优的分散式Q函数,并且可以分解为两个项:自身项仅依赖于智能体自身的状态,交互项与附近智能体的状态相关,通常由当前智能体观察到。这两个项使用常规的DQN进行联合训练,并通过多智能体奖励归因(MARA)损失进行调控,以确保两个项保持其语义。CollaQ在不同的StarCraft地图上进行了评估,以相同数量的环境步骤提高了40%的胜率,优于现有的最先进技术(如QMIX、QTRAN和VDN)。在更具挑战性的即兴团队协作设置中(即在不重新训练或微调的情况下重新调整/添加/删除单位),CollaQ的表现超过先前的最先进方法超过30% >关键词:RL, MULTI-AGENT, REWARD DECOMPOSITION Multi-Agent Reinforcement Learning is A Sequence Modeling Problem >内容简介:GPT系列和BERT等大型序列模型在自然语言处理、视觉和强化学习等方面都表现出了出色的性能和泛化能力。如何将多智能体决策问题抽象为序列建模问题,并从SMs的蓬勃发展中获益,是一个自然的后续问题。摘要提出了一种新的多智能体变压器(MAT)结构,该结构能有效地将协作多智能体强化学习(MARL)应用于SM问题,其目标是将智能体的观测序列映射到智能体的最优动作序列。我们的目标是在MARL和SMs之间架起一座桥梁,以便为MARL释放现代序列模型的建模能力。我们的MAT的核心是一个编码-解码器架构,该架构利用了多智能体优势分解定理,将联合策略搜索问题转化为一个连续的决策过程;这使得多智能体问题的时间复杂度仅为线性,更重要的是,这使得MAT具有单调的性能改进保证。与先前的技术(如Decision Transformer)只适合预先收集的离线数据不同,MAT是通过同策略方式从环境中进行在线试错训练的。为了验证MAT,我们对《星际争霸2》、《Multi-Agent MuJoCo》、《Dexterous Hands Manipulation》和《谷歌Research Football基准》进行了广泛的实验。结果表明,与包括MAPPO和HAPPO在内的强基线相比,MAT实现了优越的性能和数据效率。此外,我们证明了无论智能体的数量如何变化,MAT都是一个优秀的少数-短期学习者。。 >关键词:sequence models,multi-agent sequential decision paradigm,few-short
打开封面
下载高清视频
观看高清视频
视频下载器
【论文代码复现122】基于强化学习的路径规划问题||强化学习和群智能优化算法有什么区别
从模型预测控制到强化学习12:DDPG做动态控制-研究生入学培训答疑
【具身论文阅读】Diffuser: 基于diffusion的强化学习规划器
我愿称李宏毅强化学习为天花板课程!简单易懂!清晰明了的 PPO算法强化学习入门教程!深度强化学习、人工智能、神经网络
【比刷剧还爽!】太完整了!中国科学院大学和上海交大强联合的(PyTorch+深度学习+强化学习+机器学习)课程分享!快速入门极简单——人工智能_AI_神经网络
大模型如何增强强化学习?简单粗暴理解大模型训练中的人类反馈强化学习RLHF!PPO算法、ChatGPT背后的数学原理
代码实现大模型强化学习(PPO),看这个视频就够了。
从模型预测控制到强化学习12:DDPG做动态控制-研究生入学培训答疑
强化学习框架-Legged Gym 训练代码详解
一步步教AI玩游戏,强化学习通关教程!2024必学AI课程,赶紧收藏学习起来吧!
不愧是李宏毅老师讲的【强化学习】简直太详细了!!小白也能信手拈来,学完可就业!-附资料(人工智能|机器学习|深度学习|强化学习)
这可能是我见过强化学习和模型预测控制最好的教程!四大名校教授精讲动态系统和仿真、最优控制、策略梯度方法、MPC
强化学习论文分享20230912
不愧是李宏毅老师讲的【强化学习】简直太详细了!!小白也能信手拈来,建议收藏!(人工智能|机器学习|深度学习|强化学习)
强化学习论文分享20240131
双热点强强联合的发文方向:Transformer+强化学习!
强化学习论文分享20240314_2
【大模型+强化学习】怎么理解大模型训练中的RLHF(人类反馈强化学习)?ChatGPT背后的数学原理
【MPC+强化学习】四大名校教授精讲强化学习和模型预测控制18讲!Actor Critic模型预测控制、策略梯度方法
【基于深度强化学习的冠军级别无人机竞速】强化学习和模型预测控制MPC中英字幕18讲!
强化学习论文分享20240411_2
MPC+强化学习!Actor Critic模型预测控制,苏黎世大牛教授人类水平性能的自主视觉无人机演讲
如何直观理解PPO算法?博士详解近端策略优化算法原理+公式推导+训练实例!强化学习、深度强化学习、李宏毅
Transformer+强化学习成为双热点强强联合的发文方向
深度学习研一,三个月流水线一般发论文教程。
强化学习论文分享20230410
我愿称之为强化学习天花板课程!台大李宏毅教授亲授强化学习教程,究极通俗易懂!建议收藏!
太完整了!我居然3天时间就掌握了【机器学习+深度学习+强化学习+PyTorch】理论到实战,多亏了这个课程,绝对通俗易懂纯干货分享!
强化学习论文分享20240117_1
强化学习论文分享20240509
强化学习论文分享2023-01-12
从模型预测控制到强化学习-11:确定性策略梯度DPG与随机策略梯度SPG,从控制的角度理解(D)DPG, A2C, QAC, REINFORCE
强化学习论文分享2022-12-29
强化学习论文分享20230515
强化学习论文分享2023-03-02
强化学习论文分享20240314_1
强化学习论文分享2022-12-08
强化学习论文分享20230522
强化学习论文分享20240307
强化学习论文分享20230731