V
主页
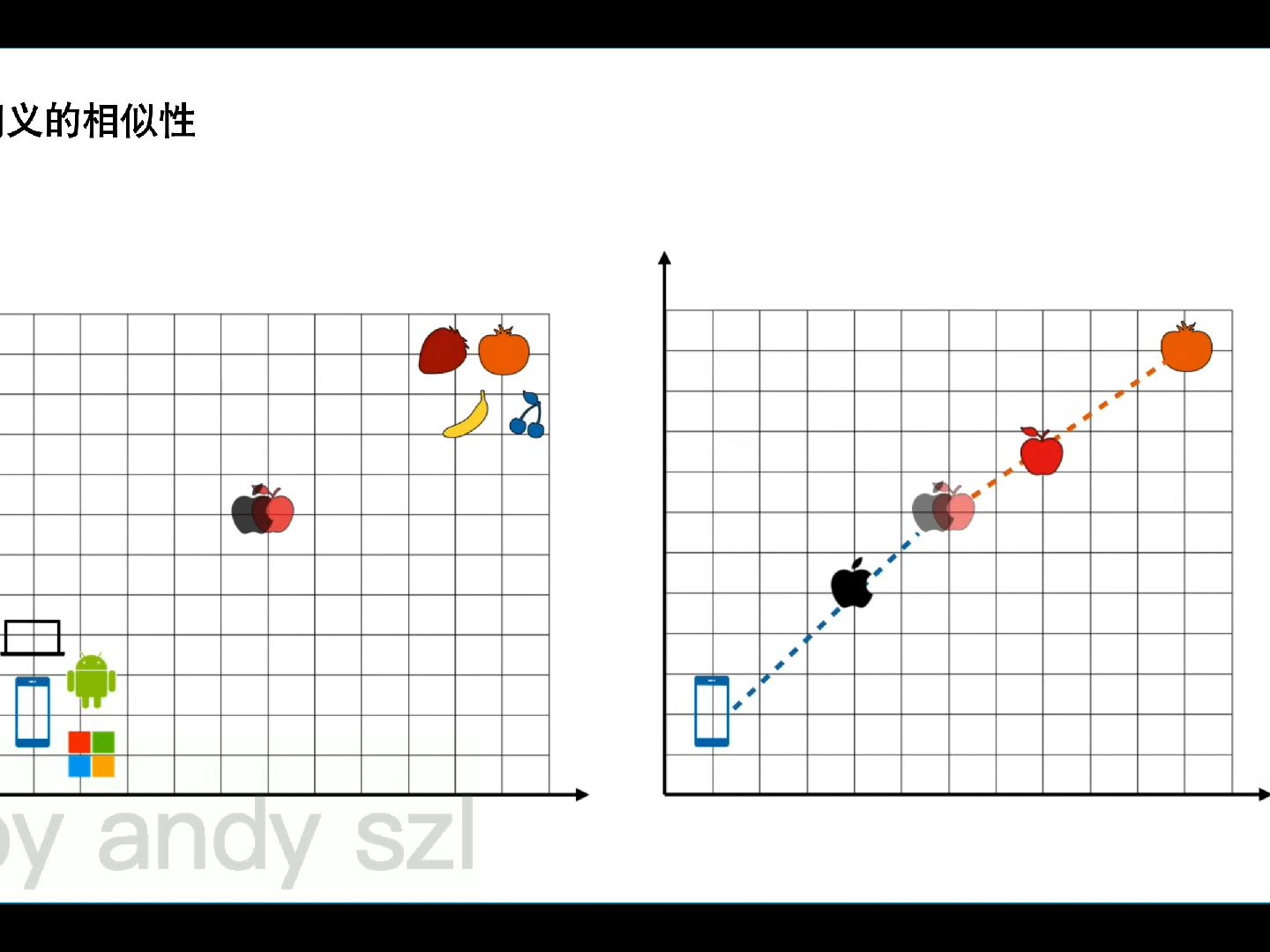
白话transformer(二)_QKV矩阵
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
直接带你把Transformer手搓一遍,这次总能学会Transformer了吧!
白话transformer(一)_注意力机制
小波变换+Transformer荣登Nature!预测误差降低36%!
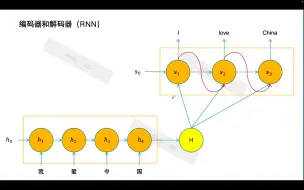
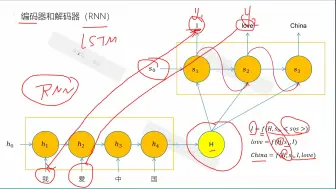
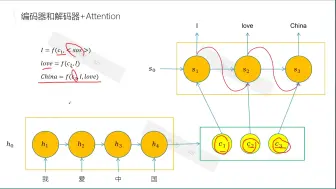
白话transformer(六)_编码器和解码器
seq2seq
白话transformer(四)_整体架构
神经网络必看!如何从零入门CNN、RNN、GAN、GNN、DQN、Transformer、LSTM等!清华大佬一天就教会了我如何入门神经网络算法,绝对通俗易懂
西交|深度学习研讨班-4|从Attention到Transformer再到Mamba
白话transformer(三)_QKV矩阵code演示
白话transformer(五)_位置编码
多头注意力(Multi-Head Attention)
白话transformer(补充)_seq2seq的局限性
bert代码解释
马斯克效率吓坏黄仁勋,19天部署最强计算集群,训练Grok3可缩到4天,AI拐点即将到来!#科技 #人工智能 #AI #AGI #马斯克 #黄仁勋 #英伟达
bert训练过程
这是我迄今为止见过将 Chat GPT 原理最好的可视化。具象化的展示了Transformer神经网络模型结构。像在四维看三维。
直观理解Vision Transformer(ViT)及Diffusion Models使用扩散模型进行图像合成,
【中英双语】ChatGPT背后的数学原理是什么?带你看懂Transformer模型的数学矩阵实现!
超全超简单!同济大佬53集带你零基础吃透GNN图神经网络:GCN图卷积、PYG、图注意力机制、图相似度、轨迹预测实战一口气学完!-人工智能/神经网络/深度学习
太...完整了!终于有人能把【Transformer】入门到精通这么通俗的讲清楚了,最新前沿方向均有涉猎!-人工智能/深度学习
剑指Softmax注意力梯度下降,基于指数变换的注意力实在厉害! 深度学习这下真大升级!
白话transformer(补充)_attention
使用cursor两个半小时完成我的创意,以后大概不需要那么多程序员了吧,产品经理的含金量还在上升
【B站强推!】这可能是B站目前唯一能将【3D点云+三维重建】讲清楚的教程了,看完小白也能信手拈来,建议收藏!计算机视觉|点云
预测误差降低36%!小波变换+Transformer荣登Nature!
为什么大学计算机全是深度学习?
RNN基本原理
【文献汇报】2024 多尺度卷积增强Transformer
神经网络到底是做什么的?5大经典神经网络(CNN/RNN/GAN/LSTM/Transformer)计算机博士一次带你学明白!简直不要太爽!
ALBERT简介
人工智能需要哪些高级的数学知识?
记住,你就是组会绘图最牛的仔!!!
【文献汇报】多尺度注意力Transformer
白话知识蒸馏
深度学习论文被评“创新性不足、工作量不够”怎么办? -人工智能/深度学习/机器学习
强推!从入门到精通CNN、RNN、GAN、GNN、DQN、Transformer、LSTM等八大深度学习神经网络一口气全部学完!比刷剧还爽!
【数学视角下的Transformer】不愧是MIT数学系的Philippe Rigollett——自注意力机制、深度神经网络、CV+NLP
强推!草履虫都能一口气学完CNN、RNN、GAN、GNN、DQN、Transformer、LSTM、DBN等八大深度学习神经网络算法!真的比刷剧还爽!
RNN为什么会出现梯度消失和梯度爆炸以及公式推导解释
小波变换+注意力机制再登Nature!这15种创新突破,你还不知道?