V
主页
详解I-JEPA: 杨立昆大神用第一个'世界模型'降维打击计算机视觉圈
发布人
Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture This paper demonstrates an approach for learning highly semantic image representations without relying on hand-crafted data-augmentations. We introduce the Image-based Joint-Embedding Predictive Architecture (I-JEPA), a non-generative approach for self-supervised learning from images. The idea behind I-JEPA is simple: from a single context block, predict the representations of various target blocks in the same image. A core design choice to guide I-JEPA towards producing semantic representations is the masking strategy; specifically, it is crucial to (a) sample target blocks with sufficiently large scale (semantic), and to (b) use a sufficiently informative (spatially distributed) context block. Last year, Meta’s Chief AI Scientist Yann LeCun vision is to create machines that can learn internal models of how the world works so that they can learn much more quickly, plan how to accomplish complex tasks, and readily adapt to unfamiliar situations. This model, the Image Joint Embedding Predictive Architecture (I-JEPA), learns by creating an internal model of the outside world, which compares abstract representations of images (rather than comparing the pixels themselves). I-JEPA delivers strong performance on multiple computer vision tasks, and it’s much more computationally efficient than other widely used computer vision models. The representations learned by I-JEPA can also be used for many different applications without needing extensive fine tuning. For example, we train a 632M parameter visual transformer model using 16 A100 GPUs in under 72 hours, and it achieves state-of-the-art performance for low-shot classification on ImageNet, with only 12 labeled examples per class. Other methods typically take two to 10 times more GPU-hours and achieve worse error rates when trained with the same amount of data.
打开封面
下载高清视频
观看高清视频
视频下载器
教你如何下载MapChart
求大神鉴定
必读:生成式AI Sora相关的Normalizing Flows
深度篇:谷歌“万能”语音识别大模型USM全面碾压了OpenAI的Whisper模型
击败OpenAI GPT-4的Claude 3有什么秘密武器?Opus, Sonnet, and Haiku Models, Constitutional AI
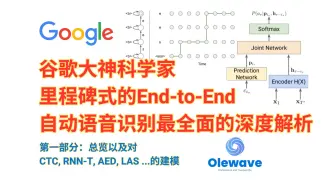
谷歌大神科学家独家深度揭秘端到端自动语音识别算法与系统, [第一部分]:总述与建模
免翻墙,无需要登陆,无限制使用国内免费chatgpt4.0,分享给有需要的人
意识决定物质世界 两位量子力学大神证明「意识决定现实」
GraphRAG与普通RAG比较,效果,速度,费用
教你注册谷歌
从OpenAI's Whisper模型到你自主研发的语音识别服务: 后处理与语言模型 (第四部分)
深度篇:Apple的新MM1是否是地表最强多模态大模型?
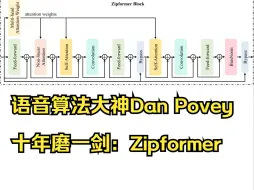
[论文阅读] Zipformer: A faster and better encoder for automatic sp
十分钟告诉你为什么OpenAI的Whisper语音识别没ChatGPT那么好用 [语音语言论文阅读]
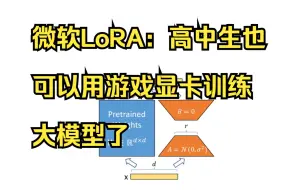
详解LoRA: 高中生用游戏显卡也可以训GPT-3大语言模型
【云手机】一部手机如何变成多部使用,实现游戏多开搬砖,应用软件多开。云手机内有ROOT,谷歌三件套,没有任何限制,享受畅快玩机!
通俗易懂理解大模型预训练和微调
【手机端】谷歌账号注册!100%靠谱一次性过
谷歌账号注册 2024年最新谷歌邮箱注册流程 亲测有效!
【全368集】强推!2024最细自学手机版视频剪辑教程,看完就会!别再走弯路了,逼自己一个月学完,从0基础小白到视频剪辑大神只要这套就够了!
详解SpeechT5: 将谷歌T5模型引入语音领域
Coze扣子收费 | 国内免费无限制平替,附使用教程
OpenAI的gpt-4o-mini模型微调免费啦🧨
RAG增强检索是如何工作的?
【OpenAI】免费体验官方版本,国内直连!爆炸最新消息
全村人的希望OpenAI Whisper的时间戳居然不准?咋整?
2024谷歌地球最新安装教程
全世界最惊人的十大商标,谷歌设计的缺陷是故意?第一名你绝对不想不到的角度!!
突发!OpenAI发布SearchGPT,Google和Perplexity面临新挑战!
GraphRAG制作的《凡人修仙传》知识图谱长什么样?
免费使用ChatGPT4o的方法!
谷歌账号无法登录?
【国内白嫖】7月7日最新ChatGPT4.0
如何利用Langchain和通义千问实现工具调用
油管大神:如果你还年轻,时间就是你最大的杆杠(每天1小时改变你的人生)
免费公益GPT4站点,打开即用,无任何门槛,长期维护
Google账号注册和使用的3个提醒,都是经验之谈和血泪教训
谷歌拿下ICML 2024 最佳论文!VideoPoet:视频生成的大语言模型
十分钟看懂谷歌金钟罩Transformer以及语音的LAS模型
OpenAI和Airbnb创始人:未来一切产品都将AI化 | 奥特曼回应为什么被董事会开除|ChatGPT | Sam Altman|人工智能|文心一言