V
主页
京东 11.11 红包
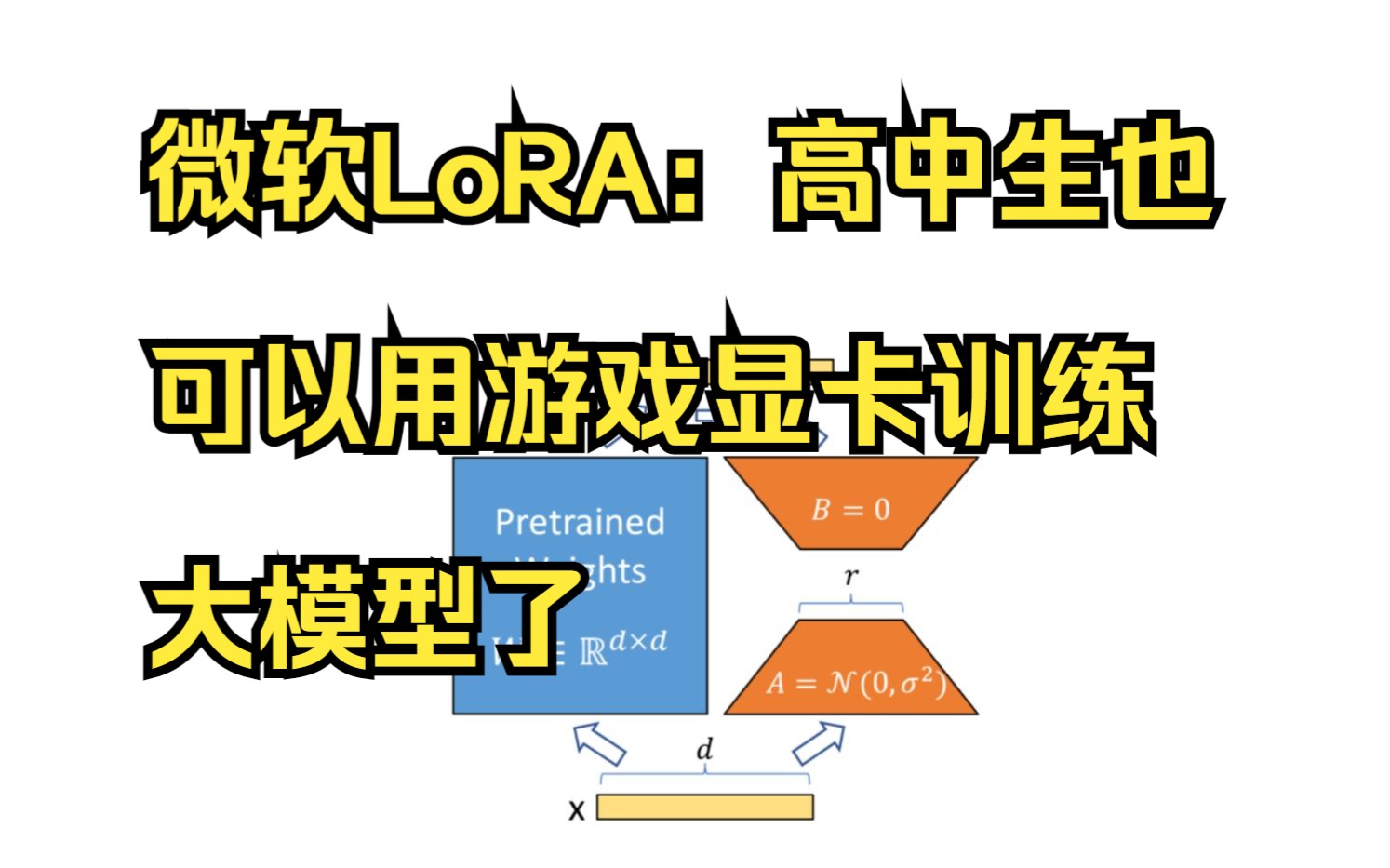
详解LoRA: 高中生用游戏显卡也可以训GPT-3大语言模型
发布人
LoRA: Low-Rank Adaptation of Large Language Models Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, Weizhu Chen An important paradigm of natural language processing consists of large-scale pre-training on general domain data and adaptation to particular tasks or domains. As we pre-train larger models, full fine-tuning, which retrains all model parameters, becomes less feasible. Using GPT-3 175B as an example -- deploying independent instances of fine-tuned models, each with 175B parameters, is prohibitively expensive. We propose Low-Rank Adaptation, or LoRA, which freezes the pre-trained model weights and injects trainable rank decomposition matrices into each layer of the Transformer architecture, greatly reducing the number of trainable parameters for downstream tasks. Compared to GPT-3 175B fine-tuned with Adam, LoRA can reduce the number of trainable parameters by 10,000 times and the GPU memory requirement by 3 times. LoRA performs on-par or better than fine-tuning in model quality on RoBERTa, DeBERTa, GPT-2, and GPT-3, despite having fewer trainable parameters, a higher training throughput, and, unlike adapters, no additional inference latency. We also provide an empirical investigation into rank-deficiency in language model adaptation, which sheds light on the efficacy of LoRA. We release a package that facilitates the integration of LoRA with PyTorch models and provide our implementations and model checkpoints for RoBERTa, DeBERTa, and GPT-2 at this https URL.
打开封面
下载高清视频
观看高清视频
视频下载器
【全874集】目前B站最全最细的ChatGPT零基础全套教程,2024最新版,包含所有干货!一天就能从小白到大神!少走99%的弯路!存下吧!很难找全的!
详解OpenAI GPT-3: Language Models are Few-Shot Learners(2/3)
详解I-JEPA: 杨立昆大神用第一个'世界模型'降维打击计算机视觉圈
NotebookLM 最全教程: AI 学习神器! 一款 AI 笔记本居然让我 1 分钟变身英文播客主播?!
详解OpenAI GPT-3: Language Models are Few-Shot Learners(1/3)
2024.10.12 | GPT-o1到底有多强?| 新研究论文测试能力的极限性 | 规划、推理、逻辑和现实世界空间智能方面
分析2023最新的OpenAI的GPT-4技术报告
全村人的希望OpenAI Whisper的时间戳居然不准?咋整?
谷歌最强人工智能Gemini翻译网页 翻译质量达到人工翻译水平 中英文对照翻译显示比OpenAI ChatGPT更强 沉浸式翻译让我的英语水平突飞猛进看世
微调技术大比拼:全量微调与LoRA、QLoRA实测对比!
从OpenAI's Whisper模型到你自主研发的语音识别服务: 后处理与语言模型 (第四部分)
OpenAI Realtime API - 构建超低延迟的实时语音助手
VideoLingo 一键自动翻译视频
你想多了:非程序员也能用Cursor开发应用?15个实用避坑指南
对话尼克:OpenAI弯道超车谷歌背后的第一性原理
新手如何学习大语言模型,从个人角度谈一谈(基础,论文,代码等等)
详解SpeechT5: 将谷歌T5模型引入语音领域
谷歌能打开了???(没挂梯子)
从OpenAI's Whisper模型到你自主研发的语音识别服务: 总论 (第一部分)
【通义千问2.0】微调之SFT训练
【通义千问2.0】微调之DPO训练
国内网络谷歌账号全流程教学,安卓谷歌play商店使用,下载软件,购买游戏指导
【通义千问2.0】微调之理论篇(pre-train/sft/dpo)
用支付宝2分钟搞定GPT订阅❗️国内半价就能用🚀 喂饭级实操教程,MJ、cursor、perplexity等软件通用......
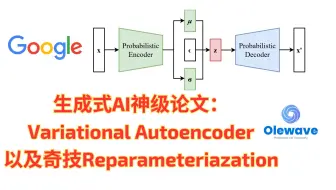
生成式AI神级论文:谷歌DeepMind的Variational Autoencoder (VAE) and Reparameterization
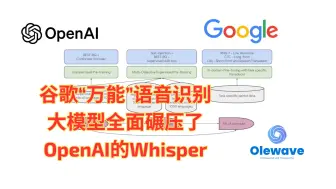
深度篇:谷歌“万能”语音识别大模型USM全面碾压了OpenAI的Whisper模型
OpenAI公开新项目“草莓”!人工智能的黑匣子将要被打开?(内含GPT 4o实测)
详解语音合成中的Hifi-GAN
如何在微软官网下载Win10的ISO镜像
【双语精校】Sam Altman:新发布的推理模型 o1 preview 相当于 GPT-2 时刻,但是升级曲线会很陡峭,很快就会达到它的 GPT-4 时刻
OpenAI最强开源Swarm AI智能体框架!Swarm框架实战教程,从函数调用到多表Text to SQL,再到自动化编程AI智能体,轻松打造专属AI智能体
OpenAI o1模型对比GPT:推理范式的创新
OpenAI Swarm多智能体开源框架快速入门与项目开发实战|Swarm Agent开发快速入门与项目开发实战
十分钟告诉你为什么OpenAI的Whisper语音识别没ChatGPT那么好用 [语音语言论文阅读]
3D生成一切!谷歌新作CAT3D:多视图扩散生成3D一切内容!收录顶会NeurIPS 2024!
2024.10.12 | OpenAI发布全新多智能体编排框架Swarm | 5分钟快速了解
【360AI搜索】国内首发“慢思考模式”AI搜索引擎,思路清晰质量好
从零到一快速搭建本地RAG引擎|大模型私有知识库问答技术快速实践|本地RAG引擎搭建流程
【Soviet OS】基于ит技术构建的Soviet 2000正式发布
女子回家路上惨遭三壮汉轮流强推AI大模型应用开发2024精品课【LangChain+LlamaIndex+Agent+多模态】——大模型总综述——理论开篇