V
主页
京东 11.11 红包
第五章(2):线性模型和决策树的对比
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
第五章(3):分箱,提高线性模型的预测效果
第六章(3):调参的理论
第五章(2):将数值型变量变为分类型变量
第一章:(3).回归模型和随机森林的对比
第二章:(2).分类预测案例
第六章(1):交叉验证
第二章:(1).分类变量的0-1编码
第五章(7):特征工程处理时间序列
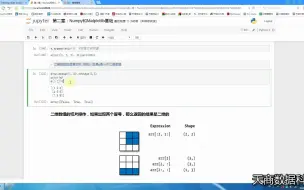
第二章(4):二维array数组
第五章(1):特征工程简介
第六章(4):数据合并函数join()
第五章(1):数据框的样本的随机选取,样本子集的抽取
第一章(4):python的学习方法,我们用的教材
第一章:(2).数量预测之随机森林
第四章(1):缺失值的处理
第一章(12):分支结构
第六章(2):数据合并函数concat()
第二章(3):一维array数组
第六章(3):数据合并函数merge()
第一章(5):python中的变量
第一章(6):列表(上)
第二章(2):numpy模块初步介绍
第四章(2):SVC模型的特征必须作预处理
第二章(8):画图中的基本的参数
第一章(18):异常的处理,以及zip函数
第一章(14):循环(下)
第六章(4):调参的python实现
第一章(9):字符串
第二章(5):二维数组的逻辑切片,二维数组拉直为一维数组
第三章(5)附录,不平衡数据credit的分析
第一章(11):字典
第二章(7):Matplotlib中的两种基本画图方式
第六章(5):调参的可视化
第四章(1):特征X的预处理
第一章(15):列表推导式(字典推导式等)
第六章(1):数据合并函数append()
第一章(13):循环(上)
第一章:(1)数量预测之线性回归
第三章(3):pandas:数据框的定义
第一章(2):python编译环境的安装