V
主页
京东 11.11 红包
在云主机上使用4090部署,使用fastchat框架成功部署Baichuan2-13B-Chat模型,8bit运行模式,可以进行问答啦!
发布人
和ChatGLM3不同,部署13B的百川需要硬件环境和软件环境更高: python使用3.10版本,硬件设备使用4090有24G显存,最高占用21G。 解决部署遇到的各种问题。主要是软件匹配的问题。 文章地址: https://blog.csdn.net/freewebsys/article/details/134567530 相关大模型地址: https://blog.csdn.net/freewebsys/category_12270092.html
打开封面
下载高清视频
观看高清视频
视频下载器
【xinference】(11):在compshare上使用4090D运行xinf和chatgpt-web,部署GLM-4-9B-Chat大模型,占用显存18G
【xinference】(9):本地使用docker构建环境,一次部署embedding,rerank,qwen多个大模型,成功运行,非常推荐
【chatglm3】(10):使用fastchat本地部署chatlgm3-6b模型,并配合chatgpt-web的漂亮界面做展示,调用成功,vue的开源项目
【LocalAI】(6):在autodl上使用4090部署LocalAIGPU版本,成功运行qwen-1.5-32b大模型,占用显存18G,速度 84t/s
【ollama】(7):使用Nvidia Jetson Nano设备,成功运行ollama,运行qwen:0.5b-chat,速度还可以,可以做创新项目了
【LocalAI】(5):在autodl上使用4090Ti部署LocalAIGPU版本,成功运行qwen-1.5-14b大模型,占用显存8G
【Dify知识库】(2):开源大模型+知识库方案,Dify+fastchat的BGE模型,可以使用embedding接口对知识库进行向量化,绑定聊天应用
【candle】(4):使用rsproxy安装rust环境,使用candle项目,成功运行Qwen1.5-0.5B-Chat模型,修改hf-hub下载地址
【compshare】(1):推荐一个GPU按小时租的平台,使用实体机部署,可以方便快速的部署xinf推理框架并提供web展示,部署qwen大模型,特别方便
使用autodl服务器,两个3090显卡上运行, Yi-34B-Chat-int4模型,用vllm优化,增加 --num-gpu 2,速度23 words/s
【大模型研究】(6):在AutoDL上部署,成功部署Mixtral-8x7B大模型,8bit量化,需要77G显存,355G硬盘
【喂饭教程】20分钟学会微调大模型Qwen2,环境配置+模型微调+模型部署+效果展示详细教程!草履虫都能学会~
【wails】(1):使用go做桌面应用开发,wails框架入门学习,在Linux上搭建环境,运行demo项目,并打包测试
【xinference】(8):在autodl上,使用xinference部署qwen1.5大模型,速度特别快,同时还支持函数调用,测试成功!
【LocalAI】(7):在autodl上使用4090D部署,成功部署localai-cuda-12的二进制文件,至少cuda版本是12.4才可以,运行qwen
【xinference】(6):在autodl上,使用xinference部署yi-vl-chat和qwen-vl-chat模型,可以使用openai调用成功
【candle】(3):安装rust环境,使用GPU进行加速,成功运行qwen的0.5b,4b,7b模型,搭建rust环境,配置candle,下使用hf-mir
【大模型研究】(1):从零开始部署书生·浦语2-20B大模型,使用fastchat和webui部署测试,autodl申请2张显卡,占用显存40G可以运行
【LocalAI】(9):本地使用CPU运行LocalAI,一次运行4个大模型,embedding模型,qwen-1.5-05b模型,生成图模型,语音转文字模型
【大模型研究】(9):通义金融-14B-Chat-Int4金融大模型部署研究,在autodl上一键部署,解决启动问题,占用显存10G,有非常多的股票专业信息
【LocalAI】(4):在autodl上使用3080Ti部署LocalAIGPU版本,成功运行qwen-1.5-7b大模型,速度特别快,特别依赖cuda版本
【大模型研究】(3):在AutoDL上部署,使用脚本一键部署fastchat服务和界面,部署生成姜子牙-代码生成大模型-15B,可以本地运行,提高效率
【大模型研究】(5):在AutoDL上部署,一键部署DeepSeek-MOE-16B大模型,可以使用FastChat成功部署,显存占用38G,运行效果不错。
使用autodl服务器,RTX 3090 * 3 显卡上运行, Yi-34B-Chat模型,显存占用60G
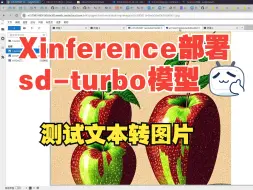
【xinference】(4):在autodl上,使用xinference部署sd-turbo模型,可以根据文本生成图片,在RTX3080-20G上耗时1分钟
【ollama】(6):在本地使用docker-compose启动ollama镜像,对接chatgpt-web服务,配置成功,可以进行web聊天了,配置在简介里
特别推荐!在modelscope上可以使用免费的CPU和限时的GPU啦,成功安装xinference框架,并部署qwen-1.5大模型,速度7 tokens/s
【大模型知识库】(3):本地环境运行flowise+fastchat的ChatGLM3模型,通过拖拽/配置方式实现大模型编程,可以使用completions接口
【xinference】(18):在4090设备上通过Xinference框架,快速部署CogVideoX-5b模型,可以生成6秒视频,效果还可以,只支持英文,
【Dify知识库】(1):本地环境运行dity+fastchat的ChatGLM3模型,可以使用chat/completions接口调用chatglm3模型
【创新思考】(1):使用x86架构+Nvidia消费显卡12G显存,搭建智能终端,将大模型本地化部署,语音交互机器人设计,初步设计
一键部署本地私人专属知识库,开源免费!1000多种开源大模型随意部署!
【candle】(1):学习huggingface的candle项目,新的模型部署框架,搭建rust环境,并将rust安装到制定目录,执行rust命令
【Dify知识库】(12):在autodl上,使用xinference部署chatglm3,embedding,rerank大模型,并在Dify上配置成功
Qwen大模型本地部署教程!教你本地微调一个法律大模型,无需GPU,只要5G内存!附安装包和微调文档!
【LocalAI】(12):本地使用CPU运行LocalAI,piper语音模型已经切换到了hugging faces上了,测试中文语音包成功!
【xinference】(19):在L40设备上通过Xinference框架,快速部署CogVideoX-5b模型,可以生成6秒视频,速度快一点
【chatglm3】(8):模型执行速度优化,在4090上使用fastllm框架,运行ChatGLM3-6B模型,速度1.1w tokens/s,真的超级快。
【ai技术】(4):在树莓派4上,使用ollama部署qwen0.5b大模型+chatgptweb前端界面,搭建本地大模型聊天工具,速度飞快
【chatglm3】(7):大模型训练利器,使用LLaMa-Factory开源项目,对ChatGLM3进行训练,特别方便,支持多个模型,非常方方便