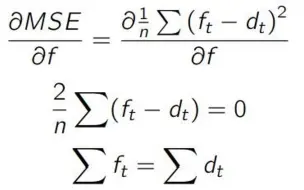V
主页
[LLMs 实践] 19 llama2 源码分析 RoPE apply_rotary_emb 从绝对位置编码到相对位置编码
发布人
本期code:https://github.com/chunhuizhang/personal_chatgpt/blob/main/tutorials/llama2_src_03_RoPE_apply_rotary_emb.ipynb
打开封面
下载高清视频
观看高清视频
视频下载器
[LLMs 实践] 18 llama2 源码分析 RoPE 相对位置编码的复数形式
[personal chatgpt] 从 RoPE 到 CoPE(绝对位置编码,相对位置编码,Contextual Position Encoding)
[LLMs 实践] 15 llama2 源码初步(text completion & chat completion)
[LLMs 实践] 21 llama2 源码分析 GQA:Grouped Query Attention
[LLMs 实践] 14 llama2 introduction 及 fine tune llama2(guanaco dataset)
[LLMs 实践] 09 BPE gpt2 tokenizer 与 train tokenizer
[BERT 番外] Sin Position Encoding 的简洁实现(RoPE 基础)
[LLMs 实践] 03 LoRA fine-tune 大语言模型(peft、bloom 7b)
[LLMs 实践] 12 LLM SFT training (trl SFTTrainer、alpaca dataset)
[LLMs 实践] 10 预训练语料,mapping & streaming(load_dataset)
[LLMs 实践] 221 llama2 源码分析 generate 的完整过程
[LLMs 实践] 17 llama2 源码分析(RMSNorm 与 SwiGLU)
[LLMs tuning] 01 trl SFTTrainer 中的 formatting_func 与 DataCollatorForCompletion
[LLMs 实践] 01 llama、alpaca、vicuna 整体介绍及 llama 推理过程
[LLMs 实践] 04 PEFT/LoRA 源码分析
[LLMs tuning] 03 llama3-8B instruct SFT on Financial RAG
[LLMs tuning] 02 accelerate ddp 与 trl SFTTrainer
[LLMs 实践] 07 fp16 与自动混合精度训练(amp)显著提升 batch size
[LLMs 实践] 20 llama2 源码分析 cache KV(keys、values cache)加速推理
[LLMs 实践] 08 LLM.int8 量化细节 (load_in_8bit)以及 bitsandbytes 库
[LLMs 实践] 06 LLaMA,Alpaca LoRA 7B 推理
【手推公式】【销量预测】【回归分析】MAE与MSE在回归分析时的区别,为什么MSE倾向于回归均值,MAE倾向于回归中位数
[personal chatgpt] LLAMA 3 整体介绍(与 LLama 2 的不同?)
[LLMs tuning] 04 optimizer Trainer 优化细节(AdamW,grad clip、Grad Norm)等
[LLMs tuning] 05 StackLlama、SFT+DPO(代码组织、数据处理,pipeline)
[LLMs inference] quantization 量化整体介绍(bitsandbytes、GPTQ、GGUF、AWQ)
[personal chatgpt] Llama2 7B vs. Llama3 8B (词表、attention 及 mlp)
[LLMs inference] hf transformers 中的 KV cache
【销量预测】R2(r_squared)与相关系数(correlation)的区别和联系,什么情况下R2=correlation,R2与MAE,RMSE
[pytorch optim] 优化器相关 AdaGrad(adaptive gradient) 与 RMSprop,自适应梯度
【数字图像处理】HoG+SVM+NMS行人检测(pedestrian detection)(python-opencv)
[矩阵分析] 旋转矩阵的计算机与应用(复平面,RoPE)
[pytorch 网络拓扑结构] 深入理解 nn.LayerNorm 的计算过程
[LLM & AIGC] 02 ChatGPT api 的简单介绍(system, user, assistant)与多轮对话
[动手写 Transformer] 从 RNN 到 Transformer,为什么需要位置编码(position encoding)
[pytorch 模型拓扑结构] 深入理解 nn.CrossEntropyLoss 计算过程(nn.NLLLoss(nn.LogSoftmax))
[LLMs 实践] 13 gradient checkpointing 显存优化 trick
[pytorch] [求导练习] 04 前向计算与反向传播与梯度更新(forward,loss.backward(), optimizer.step)
rope换脸先锋3.0版本使用注意事项和容易出现错误的地方
[动手写 bert 系列] bert embedding 源码解析,word_embedding/position_embedding/token_type