V
主页
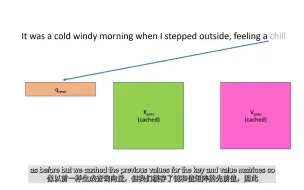
[LLMs 实践] 20 llama2 源码分析 cache KV(keys、values cache)加速推理
发布人
本期code:https://github.com/chunhuizhang/personal_chatgpt/blob/main/tutorials/llama2_src_cache_kv.ipynb
打开封面
下载高清视频
观看高清视频
视频下载器
kvCache原理及代码介绍---以LLaMa2为例
怎么加快大模型推理?10分钟学懂VLLM内部原理,KV Cache,PageAttention
77、Llama源码讲解之GroupQueryAttention和KV-cache
Transformer模型中的KV缓存:优化内存利用
KV缓存:Transformer中的内存使用!
【双语·YouTube搬运·生成语言模型中的KV缓存】The KV Cache: Memory Usage in Transformers
大语言模型(LLM)开发实战系列课程原理部分:Llama2模型原理及源码详细解析
[QKV attention] kv-cache、decoder only vs. BERT, 单向注意力 vs. 双向注意力
transformers源码阅读——如何看懂模型代码(以llama为例)
[LLMs 实践] 21 llama2 源码分析 GQA:Grouped Query Attention
图解llama架构 解读源码实现
Grouped-Query Attention (GQA)原理及代码介绍---以LLaMa2为例
[LLMs 实践] 19 llama2 源码分析 RoPE apply_rotary_emb 从绝对位置编码到相对位置编码
LLM面试_为什么常用Decoder Only结构
[LLMs 实践] 221 llama2 源码分析 generate 的完整过程
LLM推理过程中自动缓存KV Cache功能 #小工蚁
【复现】transformer推理速度优化-kvcache技术
[LLMs 实践] 18 llama2 源码分析 RoPE 相对位置编码的复数形式
[LLMs 实践] 02 LoRA(Low Rank Adaption)基本原理与基本概念,fine-tune 大语言模型
主流开源大模型LLama基本架构 KV-Cache, Rotary Positional Embedding, RMS Norm, Grouped Query
[LLMs 实践] 17 llama2 源码分析(RMSNorm 与 SwiGLU)
自制大模型推理框架-KVCache动手实现-秋招快人一步
DeepSeek V2开源大模型为什么可以节省90% 以上KV Cache?
RoPE旋转位置编码之LLaMA2实现方法--代码解读
PagedAttention(vLLM):更快地推理你的GPT【论文粗读·7】
如果提前看过这个视频,当时面对华为面试官的提问就不会卡壳了 The KV Cache_ Memory Usage in Transformers
llama.cpp 源码解析-- CUDA版本流程与逐算子详解
[LLMs 实践] 12 LLM SFT training (trl SFTTrainer、alpaca dataset)
RoPE旋转位置编码原理解读
[LLMs 实践] 03 LoRA fine-tune 大语言模型(peft、bloom 7b)
[personal chatgpt] 从 RoPE 到 CoPE(绝对位置编码,相对位置编码,Contextual Position Encoding)
[LLMs 实践] 14 llama2 introduction 及 fine tune llama2(guanaco dataset)
[LLMs 实践] 15 llama2 源码初步(text completion & chat completion)
Llama 2 模型结构解析
[LLMs 实践] 04 PEFT/LoRA 源码分析
[LLMs 实践] 01 llama、alpaca、vicuna 整体介绍及 llama 推理过程
[动手写bert系列] 01 huggingface tokenizer (vocab,encode,decode)原理及细节
[番外] float16 与 bf16 表示和计算细节
[personal chatgpt] LLAMA 3 整体介绍(与 LLama 2 的不同?)
[动手写Bert系列] bertencoder self attention 计算细节及计算过程