V
主页
[NeRF进展,编辑方向] 三星多伦多AI中心,多伦多大学,约克大学等:SPIn-NeRF,可快快速完成3D Segmentation和Inpainting任务
发布人
SPIn-NeRF: Multiview Segmentation and Perceptual Inpainting with Neural Radiance Fields Ashkan Mirzaei(三星多伦多AI中心,多伦多大学), Tristan Aumentado-Armstrong(三星多伦多AI中心,多伦多大学,Vector AI研究院), Konstantinos G. Derpanis(三星多伦多AI中心,约克大学,Vector AI研究院), Jonathan Kelly(多轮多大学), Marcus A. Brubaker(三星多伦多AI中心,约克大学,Vector AI研究院), Igor Gilitschenski(多伦多大学), Alex Levinshtein(三星多伦多AI中心) 项目主页:https://spinnerf3d.github.io/ Neural Radiance Fields (NeRFs) have emerged as a popular approach for novel view synthesis. While NeRFs are quickly being adapted for a wider set of applications, intuitively editing NeRF scenes is still an open challenge. One important editing task is the removal of unwanted objects from a 3D scene, such that the replaced region is visually plausible and consistent with its context. We refer to this task as 3D inpainting. In 3D, solutions must be both consistent across multiple views and geometrically valid. In this paper, we propose a novel 3D inpainting method that addresses these challenges. Given a small set of posed images and sparse annotations in a single input image, our framework first rapidly obtains a 3D segmentation mask for a target object. Using the mask, a perceptual optimization-based approach is then introduced that leverages learned 2D image inpainters, distilling their information into 3D space, while ensuring view consistency. We also address the lack of a diverse benchmark for evaluating 3D scene inpainting methods by introducing a dataset comprised of challenging real-world scenes. In particular, our dataset contains views of the same scene with and without a target object, enabling more principled benchmarking of the 3D inpainting task. We first demonstrate the superiority of our approach on multiview segmentation, comparing to NeRF-based methods and 2D segmentation approaches. We then evaluate on the task of 3D inpainting, establishing state-of-the-art performance against other NeRF manipulation algorithms, as well as a strong 2D image inpainter...
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[3DGS] 作者Bernhard Kerbl讲讲3DGS的历史、思考过程(感谢群友的投喂)
[文本转3D,群友工作] 南京大学提出AvatarBooth,新的文本或图片生成高质量3D Avatar的框架,拍摄的脸或身体照片即可生成,可支持二次编辑
MimicBrush 图片像素编辑,内容转移,纹理替换,Logo替换,轻轻一刷即可完成。
[NeRF进展,鲁棒的动态NeRF] RoDynRF CVPR最终presentation视频,联合预测静态、动态和相机姿态焦点信息,提升动态nerf鲁棒性
[Neural Rendering]Facebook Reality Lab提出AutoAvatar,推进神经场技术到真实人体动效生成领域(ECCV 2022)
[NeRF进展,使用事件相机生成高质量NeRF] 马克思普朗克研究院,萨尔大学提出EventNeRF,使用事件相机生成高质量NeRF,低功耗、低数据量、快速重建
2024最强 AI 集合!12个领域,47款AI工具,每一个都变态又好用!打工人必备!【建议收藏】
[NeRF进展,自动数据收集] INSA, UCBL, Meta提出AutoNeRF,一种不需要人工干预的自动agent,采集NeRF训练数据,协助完成下游任务
[NeRF进展]:LaTeRF,使用弱标记从图片中获得真实感3D物体表达(ECCV 2022)
[NeRF进展,交互编辑方向] Inria, 马克斯普郞克学院提出NerfShop,使用基于Cage变形的方法进行物体的交互式选择与编辑,进一步推动实用
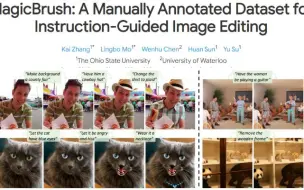
[数据集] 俄亥俄州立大学、滑铁卢大学:MagicBrush,一个人工标记的数据集,用来训练文本驱动的图片编辑,并精调instructPix2Pix验证了效果
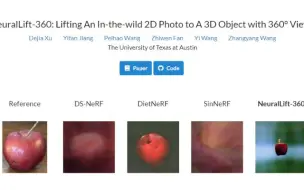
[NeRF进展,单图片成3D内容] 德克萨斯大学奥斯丁分校提出NeuralLift-360,使用单图生成3D物体
[NeRF+文本转3D] nVidia,多伦多大学Sanja团队:ATT3D,在一秒内使用文本生成3D的方法,极大提升了生成速度,并可完成简单的3D转换型动画
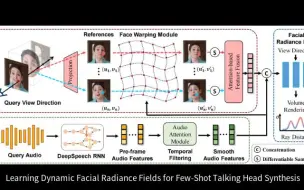
[NeRF进展,Talking Head应用] 清华大学、鉴智机器人提出DFRF,快速小样本生成高真实感、自然的讲话头,可用于数字人等(ECCV 2022)
[NeRF进展,人脸动画,褶皱渲染] 华沙工业大学、UBC、微软、Google等提出BlendFields,在少量数据下,结合图形学方法,生成细节表情动画
[NeRF进展,高质量快速训练、1080P实时渲染] INRIA,MPI等推出3D Gaussian Splatting,使用3D高斯表达场景和快速可见感知渲染
[Diffusion+SDF,三维重建] 港中文、上海AI实验室、浙大提出DiffRoom,基于occupancy先验重建TSDF,生成高质量3D室内重建效果
[NeRF+点云,点云渲染] 香港中文大学、思谋科技提出Point2Pix,使用NeRF将点云渲染为真实感图像的方法,并可完成点云inpainting和上采样
国内最好用AI工具TOP10,特别是最后两个,用好了直接开挂
[NeRF进展,点云重建] 捷克理工大学提出Tetra-NeRF,使用点云为输入,使用四面体和其德劳内表达进行重建,实现更好的重建性能和效果
[NeRF进展,快速非刚体NeRF数百倍提升]布伦瑞克工业大学,马克思普朗克计算研究所提出MoNeRF,将非刚体NeRF训练时间提升数百倍,渲染质量更好
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NeRF进展,大规模3DSRF数据集与合成模型]KAUST与慕尼黑工业大学Matthias团队提出SPARF数据集和SuRFNet,提升SRF渲染质量与性能
[NeRF, 复杂场景合成与控制] 香港中文大学、Snapchat、香港科技大学、浙大、UCLA等提出DisCoScene,在复杂场景上合成、编辑和操控物体
现在的 AI 技术太强了,尔康:太为难我了
[Transformer进展,用人体动作合成场景,可结合文本合成3D继续生成新效果?]斯坦福、丰田研究院提出SUMMON,使用人体动作反向生成合理有效的场景
[NeRF进展,TensoRF+PBR] 浙江大学、UCSD等提出TensoIR,将场景以神经场与密度、法向、光照、材质等信息一起建模,实现高质量建模
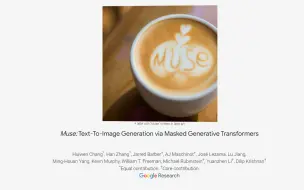
[Transformer进展,文本生成图片]GoogleAI提出Muse,首次使用Transformer代替Diffusion模型完成文本生成图片,速度快
[NVS和三维生成进展] 香港大学、腾讯等提出SyncDreamer,不使用SDS损失,使用单图生成多视角一致性图片,进而使用Neus和NeRF重建三维模型
[NeRF进展,单视角3D重建]香港大学、未来智联等联合推出S3-NeRF,挖掘Shading和Shadow信息提升单视角3D重建(NeurIPS 2022)
[NeRF进展,稀疏重建,开源, SIGGRAPH] 印度理工学院ViP-NeRF,用平面扫描volume获得可见先验正则化NeRF,完成稀疏视角NeRF重建
[NeRF进展,避免重建干扰,提升重建效果] Google研究院,多伦多大学,SFU提出RobustNeRF,在场景中有影响效果时,用优化算法达到更好的重建效果
[NeRF进展,严重相机pose错位重建,强于BARF] 西安交通大学、蚂蚁金服、腾讯AI Lab提出L2G-NeRF,使用局部-全局优化相机严重错位重建问题
[NeRF进展,Relighting方向] 浙江大学,MSRA等提出一种新的可重光照的NeRF的表达,通过向MLP提供多种hint,实现不同光照效果
[NeRF进展,模型任意转换]北航、旷视提出PVD,可以实现任意到任意的模型转化,训练一个NeRF,可以使用框架进行处理(AAAI 2023)
Nerf N-Series
[神经网络驱动3D建模] 特拉维夫大学、芝加哥大学、普渡大学提出GeoCode,一个人类可解释、可修改编辑的3D建模方法,提升对生成模型的操控力
[大佬讲paper第三期] 腾讯AI实验室胡文博大佬讲神经渲染中的Anti-Aliasing问题,以及SIG24中的新作Rip-NeRF等相关工作
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF