V
主页
[NeRF进展,大规模3DSRF数据集与合成模型]KAUST与慕尼黑工业大学Matthias团队提出SPARF数据集和SuRFNet,提升SRF渲染质量与性能
发布人
SPARF: Large-Scale Learning of 3D Sparse Radiance Fields from Few Input Images Abdullah Hamdi(阿卜杜拉国王科技大学, 慕尼黑工业大学) Bernard Ghanem(阿卜杜拉国王科技大学), Matthias Nießner(慕尼黑工业大学) 项目主页:https://abdullahamdi.com/sparf/ Github主页:https://github.com/ajhamdi/sparf_pytorch 最近在NeRF的进展将新视角生成问题处理为使用稀疏voxel的稀疏辐射场(SRF),这样来提升渲染的有效性和速度(如Plenoxels, InstantNGP等)。为了应用机器学习并应用SRF到3D表达中,我们提出了SPARF,一个大规模基于ShapeNet的合成数据集来生成新视角。它是由4万多个形状渲染出高分辨率(400x400像素)的17M图片组成的。这个数据集相比其他用来生成新视角合成数据集大几个数量级别,并且包含了超过百万的3D优化的多分辨率辐射场。另外,我们提出了一个新的算法(SuRFNet),它可以从几个视角生成稀疏voxel神经场。这是通过使用密采集的SPARF数据集和3D稀疏卷积实现的。SuRFNet使用从几个或单个图片构建的部分SRFs,和一个专用的SRF损失函数来学习生成高质量的稀疏voxel辐射场,这个辐射场可被用来渲染新的视角。相比于其他最近的baseline方法,我们的方法在无约束的新视角合成任务上在ShapeNet达到SOTA的效果。 Recent advances in Neural Radiance Fields (NeRFs) treat the problem of novel view synthesis as Sparse Radiance Field (SRF) optimization using sparse voxels for efficient and fast rendering (Plenoxels, InstantNGP). In order to leverage machine learning and adoption of SRFs as a 3D representation, we present _SPARF_, a large-scale ShapeNet-based synthetic dataset for novel view synthesis consisting of ~ 17 million images rendered from nearly 40,000 shapes at high resolution (400 X 400 pixels). The dataset is orders of magnitude larger than existing synthetic datasets for novel view synthesis and includes more than one million 3D-optimized radiance fields with multiple voxel resolutions. Furthermore, we propose a novel pipeline (_SuRFNet_) that learns to generate sparse voxel radiance fields from only few views. This is done by using the densely collected SPARF dataset and 3D sparse convolutions. SuRFNet employs partial SRFs from few/one images and a specialized SRF loss to learn to generate high-quality sparse voxel radiance fields that can be rendered from novel views. Our approach achieves state-of-the-art results in the task of unconstrained novel view synthesis based on few views on ShapeNet as compared to recent baselines.
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[NeRF进展,文本生成3D] Google,Ben、Jonathan提出DreamBooth3D,DreamBooth+DreamFusion,文本生成3D
[NeRF进展,人脸动画,褶皱渲染] 华沙工业大学、UBC、微软、Google等提出BlendFields,在少量数据下,结合图形学方法,生成细节表情动画
[Neural Rendering]Facebook Reality Lab提出AutoAvatar,推进神经场技术到真实人体动效生成领域(ECCV 2022)
[NeRF进展,高精度人头部动作生成] TUM提出NeRSemble,组合变形场和多分辨率3Dhash编码高精度生成人头运动。同时提供多视角高精度运动数据集
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[NeRF进展,街景重建方向] 复旦大学提出S-NeRF,将街景重建PSNR提升45%,可以兼顾大规模场景背景与前景移动车辆处理
[NeRF+文本转3D] nVidia,多伦多大学Sanja团队:ATT3D,在一秒内使用文本生成3D的方法,极大提升了生成速度,并可完成简单的3D转换型动画
[NeRF进展,时变3D模型] 浙大,康奈尔,特拉维夫提出neusc,使用网上地标照片,重建可独立控制视点、光照和时间的真实感时变三维模型
[NeRF进展,效果提升] TUM与Meta推出GANeRF,使用GAN来解决视角观察缺陷以及小的光照变化带来的重建质量不佳问题,提升1.4dB以上
[NeRF进展]:LaTeRF,使用弱标记从图片中获得真实感3D物体表达(ECCV 2022)
[NeRF, 复杂场景合成与控制] 香港中文大学、Snapchat、香港科技大学、浙大、UCLA等提出DisCoScene,在复杂场景上合成、编辑和操控物体
[群友工作] 上科大,Deemos等推出Media2Face,语音合成 3D 面部动画的新算法以及多型、多样化的扫描级别语音与3D协同数据集M2M-D
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
数字人SyncTalk数据集制作教程一键制作只需一个视频即可制作要求512分辨率
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影
[NeRF进展,多视角数据集,群友工作] 香港中文大学:MVImgNet和MVPNet,650万帧238类标记多视角数据集,近9万点云样本,桥接2D到3D视觉
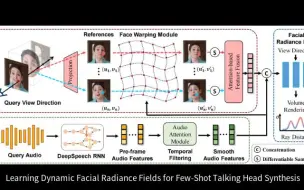
[NeRF进展,Talking Head应用] 清华大学、鉴智机器人提出DFRF,快速小样本生成高真实感、自然的讲话头,可用于数字人等(ECCV 2022)
[NeRF进展,鲁棒的动态NeRF] RoDynRF CVPR最终presentation视频,联合预测静态、动态和相机姿态焦点信息,提升动态nerf鲁棒性
[NeRF进展,实时渲染方向]格拉茨科技大学与Meta提出AdaNeRF,通过双网络模型自适应采样实现NeRF的实时渲染(ECCV 2022)
[NeRF进展,点云重建] 捷克理工大学提出Tetra-NeRF,使用点云为输入,使用四面体和其德劳内表达进行重建,实现更好的重建性能和效果
[NeRF进展] 香港中文大学提出双边滤波器引导的NeRF重构,可以消除相机拍摄变化引起的artifact,也可以进行3D风格化渲染
[NeRF进展,任意拓扑重建] 腾讯提出NeAT,另一个可用于重建衣物等任意拓扑的工作,NeuralUDF姊妹篇,计算量更低,效果的缺陷更小,代码开源(CVPR
[Generative AI进展]Adobe,特拉维夫大学,CMU提出一种使用已训练生成模型和目标概念,直接生成目标域内容的方法,可批量生成大量效果
[3DGS几何优化]上科大、图宾根大学提出2DGS,一种从多视图图像中建模和重建几何精确辐射场的新方法,解决3DGS几何一致性差的问题
[NeRF+点云,点云渲染] 香港中文大学、思谋科技提出Point2Pix,使用NeRF将点云渲染为真实感图像的方法,并可完成点云inpainting和上采样
[NeRF进展,稀疏视角+depth先验] 南洋理工大学ICCV提出SparseNeRF,利用现实世界不准确观测的深度先验来蒸馏深度排名,达到较好的重建效果
[GAN进展,真实感人图片生成] 3DHumanGAN,上海人工智能实验室与商汤提出3D-Aware的真实感人全身图片生成方法
[NeRF进展,镜头硬件参数校准] 康奈尔大学、Meta提出Neural Lens Modeling,在训练模型时同步优化相机参数,解决光学镜头参数校准问题
[NeRF进展,文本生成NeRF场景] 香港城市大学、腾讯提出Text2NeRF,一种由文本生成NeRF场景的方法,室内外生成效果都不错
[NeRF进展,单视角3D重建]香港大学、未来智联等联合推出S3-NeRF,挖掘Shading和Shadow信息提升单视角3D重建(NeurIPS 2022)
[3DGAN]浙江大学、香港理工和蚂蚁提出TeFF,无相机位姿3D感知GAN训练方法,在多个挑战的2D数据集上训练,生成样本可360度图像合成,并有完整几何形状
[文本转3D进展] 清华、人大等:ProlificDreamer,使用VSD解决过饱和、过平滑、低多样性问题,SDS是VSD的特殊情况,可应用在NeRF生成场景
[Transformer进展,用人体动作合成场景,可结合文本合成3D继续生成新效果?]斯坦福、丰田研究院提出SUMMON,使用人体动作反向生成合理有效的场景
[NeRF进展,单图重建] TUM, MCML和牛津大学提出BTS,一个密度场将输入图像的每个位置映射到体密度上,然后从图片采样颜色,可处理被遮挡区域
[NeRF进展,交互编辑方向] Inria, 马克斯普郞克学院提出NerfShop,使用基于Cage变形的方法进行物体的交互式选择与编辑,进一步推动实用
[AIGC&CG进展] 上海科技大学、Deemos提出DreamFace,仅通过文本控制生成个性化的3D人脸,并可以支持人脸老化、化妆或通过视频进行人脸动画控制
[大佬讲paper第三期] 腾讯AI实验室胡文博大佬讲神经渲染中的Anti-Aliasing问题,以及SIG24中的新作Rip-NeRF等相关工作
[3D表达进展]密西根大学提出Neural Shape Compiler,可以实现文本、点云和程序间统一的转换框架,在多种3D表达任务中达到提升