V
主页
[Transformer进展,人体运动表达模型] 北京大学、商汤等开源MotionBERT,通过构建空时域双流Transformer,从2D视频提取人体运动表达
发布人
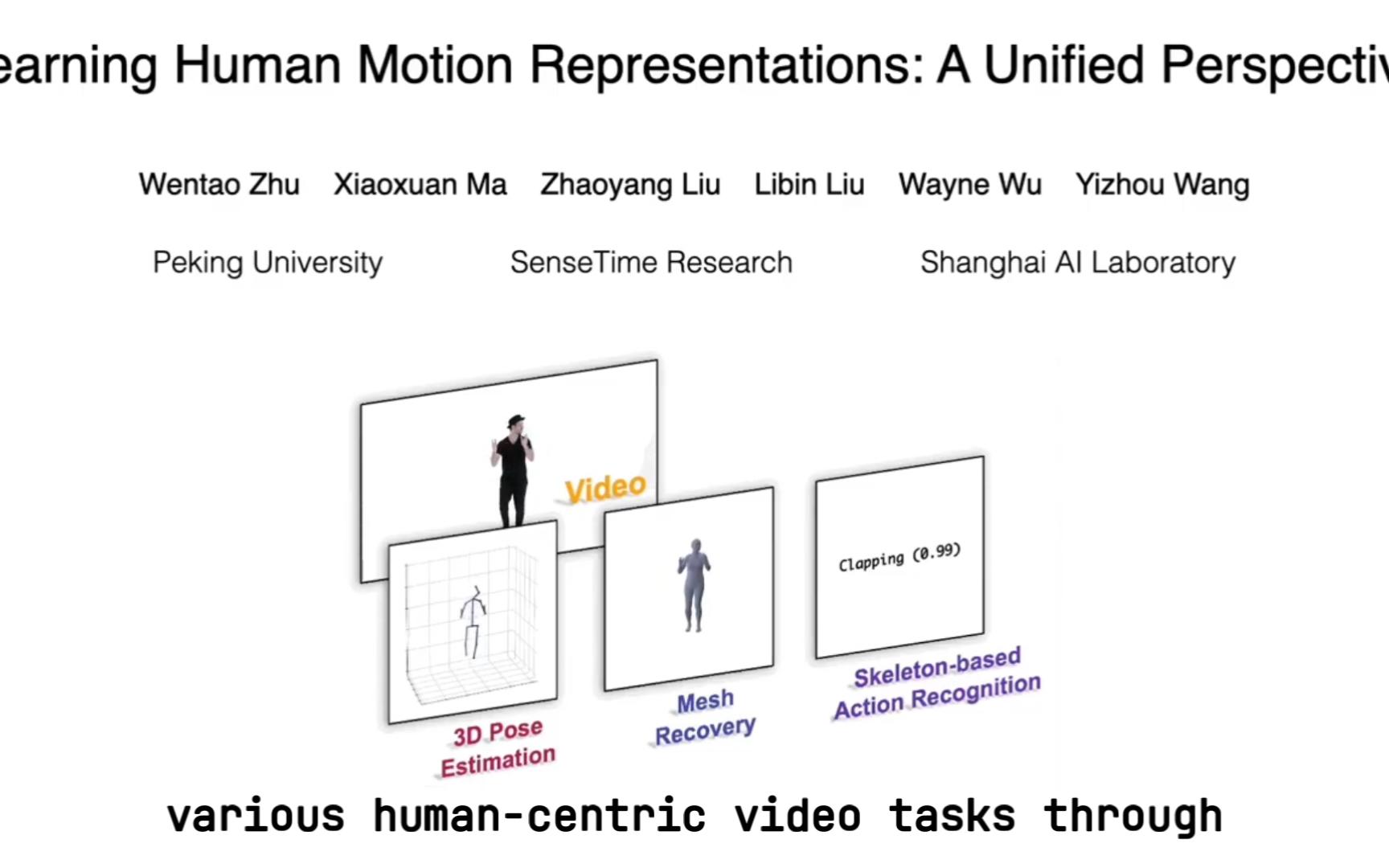
Learning Human Motion Representations: A Unified Perspective Wentao Zhu(北京大学), Xiaoxuan Ma(北京大学), Zhaoyang Liu(商汤研究院), Libin Liu(北京大学), Wayne Wu(商汤研究院,上海人工智能研究院), Yizhou Wang(北京大学) 项目主页:https://motionbert.github.io/ Github主页:https://github.com/Walter0807/MotionBERT We present a unified perspective on tackling various human-centric video tasks by learning human motion representations from large-scale and heterogeneous data resources. Specifically, we propose a pretraining stage in which a motion encoder is trained to recover the underlying 3D motion from noisy partial 2D observations. The motion representations acquired in this way incorporate geometric, kinematic, and physical knowledge about human motion, which can be easily transferred to multiple downstream tasks. We implement the motion encoder with a Dual-stream Spatio-temporal Transformer (DSTformer) neural network. It could capture long-range spatio-temporal relationships among the skeletal joints comprehensively and adaptively, exemplified by the lowest 3D pose estimation error so far when trained from scratch. Furthermore, our proposed framework achieves state-of-the-art performance on all three downstream tasks by simply finetuning the pretrained motion encoder with a simple regression head (1-2 layers), which demonstrates the versatility of the learned motion representations.
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[Neural Rendering]Facebook Reality Lab提出AutoAvatar,推进神经场技术到真实人体动效生成领域(ECCV 2022)
[NeRF进展,文本生成3D] Google,Ben、Jonathan提出DreamBooth3D,DreamBooth+DreamFusion,文本生成3D
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影
[AIGC&CG进展] 上海科技大学、Deemos提出DreamFace,仅通过文本控制生成个性化的3D人脸,并可以支持人脸老化、化妆或通过视频进行人脸动画控制
[NeRF进展,鲁棒的动态NeRF]Meta,台湾大学、KAIST、马里兰大学提出RoDynRF,联合预测静态、动态和相机姿态焦点信息提升鲁棒性
[NeRF进展,单图片成3D内容] 德克萨斯大学奥斯丁分校提出NeuralLift-360,使用单图生成3D物体
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[Diffusion生成点云,开源]OpenAI开源大招Point-E,通过文本生成3D point cloud的方法,快速有效地生成多样化复杂的3D模型
[NeRF进展,鲁棒的动态NeRF] RoDynRF CVPR最终presentation视频,联合预测静态、动态和相机姿态焦点信息,提升动态nerf鲁棒性
[NeRF进展,稀疏输入视角重建]CMU提出GBT,在稀疏图片输入的情况下,使用几何biased Transformer显著提升稀疏图片重建效果
[文本转3D,群友工作] 南京大学提出AvatarBooth,新的文本或图片生成高质量3D Avatar的框架,拍摄的脸或身体照片即可生成,可支持二次编辑
[Transformer进展,文本生成图片]GoogleAI提出Muse,首次使用Transformer代替Diffusion模型完成文本生成图片,速度快
[3DGS] 作者Bernhard Kerbl讲讲3DGS的历史、思考过程(感谢群友的投喂)
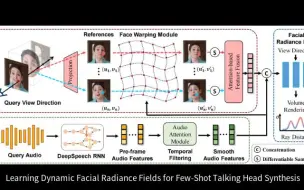
[NeRF进展,Talking Head应用] 清华大学、鉴智机器人提出DFRF,快速小样本生成高真实感、自然的讲话头,可用于数字人等(ECCV 2022)
[NeRF进展,快速人体动态NeRF建模] 浙江大学提出InstantNVR,速度提升100倍以上的快速人体动态NeRF建模方法,CVPR 2023已发布
[NeRF进展,大规模3DSRF数据集与合成模型]KAUST与慕尼黑工业大学Matthias团队提出SPARF数据集和SuRFNet,提升SRF渲染质量与性能
[Generative AI进展]Adobe,特拉维夫大学,CMU提出一种使用已训练生成模型和目标概念,直接生成目标域内容的方法,可批量生成大量效果
[NeRF进展,复杂场景编辑]斯坦福大学、Adobe提出PaletteNeRF,对复杂场景的外观属性进行后期编辑,NeRF向Adobe产品家族整合成为可能
[NeRF进展,稀疏视角重建] 斯坦福,Google, SFU提出SCADE,使用cIMLE和space carving方法,提升稀疏无约束室内NeRF重建效果
[点云进展,单图生成3D图片动画] 华中科技大学,Adobe,南洋理大学CVPR提出使用单图片生成3D图片动画的工作,提升图片内容表现力
终于找到了这个逐行解读代码的网站!全网近百万大学生研究生收藏!github标星超55.6k!----机器学习/深度学习/CV/NLP
[Diffusion+Transformer,人体动画进展] 阿里达摩院刚刚提出一个统一的预训练扩散模型MoFusion,用于人体动画合成 (arXiv)
[NeRF进展,自动数据收集] INSA, UCBL, Meta提出AutoNeRF,一种不需要人工干预的自动agent,采集NeRF训练数据,协助完成下游任务
[NeRF进展,点云重建] 捷克理工大学提出Tetra-NeRF,使用点云为输入,使用四面体和其德劳内表达进行重建,实现更好的重建性能和效果
[NeRF、Generative AI,文本或图片生成动态3D场景,过年期间看到最好的工作] Meta AI提出MAV3D,首个使用文本或图片生成动态3D场景
[NeRF进展,3D形状表达] KAUST和TUM发表3DShape2VecNet,面向扩散生成模型的形状神经场表达,对3D形状编码和生成及多个下游任务非常有效
[CLIP进展,3D内容理解与检索] 约翰霍普金斯大学提出CG3D,使用点云、2D图像和文字训练,使CLIP可提取3D几何特征时,ChatGPT 3D又一方案
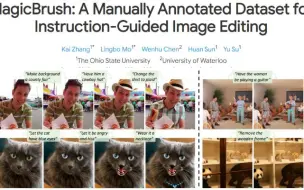
[数据集] 俄亥俄州立大学、滑铁卢大学:MagicBrush,一个人工标记的数据集,用来训练文本驱动的图片编辑,并精调instructPix2Pix验证了效果
[NeRF进展,稀疏重建,开源, SIGGRAPH] 印度理工学院ViP-NeRF,用平面扫描volume获得可见先验正则化NeRF,完成稀疏视角NeRF重建
[NeRF进展,快速非刚体NeRF数百倍提升]布伦瑞克工业大学,马克思普朗克计算研究所提出MoNeRF,将非刚体NeRF训练时间提升数百倍,渲染质量更好
[NeRF进展,移动实时渲染方向]Snapchat与东北大学联合推出MobileR2L,在移动设备上实时、低消耗、高质量地渲染NeRF三维场景,移动应用有突破
[NeRF进展,高质量快速训练、1080P实时渲染] INRIA,MPI等推出3D Gaussian Splatting,使用3D高斯表达场景和快速可见感知渲染
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
[NeRF,超高清渲染方向]阿里提出4K级别的超高清NeRF训练和渲染方法,在主观和客观质量评价下都取得了很好的效果
[点云+神经渲染进展] Apple, CMU, UBC提出Pointersect,给定一个点云,在不转换为其他表达的情况下,进行推理光线与表面相交性
[文本转3D进展] 清华、人大等:ProlificDreamer,使用VSD解决过饱和、过平滑、低多样性问题,SDS是VSD的特殊情况,可应用在NeRF生成场景
[NeRF进展,TensoRF+PBR] 浙江大学、UCSD等提出TensoIR,将场景以神经场与密度、法向、光照、材质等信息一起建模,实现高质量建模
[NeRF进展,模型任意转换]北航、旷视提出PVD,可以实现任意到任意的模型转化,训练一个NeRF,可以使用框架进行处理(AAAI 2023)
[NeRF+Mesh进展,城市场景建模] nVidia,多伦多大学等提出FEGR,结合Mesh,将复杂几何和材质与光照效果分离,实现真实感光照效果,以及场景操控