V
主页
[文本转3D进展] 清华、人大等:ProlificDreamer,使用VSD解决过饱和、过平滑、低多样性问题,SDS是VSD的特殊情况,可应用在NeRF生成场景
发布人
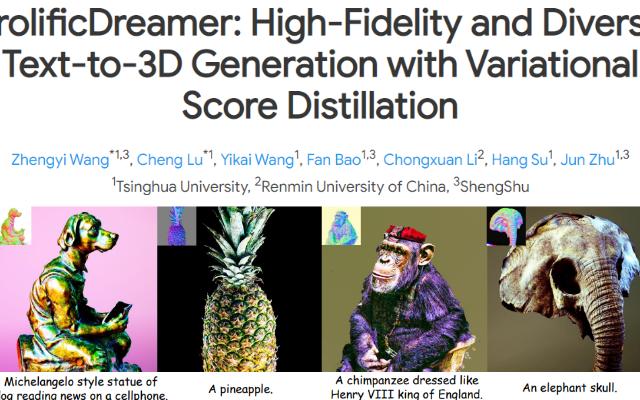
ProlificDreamer: High-Fidelity and Diverse Text-to-3D Generation with Variational Score Distillation Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, Jun Zhu 清华大学、人民大学、琶洲实验室 项目主页:https://ml.cs.tsinghua.edu.cn/prolificdreamer/ Score distillation sampling (SDS) has shown great promise in text-to-3D generation by distilling pretrained large-scale text-to-image diffusion models, but suffers from over-saturation, over-smoothing, and low-diversity problems. In this work, we propose to model the 3D parameter as a random variable instead of a constant as in SDS and present _variational score distillation_ (VSD), a principled particle-based variational framework to explain and address the aforementioned issues in text-to-3D generation. We show that SDS is a special case of VSD and leads to poor samples with both small and large CFG weights. In comparison, VSD works well with various CFG weights as ancestral sampling from diffusion models and simultaneously improves the diversity and sample quality with a common CFG weight (i.e., 7.5). We further present various improvements in the design space for text-to-3D such as distillation time schedule and density initialization, which are orthogonal to the distillation algorithm yet not well explored. Our overall approach, dubbed _ProlificDreamer_, can generate high rendering resolution (i.e., 512x512) and high-fidelity NeRF with rich structure and complex effects (e.g., smoke and drops). Further, initialized from NeRF, meshes fine-tuned by VSD are meticulously detailed and photo-realistic.
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF+Diffusion进展,图片生成3D] 上海交通大学,香港科技大学,微软提出MakeIt3D,使用Diffusion Prior将单图转为3D效果
[NeRF进展,TensoRF+PBR] 浙江大学、UCSD等提出TensoIR,将场景以神经场与密度、法向、光照、材质等信息一起建模,实现高质量建模
[NeRF进展,动态3D场景表达速度提升100倍] 密西根大学提出HexPlane,一种新的快速的3D动态场景表达方法
[NeRF进展,重着色方向]香港中文大学提是出RocolorNeRF,提取场景中的颜色层信息,在后期使用调色板对NeRF进行重新着色
[Generate AI进展,合成大规模无界3D场景] 南洋理工大学提出SceneDreamer,使用2D图片训练、使用随机噪声生成多样化无界3D场景
[NeRF进展,单图片生成多视角] Apple, UC圣迭戈分校,马普所,宾大发布NerfDiff,使用CDM+NeRF提高生成质量与效果
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
[NeRF进展,城市建模] 南洋理工大学:CityDreamer,一种unbounded 3D城市设计的组合生成模型,效果超过SceneDreamer
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[NeRF+Diffusion进展,少量视触目] Nitantic推出DIffusioNeRF,使用RGBD贴片训练的DDM模型,正则化few-shot重建过程
[NeRF进展,文本生成3D] Google,Ben、Jonathan提出DreamBooth3D,DreamBooth+DreamFusion,文本生成3D
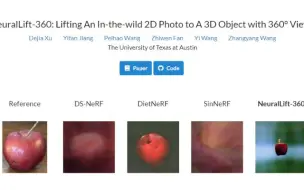
[NeRF进展,单图片成3D内容] 德克萨斯大学奥斯丁分校提出NeuralLift-360,使用单图生成3D物体
[NeRF+Diffusion进展,单图重建3D] 韩国首尔大学提出DITTO-NeRF,使用文字或单图,通过前视角部分3D+迭代扩散填充,生成3D模型
[NeRF进展,文本编辑NeRF] 创始大神Matthew+18岁大学生一作提出Instruct-NeRF2NeRF,使用文本指令进行3D场景的真实感编辑
[AIGC进展,使用shape+文本生成纹理] 特拉维夫大学提出TEXTure,通在已知3D shape情况下,使用文本可生成、编辑和迁移纹理效果
[Diffusion进展,文本生成360度体验] Intel提出LDM3D,使用文本生成RGBD图,并将RGBD图渲染为360度三维体验感内容
[3DGS进展] 浙大CADCG,字节提出可变形的3DGS方法,对单目动态场景进行建模,在渲染质量和速度取得优势,适合NVS问题,时间序列合成和实时渲染
[NeRF进展,实时建图] 中山大学、香港科技大学提出H2Mapping,第一个基于NeRF构建在可手持设备上运行的建图方法,效果优于NICE-SLAM
[AIGC&CG进展] 上海科技大学、Deemos提出DreamFace,仅通过文本控制生成个性化的3D人脸,并可以支持人脸老化、化妆或通过视频进行人脸动画控制
[NeRF进展,使用事件相机生成高质量NeRF] 马克思普朗克研究院,萨尔大学提出EventNeRF,使用事件相机生成高质量NeRF,低功耗、低数据量、快速重建
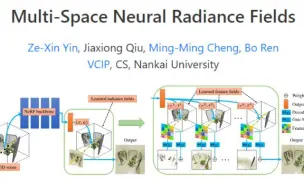
[NeRF进展,反射折射物体表达] 南开大学提出MS-NeRF,一种针对场景中反射和折射物体表达和渲染的方法,低消耗地提升NeRF模型,对相应场景效果提升显著
[NeRF进展,大型城市场景建模] 香港中文大学、浙江大学、马克斯普朗克等发布GridNeRF,高效建模大规模真实感城市3D场景
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NeRF进展] nVidia,多伦多大学提出Adaptive Shell的高效NeRF渲染方法,在体渲染和表面渲染方法之间平滑切换,可以高质量高速渲染NeRF
[NeRF进展,镜头硬件参数校准] 康奈尔大学、Meta提出Neural Lens Modeling,在训练模型时同步优化相机参数,解决光学镜头参数校准问题
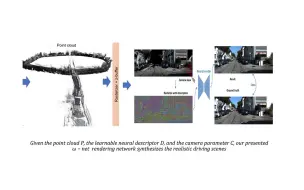
[NeRF+自动驾驶]浙江大学提出READ,使用神经渲染方法完成大尺度级别的街景场景渲染,合成、缝合、编辑真实感自动驾驶场景(AAAI 2023)
[扩散模型] 浙江大学群友SIGGRAPH 24:MaPa,一种使用文本生成三维网格材质的方法,支持高质量渲染和可编辑的灵活性
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
[NeRF, 复杂场景合成与控制] 香港中文大学、Snapchat、香港科技大学、浙大、UCLA等提出DisCoScene,在复杂场景上合成、编辑和操控物体
[Transformer进展] ViewFormer,基于codebook+transformer模型的视角生成方法(优于NeRF,ECCV 2022)
[NeRF进展,单目视频重建动态人-物-场景] 新加坡国立大学,腾讯等提出HOSNeRF,使用单目视频动态人-物-场景,LPIPS相比SOTA提升40%以上
[NeRF进展] 多伦多大学,SFU,Google和Adobe提出Bayers' Rays,在预训练的NeRF里预测不确定性,清除由不完整或遮挡造成的重建缺陷
[NeRF进展,单图实时3D画像] UCSD, nVidia,斯坦福提出LP3D,使用无姿态单图,实时推理和渲染真实感3D表达,合成高质量3D画像
[NeRF进展,避免重建干扰,提升重建效果] Google研究院,多伦多大学,SFU提出RobustNeRF,在场景中有影响效果时,用优化算法达到更好的重建效果
[AIGC视频生生]Google等提出Lumiere,使用时空U-Net,单次传递,一次性生成视频完整时间,实现高质量文本转视频、图像转视频、视频修复、风格化等
[NeRF进展,物体相机] MIT与莱斯大学脑洞大开:ORCa,将有光泽的物体转为神经场相机,将反光的不可见场景建模,可以看到物体看到的而不是相机看到的场景
[NeRF进展] MPI提出NeuralClothSim,一种使用Kirchhoff-Love布料模拟方法,将表面变化过程编码到神经网络中,实现更好的模拟效果
[NeRF进展,高精度人头部动作生成] TUM提出NeRSemble,组合变形场和多分辨率3Dhash编码高精度生成人头运动。同时提供多视角高精度运动数据集
[NeRF进展,实时渲染方向,四创始大神新作,必看!] Google Research、蒂宾根大学发布MERF,低内存实时NERF渲染,优于InstantNGP
[NeRF进展,Avatar实时生成] 苏黎世I联邦理工,普朗克研究所提出InstantAvatar,相比SOTA方法速度提升130倍以上,秒级别训练,实时渲染