V
主页
20220629【比物连类:对比表示学习】宫明明:CRIS: CLIP-Driven Referring Image Segmentation
发布人
报告嘉宾:宫明明 (墨尔本大学) 报告时间:2022年06月29日 (星期三)晚上20:00 (北京时间) 报告题目:CRIS: CLIP-Driven Referring Image Segmentation 报告人简介: Mingming Gong is a lecturer and PhD supervisor at the School of Mathematics and Statistics, University of Melbourne, Australia, and a principal investigator at the Melbourne Centre for Data Science. He received his PhD from the University of Technology Sydney in 2017 and then did postdoctoral research at the University of Pittsburgh and Carnegie Mellon University. His research interests include causal machine learning, weakly supervised/ self-supervised learning, transfer learning, generative models, and 3D vision. He has published more than 50 papers in top conferences and journals related to artificial intelligence, such as NeurIPS, ICML, and CVPR. He is a recipient of the Australian Research Council Discovery Early Career Award in 2021. He is area chairs of top machine learning conferences such as NeurIPS, ICML, and ICLR. 个人主页: https://mingming-gong.github.io/ 报告摘要: Referring image segmentation aims to segment a referent via a natural linguistic expression. Due to the distinct data properties between text and image, it is challenging for a network to well align text and pixel-level features. Existing approaches use pretrained models to facilitate learning, yet separately transfer the language/ vision knowledge from pretrained models, ignoring the multi-modal corresponding information. Inspired by the recent advance in Contrastive Language-Image Pretraining (CLIP), in this paper, we propose an end-to-end CLIP-Driven Referring Image Segmentation framework (CRIS). To transfer the multi-modal knowledge effectively, CRIS resorts to vision-language decoding and contrastive learning for achieving the text-to-pixel alignment. More specifically, we design a vision-language decoder to propagate fine-grained semantic information from textual representations to each pixel-level activation, which promotes consistency between the two modalities.
打开封面
下载高清视频
观看高清视频
视频下载器
20220629【比物连类:对比表示学习】苏冰:What to contrast?
20220309【让机器看懂视频:视频分割与目标追踪】杨宗鑫:视频理解中的多目标联合分割
20220615【AI for Science之物理信息驱动的深度学习】王建勋:Leveraging physics-induced bias in……
20220629【比物连类:对比表示学习】Panel
20221012【自监督表示学习及其应用】陈小军:Self-supervised Image Clustering
20211229【基于神经表示的三维建模与渲染】顾佳涛:Neural Implicit Representation and Rendering
20220831【就正有道:物理机理驱动的图像恢复与增强】任文琦:融合先验知识的图像视频复原方法研究
20220323【我要找到你:2D/3D物体检测和定位】Panel
20240605【Prompt Learning in Vision】陈广义:Prompt Learning Meets Dense Context for …
【VALSE论文速览-80期】Exploring Cross-Image Pixel Contrast for Semantic Segmentation
【VLASE论文速览-79期】Rethinking Semantic Segmentation: A Prototype View
20220316【基于领域知识的机器学习在医学影像分析中的应用】崔智铭:Shape-aware tooth segmentation in digital……
20220413【脑启发视觉】Panel
20221012【自监督表示学习及其应用】Panel
20211222【自动驾驶中的机器视觉与学习问题】赵行:环视自动驾驶感知
20220420【点云场景理解】弋力:面向交互的四维动态场景理解
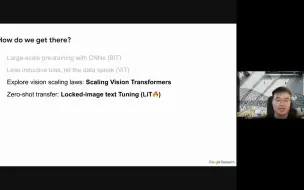
20220602智源大会视觉模型论坛-谷歌大脑翟晓华博士报告【大规模通用视觉表征学习】
20230322【大规模预训练模型的可信性】Chaowei Xiao:Towards Socially Responsible machine learning
20220112【脉络分明:脉冲神经网络及其应用】余肇飞:脉冲神经网络学习理论与方法
20220713【超级视觉深度学习模型与标签学习方法】张敬:ViTAE Transformer 超级视觉深度学习模型
20210324【图像视频分割】沈春华 Instance Segmentation Made Simple
20220316【基于领域知识的机器学习在医学影像分析中的应用】Panel
20211229【基于神经表示的三维建模与渲染】Panel
20220113 VALSE Student Webinar【论文写作那些事儿】王玫:科研路上的心得与体会
20220105【标签噪声学习专题论坛】彭玺:噪声关联学习:一种新的噪声标注学习范式
20220420【点云场景理解】赵恒爽:Scene Understanding in 3D and 2D-3D
20230607【开放世界的感知:探索可迁移与可持续学习之路】巩东:Continual Learning and Memory Augmentation……
20220914【视频理解研究进展与未来】Panel
20230322【大规模预训练模型的可信性】Panel
20220615【AI for Science之物理信息驱动的深度学习】Panel
20200731-Valse Student Seminar 张士峰《Bridging the Gap Between Anchor-based and...》
20240814【多模态医学图像处理及医学大模型的发展近况】王连生:病理数据的多模态分析
20210609【领域自适应方法与进展】Dengxin Dai:Domain Adaptation for Real-world Domain Changes
20220914【视频理解研究进展与未来】吴祖煊:基于Transformer的视频内容理解
20220406【“热门中的冷门”-实用深度学习优化方法】刘日升:基于梯度的双层优化方法初探
【VALSE论文速览-81期】Deep Rectangling for Image Stitching: A Learning Baseline
【VALSE论文速览-68期】MixFormer:更加简洁的端到端单目标跟踪器
【VALSE论文速览-47期】Towards Scalable Unpaired Virtual Try-On via Patch-Routed……
20210818【心中的象牙塔:怎样才能拿到理想的教职offer?】刘希慧:博士阶段的经历和感悟分享
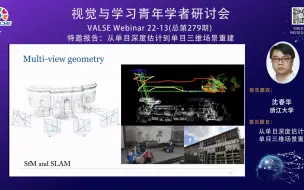
20220601特邀报告【从单目深度估计到单目三维场景重建】沈春华 (浙江大学)