V
主页
39页视觉问答(VQA)和视觉推理综述论文来了!涉及近30个数据集,50多种经典方法,VQA终于学会了!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
阿里发布最强中文图文多模态模型:Chinese CLIP,基于两亿中文图文多模态数据!
仅需0.5M!可集成任意扩散模型!字节提出灵活分辨率适配器ResAdapter!
三个超变态的AI网站,能提前让你过上退休生活!!!
炸裂:上海保姆机器人要上岗!人工智能机器人
给多模态加Buffer,GNN在视觉语言下游任务的应用综述来了!包含125篇相关论文,涉及Image Captioning,VQA,Retrieval三大方向!
AI可解释性综述来了,神经网络的黑盒性质经常被许多学者Diss,而可解释性方法让AI不在是完全黑盒!
黄仁勋 下一波AI是物理人工智能,它需要......来实现 !人工智能技术
未来20年将改变世界的20大新科技:通用人工智能(AGI)、基因编辑、量子计算、脑机接口、人形机器人、生成式AI、人造子宫、纳米技术、物联网
当医学图像遇上SAM,会产生什么样的火花,基于SAM的医学图像分割finetune框架来了,附代码!
世界不再有长期,因为五年后的世界将大变样!人工智能
震惊:人工智能医院和人工智能医生来了!
9位Science院士联名发表人工智能发展长篇综述,涵盖了智能计算的基础理论,智能计算融合的重要应用和挑战!
中山大学学者提出新的视觉Transfomer结构DilateFormer,减少70%计算量的同时性能更优!目前已开源!
NVIDIA放大招了!在生成模型基础上提出Action-GPT:利用GPT实现任意文本生成动作!效果绝了!
鹏城实验室开放了45页多模态预训练大模型综述!总结了近5年多模态预训练相关的算法和数据!多模态预训练学习包!
清华顶级学霸|拉斯特炫神教你如何读论文,学会后一晚上读50篇论文!
文本引导的虚拟试衣来了,多模态在时尚领域的又一杀器!一键更换模特服装!目前代码模型已开源!
AI模型的大一统!微软多模态组提出了多模态领域杀疯了的多边形战士BEIT V3!多项视觉,多模态任务达到SOTA!
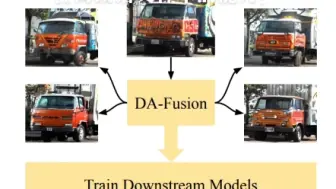
Diffusion Model 可以用来进行图像数据增强了!卡内基梅隆大学学者提出DA-Fusion方法,提升了数据增强产生多样性高级语义样本的能力!
幻方发布超强多模态LLM DeepSeek-VL!支持代码,文档OCR等!
NEURA 与 NVIDIA 携手重新定义机器人技术的未来!
“AI读心术”来了,日本学者基于Stable Diffusion模型提出了一个大脑视觉信号重建图像的研究,效果惊人!目前已被CVPR 2023接收!
当AI进入医学,会有多少人失业?LLaVA-Med为何性能这么好?
30个AI工具提效神器我给你找全了
Kaiming He团队在多模态领域提出的FLIP,结合MAE Masking Image 策略与CLIP,保证精度的同时 大幅提升训练效率!
新年大礼包,图像分割领域近230页综述开源了!涵盖图像语义分割,实例分割以及3D视频分割等多种场景,涵盖了近百种经典算法,30多个开源数据集!
花了一周时间整理的多模态领域经典必读论文30篇,赶紧点赞收藏!
开源MixTeX重大更新,干翻mathpix!!
CVPR 2023,EVA升级,智源开源更强的视觉预训练模型EVA-2,Vit-L Imagenet精度达到90+!
GPT4o-mini:为什么模型越做越小
最新用于医疗图像的Difussion模型大综述,涵盖155篇相关论文,从2021到最近的所有Difussion方法均有涉及!
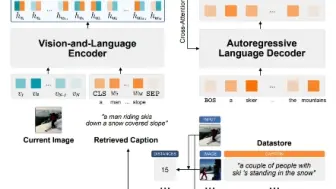
里斯本大学学者提出检索增强的Image Captioning 方法,可以在预训练图文编码器的基础上进一步提升Caption性能!
LLama3.1:Meta给了李彦宏一记耳光
最全的30页Loss函数总结综述来了,包含30多种损失函数,涉及分类,回归,Ranking等!
见识一下ChatGPT-4o强大的识图能力!细节不但拉满,还能对图片进行分析并打分!
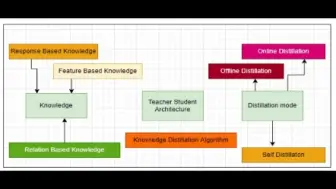
如何蒸馏小模型?28页知识蒸馏综述来了,涉及近30蒸馏方案,需要的同学快来领取!
OpenAI绝密文件泄露:2027年实现AGI,人工智能觉醒即将到来
继EMO之后又火了!阿里提出Image-to-Video新框架AtomoVideo!
谷歌基于多模态预训练模型,提出了一种开放词汇的时序动作检测模型,可以检测视频中任意动作!性能远超之前方法!
多模态还能助力NLP任务!上交学者提出TILT方法,利用多模态检索图像增强文本表征,多项NLP下游任务达到SOTA!