V
主页
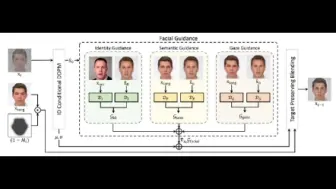
阿里发布最强中文图文多模态模型:Chinese CLIP,基于两亿中文图文多模态数据!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
基于Diffusion模型的DiffFace来了,交换效果超过之前的经典模型!代码和模型即将开源!
CLIP可以直接拿来做文本检测了!腾讯优图提出TCM结构,文本检测能力在多个数据集上均有较大提升!目前以被CVPR2023接收!
文本引导的虚拟试衣来了,多模态在时尚领域的又一杀器!一键更换模特服装!目前代码模型已开源!
上交学者提出了一种利用Diffusion模型生合成语义分割数据集,并基于此训练了一个开放词汇分割的模型,效果惊艳!
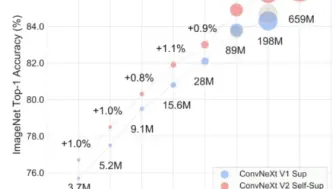
最强视觉backbone网络ConvNext v2来了!Meta AI融合了视觉掩码自监督框架,提出新的新的SOTA算法!目前代码和模型已开源!
原来AI真的能生成高颜值美女,快来试试多模态生成模型吧!
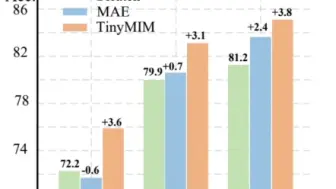
微软亚研提出了小模型蒸馏方法TinyMIM!MIM预训练小模型性能提升4个百分点!目前模型和代码均已开源!
刷爆视频音频Zero-Shot榜单!北大提出LanguageBind!
LLaVA+SEEM+GLIGEN,微软提出多模态交互原型Demo LLaVA-Interactive!
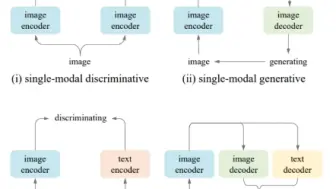
微软学者整理了100页图文多模态预训练综述,涉及各种多模态模型和应用,并且附带视频教程,需要的同学快来领取!
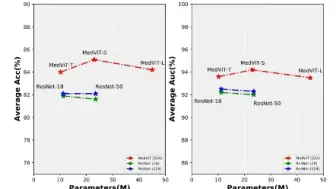
伊朗科技大学学者提出用于医学图像识别的骨干网络MedViT,融合了CNN和Transformer的结构,在多项医学图像任务取得不错效果!
Mamba再下一城!上海AI Lab提出视频领域新SOTA VideoMamba!
腾讯联合新国立提出了一种one-shot文本生成视频的方法!效果超过CogVideo!代码和模型即将开源!
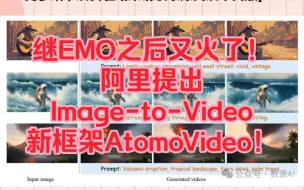
继EMO之后又火了!阿里提出Image-to-Video新框架AtomoVideo!
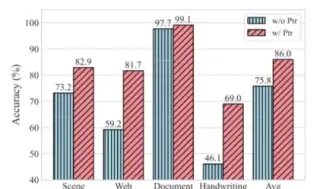
阿里多模态团队基于OFA多模态预训练模型,提出最强中文OCR模型,效果惊艳!
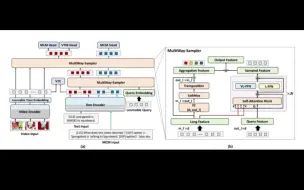
阿里提出用于视频文本理解的高效多模态模型MuLTI,通过设计了Multiway Sampler和多项选择建模任务 在多项视频理解任务上达到新SOTA!
多模态还能助力NLP任务!上交学者提出TILT方法,利用多模态检索图像增强文本表征,多项NLP下游任务达到SOTA!
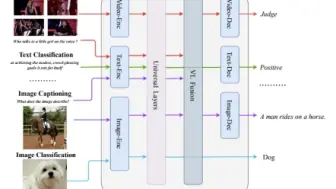
阿里达摩院提出了新的多边形战士模型mPLUG-2,在各种视觉,文本以及多模态任务上均取得不错的性能,超过BEIT V3和EVA!
微软联合北大提出了首个用于音视频联合生成的多模态扩散模型MM-Difussion!可以给定视频生成音频或给定音频生成视频!
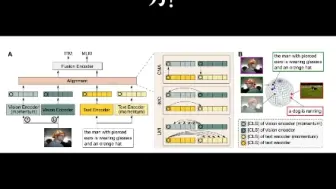
亚马逊学者提出了既能看又能读的多模态场景理解模型,支持传统的VQA以及文本VQA!
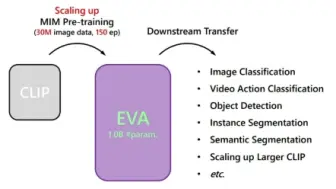
北京智源多模态团队提出EVA:多模态助力视觉自监督预训练,加入掩码,视觉表征学习更上一层楼!目前代码和模型已开源!
超越所有YOLO检测模型,mmdet开源当今最强最快的目标检测器RTMDet!
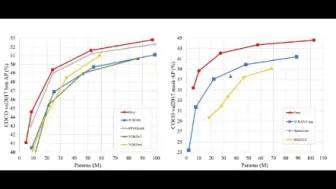
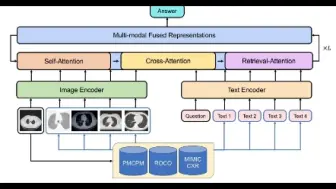
阿里联合清华提出了用于医学VQA的新方法RAMM,利用检索增强的策略在医学VQA数据集上取得新SOTA!数据集,代码即将开源!
[理解和生成]的大一统,微软提出BLIP多模态模型,取得下游多项任务SOTA!
54亿视觉注释数据集FLD-5B横扫CV各种任务!微软提出视觉基础模型Florence-2!
真正的万物检测模型,谷歌提出基于VisionTransformer的开放词汇目标检测器
斯坦福学者提出ControlNet,通过对Stable Diffussion生成结果进行控制,即将补完AIGC工业化的最后一块拼图!
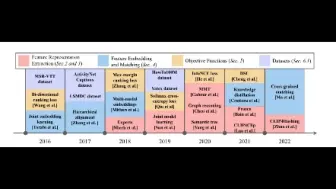
基于深度学习的视频文本的跨模态检索30页综述来了,包含近7年150篇相关论文!
微软提出了一种图像分割,视觉语言大一统模型X-Decoder!open-vocabulary语义分割效果惊艳!多项下游任务性能表现SOTA,目前代码和模型已开源
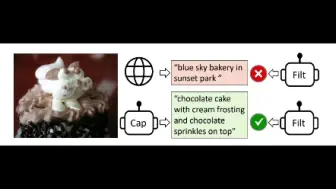
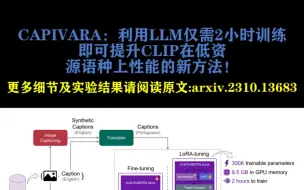
CAPIVARA:利用LLM仅需2小时训练即可提升CLIP在低资源语种上性能的新方法!
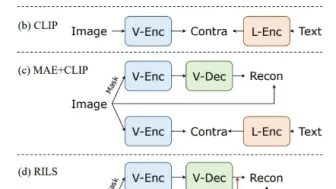
腾讯结合了MAE和CLIP,提出了新的在语言语义上进行掩码重建的预训练框架RILS,超过多种视觉预训练和多模态预训练方案!
CVPR2023发表,LayoutDiffusion:用于Layout控制图像生成的新方法,比之前方法取得了更好的生成质量和更多的可控制性!
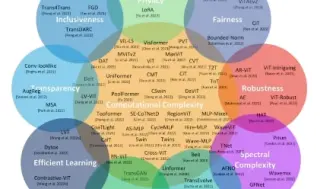
微软总结了视觉Transformer的分类性能,从参数量,计算量等方面对它们进了公平的对比!
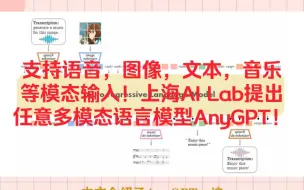
支持语音,图像,文本,音乐等模态输入!上海AI Lab提出任意多模态语言模型AnyGPT!
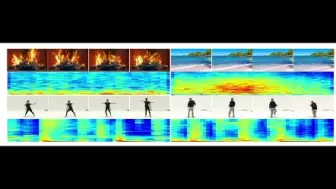
Adobe研究院提出了用于视频和音频多模态数据的视听对比学习的自监督策略,在多项视频和音频数据集上达到新SOTA!
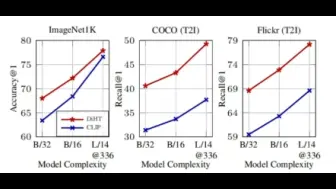
Meta AI提出新的多模态预训练pipeline DiHT,使用更少数据超过CLIP,FILIP等模型!
亚马逊联合牛津提出了用于多模态理解的三元对比学习TCL,在CLIP的基础上提升了多模态模型的跨模态理解能力!
CMU《多模态机器学习|CMU Multimodal Machine Learning, Fall 2023》中英字幕
字节联合爱丁堡大学提出新的视觉预训练方法MUG,取得新的SOTA!模型和代码均已开源,快来领取!
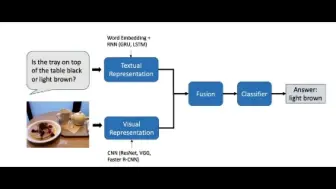
39页视觉问答(VQA)和视觉推理综述论文来了!涉及近30个数据集,50多种经典方法,VQA终于学会了!