V
主页
Diffusion Model 可以用来进行图像数据增强了!卡内基梅隆大学学者提出DA-Fusion方法,提升了数据增强产生多样性高级语义样本的能力!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
自从用了Cursor,程序员再也不怕失业了?
“AI读心术”来了,日本学者基于Stable Diffusion模型提出了一个大脑视觉信号重建图像的研究,效果惊人!目前已被CVPR 2023接收!
AI可解释性综述来了,神经网络的黑盒性质经常被许多学者Diss,而可解释性方法让AI不在是完全黑盒!
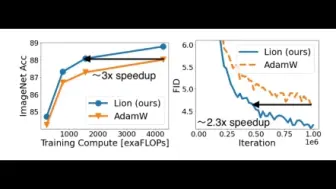
最强优化器来了!谷歌提出适用于多种任务的新型优化器Lion,在多项任务上以更快的训练速度取得更好的性能!目前已开源!
B站水友开发的免费ChatGPT账号共享站,打开即用
中山大学学者提出新的视觉Transfomer结构DilateFormer,减少70%计算量的同时性能更优!目前已开源!
上海交大学者提出了第一个用于医学图像诊断的多模态ChatGPT模型,在各种医学诊断任务上取得SOTA!
草履虫都能学会!这可能是B站最全的(Python+机器学习+深度学习)系列课程了,入门巨简单学不会你打我!机器学习/深度学习/人工智能/python学习
谷歌学者提出了简单的DPN策略,在ViT 的Patch Embedding层前后各加一个LN层就能提升ViT性能!
阿里发布最强中文图文多模态模型:Chinese CLIP,基于两亿中文图文多模态数据!
旷视科技&电子科大&港中文&港科技联合开源,首个探索室内3D点云配准真实数据生成的方法
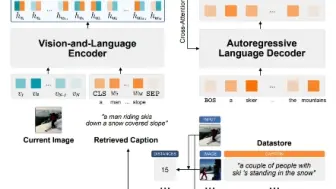
里斯本大学学者提出检索增强的Image Captioning 方法,可以在预训练图文编码器的基础上进一步提升Caption性能!
【论文分享】CellMix 即插即用的在线数据增强 for 病理学深度学习
微软总结了视觉Transformer的分类性能,从参数量,计算量等方面对它们进了公平的对比!
[转载]基于FPGA的YOLO算法从入门到精通
前谷歌CEO爆猛料,这些话是我们能听的?
上海AI Lab提出利用多种预训练模型进行集成学习的新方法CaFo,利用 GPT-3,CLIP,DINO等多种基础预训练模型提升少样本学习能力!
全新的全卷积视觉骨干网FCViT,超过ConvNext,目前已开源!
NVIDIA放大招了!在生成模型基础上提出Action-GPT:利用GPT实现任意文本生成动作!效果绝了!
外网爆火的大模型黑书!基于GPT-3、ChatGPT、GPT-4等 Transformer 架构的自然语言处理
CVPR 2023,EVA升级,智源开源更强的视觉预训练模型EVA-2,Vit-L Imagenet精度达到90+!
北大联合华为诺亚提出了一种增强对比学习的新方法ArCL,通过学习更鲁棒的特征,将MOCO等对比学习方法提升1-2个百分点!目前已被ICLR 2023接收!
AI模型的大一统!微软多模态组提出了多模态领域杀疯了的多边形战士BEIT V3!多项视觉,多模态任务达到SOTA!
CLIP助力跨域目标检测,来自EVEN CVLab的学者提出语义增强策略,提升效果明显
Self-Attenion的重思考,VIT更快的同时性能更强,Skip Attention通过减少注意力来提升VIT性能!
鹏城实验室学者提出了一种新的视频语言多模态预训练模型SOTA-VLP,融合了空间时序建模方法,捕获细粒度特征,多项任务取得SOTA!
开发torchinfo的人真是个天才,能把模型的每一层类型、输出形状和参数量等清晰的展示出来!
腾讯联合浙大提出新的视觉Transformer网络CrossFormer,参数量更少同时性能超过Swin!目前已开源!
韩国N号房2.0事件大爆发,大量女性被AI换脸
【中英+笔记】对话《人类简史》作者尤瓦尔·赫拉利:人工智能将在2034年控制你|2024.09.05
Transformer能否像MobileNets一样快?加州伯克利学者提出Efficient former V2,速度和精度超过之前轻量模型!
【劝退】自学StableDiffusion能救一个是一个!这里面的水可深了!人工智能大佬专为零基础研制的StableDiffusion教学教程,太牛了!AI绘图
【Stable Diffusion】用AI做网红美女❗涨粉实在太快了,直接赚大发了【喂饭级教程】一看就会,月涨粉10w,任何人错过这个我都会伤心(附工具)
35年首次证明!神经网络登上Nature:神经网络具有人类泛化能力,是人工智能的又一重大突破!
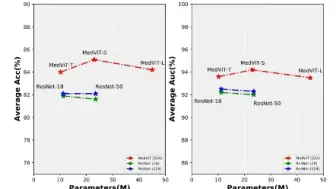
伊朗科技大学学者提出用于医学图像识别的骨干网络MedViT,融合了CNN和Transformer的结构,在多项医学图像任务取得不错效果!
【200集全】CV十天入门到起飞!一口气学完Python、OpenCV、深度学习基础、PyTorch、卷积神经网络、物体检测、图像分割等计算机视觉必备基础与实战
54亿视觉注释数据集FLD-5B横扫CV各种任务!微软提出视觉基础模型Florence-2!
斯坦福学者提出ControlNet,通过对Stable Diffussion生成结果进行控制,即将补完AIGC工业化的最后一块拼图!
最全的30页Loss函数总结综述来了,包含30多种损失函数,涉及分类,回归,Ranking等!
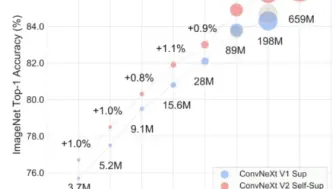
最强视觉backbone网络ConvNext v2来了!Meta AI融合了视觉掩码自监督框架,提出新的新的SOTA算法!目前代码和模型已开源!