V
主页
【chatglm】(9):使用fastchat和vllm部署chatlgm3-6b模型,并简单的进行速度测试对比。vllm确实速度更快些。
发布人
【chatglm】(9):使用fastchat和vllm部署chatlgm3-6b模型,并简单的进行速度测试对比。vllm确实速度更快些。
打开封面
下载高清视频
观看高清视频
视频下载器
ChatGLM+Langchain构建本地知识库,只需6G显存,支持实时上传文档
Llama3-70b 大模型用vllm去启动的细微注意事项
如何使用chatglm3+fastgpt做自己的知识库
vllm on ray实现多机推理
手把手教学!使用 vLLM 快速部署 Yi-34B-Chat
通义千问-大模型vLLM推理与原理
如何选择LLM本机推理,部署工具?看看LLM的推荐和统计数据吧
简单fastchat思维导图
【超详细】纯本地部署的FastGPT知识库教程(基于ChatGLM3+m3e+oneapi)
双显卡部署 Yi-34B 大模型 - vLLM + Gradio 踩坑记录
vLLm: 大模型LLM快速推理的神器, llama2秒级完成推理不用再等待
探索开源FastChat 平台,揭秘基于LLM大型语言模型的智能化应用框架!
4060Ti 16G显卡运行chatglm3-6b-32k模型效果
ChatGLM3-6B 对比 Qwen-14B,到底谁更强?
【chatglm3】(7):大模型训练利器,使用LLaMa-Factory开源项目,对ChatGLM3进行训练,特别方便,支持多个模型,非常方方便
FastChat新版本发布整合vLLM,让大模型推理能力提升10倍
大模型并发加速部署 解析当前应用较广的几种并发加速部署方案!
只需 24G 显存,用 vllm 跑起来 Yi-34B 中英双语大模型
【deepseek】(3):经过我的认真反思,终于把DeepSeeK-Coder-6.7B给运行起来了,使用A40显卡运行速度挺快的。
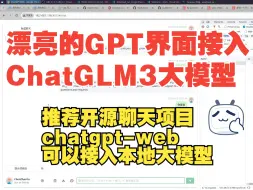
【chatglm3】(10):使用fastchat本地部署chatlgm3-6b模型,并配合chatgpt-web的漂亮界面做展示,调用成功,vue的开源项目
vllm-gptq 实现 Qwen 量化模型的加速推理
一句话生成BI图表(Chat2BI、ChatGLM3、function call+code interpreter)
终于弄明白FastChat服务了,本地部署ChatGLM3,BEG模型,可部署聊天接口,web展示和Embedding服务!
DeepSpeed-FastGen比vLLM推理性能快2倍,SplitFuse策略 #小工蚁
VLLM ——高效GPU训练框架
【chatglm3】(8):模型执行速度优化,在4090上使用fastllm框架,运行ChatGLM3-6B模型,速度1.1w tokens/s,真的超级快。
通义千问模型运行FastChat 发现兼容性问题
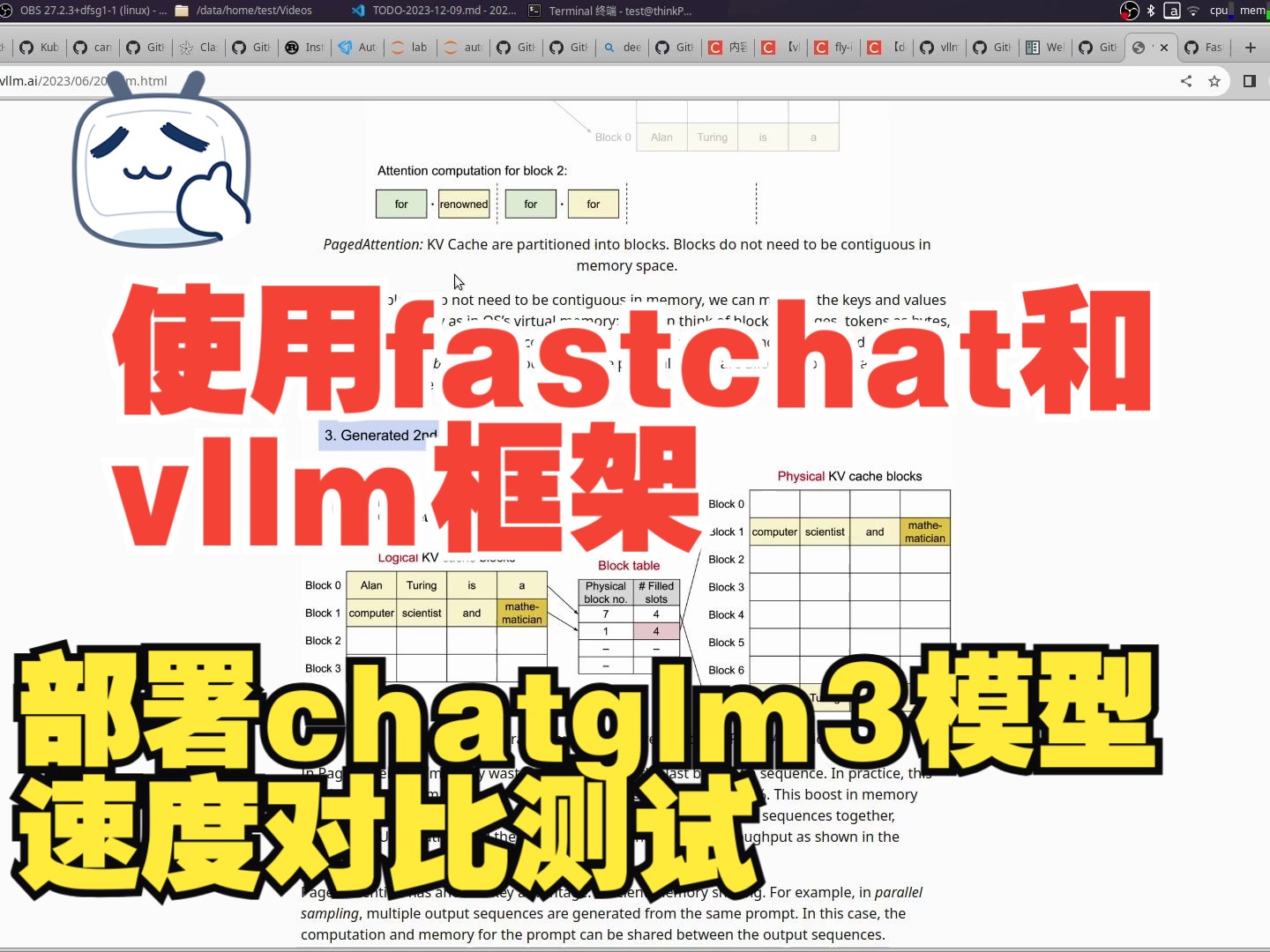
PagedAttention(vLLM):更快地推理你的GPT【论文粗读·7】
使用autodl服务器,两个3090显卡上运行, Yi-34B-Chat-int4模型,用vllm优化,增加 --num-gpu 2,速度23 words/s
【chatglm3】(4):如何设计一个知识库问答系统,参考智谱AI的知识库系统,学习设计理念,开源组件
单卡2080Ti跑通义千问32B大模型(ollama和vllm推理框架)
在AutoDL上,使用4090显卡,部署ChatGLM3API服务,并微调AdvertiseGen数据集,完成微调并测试成功!
阿里通义千问Qwen-7b如何运行在FastChat生产环境?
掌握FastChat RESTful API和SDK打造独一无二的人工智能应用 #小工蚁 #fastchat #2openai
用 llama.cpp 跑通 mixtral MoE 模型
VLLM 测试 Mixtral MoE 的 GPTQ 量化版本
【大模型知识库】(2):开源大模型+知识库方案,docker-compose部署本地知识库和大模型,毕昇+fastchat的ChatGLM3,BGE-zh模型
LightLLM轻量级高性能推理框架 和vLLM哪个更强?
【大模型知识库】(3):本地环境运行flowise+fastchat的ChatGLM3模型,通过拖拽/配置方式实现大模型编程,可以使用completions接口
【Dify知识库】(1):本地环境运行dity+fastchat的ChatGLM3模型,可以使用chat/completions接口调用chatglm3模型