V
主页
PagedAttention(vLLM):更快地推理你的GPT【论文粗读·7】
发布人
合集文档:https://bytedance.feishu.cn/docx/doxcn3zm448MK9sK6pHuPsqtH8f PagedAttention:https://readpaper.feishu.cn/docx/EcZxdsf4uozCoixdU3NcW03snwV
打开封面
下载高清视频
观看高清视频
视频下载器
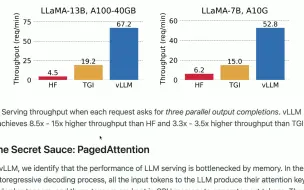
1.2 PagedAttention VLLM核心思想 原理 推理框架 Efficient Memory Management for Large Langua
1.1 VLLM pagedattention出现的原因 推理框架 Efficient Memory Management for Large Language
FlashAttention: 更快训练更长上下文的GPT【论文粗读·6】
vLLM: Easy, Fast, and Cheap LLM Serving with PagedAttention
怎么加快大模型推理?10分钟学懂VLLM内部原理,KV Cache,PageAttention
vLLm: 大模型LLM快速推理的神器, llama2秒级完成推理不用再等待
vLLM源码阅读s1——源码介绍
vLLM源码阅读s2——是如何进行离线推理的
⏱️78s看懂FlashAttention【有点意思·1】
通义千问-大模型vLLM推理与原理
大模型推理框架 vLLM 源码解析 PagedAttention原理详解 continueBatching策略详解-卢菁博士授课-怎么加快大模型推理
LoRA:训练你的GPT【论文粗读·1】
kvCache原理及代码介绍---以LLaMa2为例
Fast LLM Serving with vLLM and PagedAttention
llama3-02-环境配置 基于vLLM推理
GPTQ&OBC:量化你的GPT【论文粗读·4】
DeepSpeed-FastGen比vLLM推理性能快2倍,SplitFuse策略 #小工蚁
LLM-Attack: 撬开GPT阁下的嘴【论文粗读·8】
QLoRA:训练更大的GPT【论文粗读·5】
FastChat新版本发布整合vLLM,让大模型推理能力提升10倍
【强荐】大模型推理框架VLLM 原理详解!vLLM支持的大模型推理技术和优化 推理框架vLLM的核心技术 vLLM部署实战 大模型训练实战课程!大模型入门教程
OBD&OBS:给神经网络做个外科手术【论文粗读·3】
【vLLM】个人视角畅谈大模型推理优化的挑战、现有工作和未来展望
Fast LLM Serving with vLLM and PagedAttention
【论文】Efficient Memory Management for Large Language Model Serving PagedAttention
大模型并发加速部署 解析当前应用较广的几种并发加速部署方案!
LightLLM轻量级高性能推理框架 和vLLM哪个更强?
Flash Attention原理!数据布局转换与内存优化!【推理引擎】离线优化第04篇
KV缓存:Transformer中的内存使用!
论文分享:从Online Softmax到FlashAttention-2
PagedAttention论文开源 高效GPU内存管理机制
手把手教学!使用 vLLM 快速部署 Yi-34B-Chat
[LLMs 实践] 20 llama2 源码分析 cache KV(keys、values cache)加速推理
flashattention原理深入分析
阿里通义千问模型支持vllm,推理速度大幅提升,目前仍有BUG
VLLM ——高效GPU训练框架
【大模型部署】vllm部署glm4及paged attention介绍
llama.cpp 源码解析-- CUDA版本流程与逐算子详解
Flash Attention 为什么那么快?原理讲解
大模型推理引擎vllm,以及pagedattention提高吞吐量的原理