V
主页
【xinference】(1):在autodl上,使用xinference部署chatglm3大模型,支持函数调用,使用openai接口调用成功!
发布人
【大模型研究】(11):在autodl上,使用xinference部署chatglm3大模型,支持函数调用,使用openai接口调用成功! 支持函数调用啦! 文档: https://inference.readthedocs.io/zh-cn/latest/getting_started/ github地址: https://github.com/xorbitsai/inference
打开封面
下载高清视频
观看高清视频
视频下载器
【xinference】(9):本地使用docker构建环境,一次部署embedding,rerank,qwen多个大模型,成功运行,非常推荐
【xinference】(7):在autodl上,使用xinference一次部署embedding,rerank,qwen多个大模型,兼容openai的接口协
【Dify知识库】(12):在autodl上,使用xinference部署chatglm3,embedding,rerank大模型,并在Dify上配置成功
10分钟上手Huggingface,轻松调用Bert模型预训练 | 模型下载 | 预训练模型 | 应用实战
【xinference】(6):在autodl上,使用xinference部署yi-vl-chat和qwen-vl-chat模型,可以使用openai调用成功
【LocalAI】(6):在autodl上使用4090部署LocalAIGPU版本,成功运行qwen-1.5-32b大模型,占用显存18G,速度 84t/s
终于弄明白FastChat服务了,本地部署ChatGLM3,BEG模型,可部署聊天接口,web展示和Embedding服务!
【xinference】(3):在autodl上,使用xinference部署whisper-tiny音频模型,并成功将语音转换成文本
【LocalAI】(5):在autodl上使用4090Ti部署LocalAIGPU版本,成功运行qwen-1.5-14b大模型,占用显存8G
【大模型研究】(5):在AutoDL上部署,一键部署DeepSeek-MOE-16B大模型,可以使用FastChat成功部署,显存占用38G,运行效果不错。
【Dify知识库】(1):本地环境运行dity+fastchat的ChatGLM3模型,可以使用chat/completions接口调用chatglm3模型
【xinference】(14):在compshare上,使用nvidia-docker方式,成功启动推理框架xinference,并运行大模型,非常简单方便
【xinference】:目前最全大模型推理框架xinference,简单介绍项目,咱们国人开发的推理框架,目前github有3.3k星星
【xinference】(5):在autodl上,使用xinference部署sdxl-turbo模型,效果好太多了,模型的进步效果更好,图像更加细腻
【大模型研究】(6):在AutoDL上部署,成功部署Mixtral-8x7B大模型,8bit量化,需要77G显存,355G硬盘
【Dify知识库】(2):开源大模型+知识库方案,Dify+fastchat的BGE模型,可以使用embedding接口对知识库进行向量化,绑定聊天应用
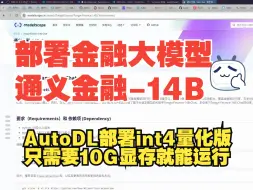
【大模型研究】(9):通义金融-14B-Chat-Int4金融大模型部署研究,在autodl上一键部署,解决启动问题,占用显存10G,有非常多的股票专业信息
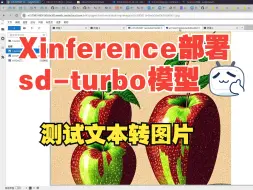
【xinference】(4):在autodl上,使用xinference部署sd-turbo模型,可以根据文本生成图片,在RTX3080-20G上耗时1分钟
【deepseek】(2):使用3080Ti显卡,fastchat运行deepseek-coder-6.7b-instruct模型,出现死循环EOT的BUG
【ollama】(4):在autodl中安装ollama工具,配置环境变量,修改端口,使用RTX 3080 Ti显卡,测试coder代码生成大模型
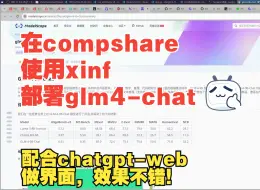
【xinference】(11):在compshare上使用4090D运行xinf和chatgpt-web,部署GLM-4-9B-Chat大模型,占用显存18G
在AutoDL上,使用4090显卡,部署ChatGLM3API服务,并微调AdvertiseGen数据集,完成微调并测试成功!
【大模型研究】(1):从零开始部署书生·浦语2-20B大模型,使用fastchat和webui部署测试,autodl申请2张显卡,占用显存40G可以运行
【wails】(5):经过一段时间的研究,使用wails做桌面应用开发,使用gin+go-chatglm.cpp本地运行大模型,开发接口,在linux上运成功!
【大模型知识库】(3):本地环境运行flowise+fastchat的ChatGLM3模型,通过拖拽/配置方式实现大模型编程,可以使用completions接口
【ollama】(7):使用Nvidia Jetson Nano设备,成功运行ollama,运行qwen:0.5b-chat,速度还可以,可以做创新项目了
【xinference】(15):在compshare上,使用docker-compose运行xinference和chatgpt-web项目,配置成功!!!
【ai技术】(4):在树莓派4上,使用ollama部署qwen0.5b大模型+chatgptweb前端界面,搭建本地大模型聊天工具,速度飞快
Open AI发布o1模型最新使用教程,国内无限制版!o1模型免费使用,免登录,直接使用!完整解读模型特点,推理能力已超博士!
【compshare】(1):推荐一个GPU按小时租的平台,使用实体机部署,可以方便快速的部署xinf推理框架并提供web展示,部署qwen大模型,特别方便
【全374集】2024最新清华内部版!终于把AI大模型(LLM)讲清楚了!全程干货讲解,通俗易懂,拿走不谢!
xinference一键实现各种大模型本地部署(包含llm,tts,asr,embedding,rerank等模型)
【大模型研究】(4):在AutoDL上部署,一键部署DeepSeekCoder大模型,可以快速生成各种代码,程序员代码生成利器!效率非常高!
【LocalAI】(3):超级简单!在linux上使用一个二进制文件,成功运行embeddings和qwen-1.5大模型,速度特别快,有gitee配置说明
【candle】(3):安装rust环境,使用GPU进行加速,成功运行qwen的0.5b,4b,7b模型,搭建rust环境,配置candle,下使用hf-mir
【大模型研究】(3):在AutoDL上部署,使用脚本一键部署fastchat服务和界面,部署生成姜子牙-代码生成大模型-15B,可以本地运行,提高效率
【chatglm3】(8):模型执行速度优化,在4090上使用fastllm框架,运行ChatGLM3-6B模型,速度1.1w tokens/s,真的超级快。
【candle】(4):使用rsproxy安装rust环境,使用candle项目,成功运行Qwen1.5-0.5B-Chat模型,修改hf-hub下载地址
使用autodl服务器,两个3090显卡上运行, Yi-34B-Chat-int4模型,用vllm优化,增加 --num-gpu 2,速度23 words/s
【LocalAI】(7):在autodl上使用4090D部署,成功部署localai-cuda-12的二进制文件,至少cuda版本是12.4才可以,运行qwen