V
主页
[NeRF进展,Avatar实时生成] 苏黎世I联邦理工,普朗克研究所提出InstantAvatar,相比SOTA方法速度提升130倍以上,秒级别训练,实时渲染
发布人
InstantAvatar: Learning Avatars from Monocular Video in 60 Seconds Tianjian Jiang(苏黎世联邦理工学院),Xu Chen(苏黎世联邦理工学院,普朗克智能系统研究所),Otmar Hilliges(苏黎世联邦理工学院) 项目主页:https://tijiang13.github.io/InstantAvatar/ 在这个工作中,我们取得了真实世界单视神经avatar重建应用的巨大进展:InstantAvatar,一个可以使用单目视频,在秒级别的时间内重建人类avatar,这些avatar可以以交互的速度被动画和渲染。为了达到这个效率,我们提出了一个细致设计和实现的系统,使用一个加速神经场的架构和一个有效的对动态场景空白空间跳过机制。同时,我们也贡献了一个高性能的实现,为了更多的研究成果也开源了出来。相比已有方法,InstantAvatar可以达到130倍以上的速度提升,并可以在分钟级别完成训练,而不需要数小时。它可以达到一致或甚至更好的重建效果和合成新姿态的效果。给定一样的时间预算,我们的方法可以大幅度地超越SOTA方法。InstantAvatar可以在10秒的训练时间里,达到完成可以接受的视觉效果。 In this paper, we take a significant step towards real-world applicability of monocular neural avatar reconstruction by contributing InstantAvatar, a system that can reconstruct human avatars from a monocular video within seconds, and these avatars can be animated and rendered at an interactive rate. To achieve this efficiency we propose a carefully designed and engineered system, that leverages emerging acceleration structures for neural fields, in combination with an efficient empty space-skipping strategy for dynamic scenes. We also contribute an efficient implementation that we will make available for research purposes. Compared to existing methods, InstantAvatar converges 130x faster and can be trained in minutes instead of hours. It achieves comparable or even better reconstruction quality and novel pose synthesis results. When given the same time budget, our method significantly outperforms SoTA methods. InstantAvatar can yield acceptable visual quality in as little as 10 seconds training time.
打开封面
下载高清视频
观看高清视频
视频下载器
从985到苏黎世联邦理工大学,我都经历了什么
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
[NeRF进展,单目视频重建动态人-物-场景] 新加坡国立大学,腾讯等提出HOSNeRF,使用单目视频动态人-物-场景,LPIPS相比SOTA提升40%以上
[NeRF进展,移动实时渲染方向]Snapchat与东北大学联合推出MobileR2L,在移动设备上实时、低消耗、高质量地渲染NeRF三维场景,移动应用有突破
[NeRF进展,鲁棒的动态NeRF] RoDynRF CVPR最终presentation视频,联合预测静态、动态和相机姿态焦点信息,提升动态nerf鲁棒性
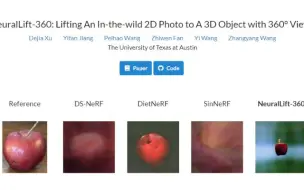
[NeRF进展,单图片成3D内容] 德克萨斯大学奥斯丁分校提出NeuralLift-360,使用单图生成3D物体
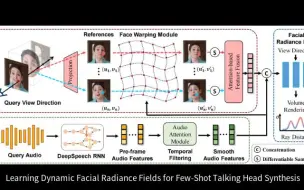
[NeRF进展,Talking Head应用] 清华大学、鉴智机器人提出DFRF,快速小样本生成高真实感、自然的讲话头,可用于数字人等(ECCV 2022)
SyncTalk第五讲以deepspeech方式训练解决双下巴问题并新增NPY文件生成工具
I3D 2023 Papers Session 1 - Neural Rendering and Image Warping
[NeRF进展,任意拓扑重建] 腾讯提出NeAT,另一个可用于重建衣物等任意拓扑的工作,NeuralUDF姊妹篇,计算量更低,效果的缺陷更小,代码开源(CVPR
[NeRF进展,文本生成3D] Google,Ben、Jonathan提出DreamBooth3D,DreamBooth+DreamFusion,文本生成3D
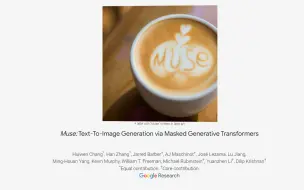
[Transformer进展,文本生成图片]GoogleAI提出Muse,首次使用Transformer代替Diffusion模型完成文本生成图片,速度快
SyncTalk三种训练方式ave、deepspeech、hubert效果对比其中hubert防抖效果最好
[NeRF进展,稀疏视角重建] 斯坦福,Google, SFU提出SCADE,使用cIMLE和space carving方法,提升稀疏无约束室内NeRF重建效果
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF
[NeRF进展,复杂场景编辑]斯坦福大学、Adobe提出PaletteNeRF,对复杂场景的外观属性进行后期编辑,NeRF向Adobe产品家族整合成为可能
[NeRF进展,肖像光照] 中科院、北交大、香港城市大学提出NeRFFaceLighting,使用三平面解决人物肖像的3D感知的真实感光照效果,并达到实时处理
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[3DGS] 作者Bernhard Kerbl讲讲3DGS的历史、思考过程(感谢群友的投喂)
[NeRF进展,镜头硬件参数校准] 康奈尔大学、Meta提出Neural Lens Modeling,在训练模型时同步优化相机参数,解决光学镜头参数校准问题
[NeRF进展,3D形状表达] KAUST和TUM发表3DShape2VecNet,面向扩散生成模型的形状神经场表达,对3D形状编码和生成及多个下游任务非常有效
[大佬讲paper第三期] 腾讯AI实验室胡文博大佬讲神经渲染中的Anti-Aliasing问题,以及SIG24中的新作Rip-NeRF等相关工作
[Neural Rendering]Facebook Reality Lab提出AutoAvatar,推进神经场技术到真实人体动效生成领域(ECCV 2022)
[NeRF+Mesh进展,城市场景建模] nVidia,多伦多大学等提出FEGR,结合Mesh,将复杂几何和材质与光照效果分离,实现真实感光照效果,以及场景操控
[NeRF进展,点云重建] 捷克理工大学提出Tetra-NeRF,使用点云为输入,使用四面体和其德劳内表达进行重建,实现更好的重建性能和效果
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
[NeRF进展,TensoRF+PBR] 浙江大学、UCSD等提出TensoIR,将场景以神经场与密度、法向、光照、材质等信息一起建模,实现高质量建模
[NeRF进展,场景天气风格化渲染]UIUC、浙江大学,马里兰大学提出ClimateNeRF,在NeRF场景中融合天气物理渲染,实现真实感天气场景渲染效果
[NeRF进展,高保真3D Avatar生成]香港科技大学、微软研究院提出Rodin,自动高保真、高细节度生成3D Avatar NeRF模型,数字虚拟人再突破
SyncTalk第三讲:【训练】拥有自己的专属数字人模型就可以无限次推理
[点云进展,单图生成3D图片动画] 华中科技大学,Adobe,南洋理大学CVPR提出使用单图片生成3D图片动画的工作,提升图片内容表现力
[Generative AI进展]Adobe,特拉维夫大学,CMU提出一种使用已训练生成模型和目标概念,直接生成目标域内容的方法,可批量生成大量效果
[NeRF进展,实时流建模] 斯坦福大学提出NeRFBridge,将机器人操作系统ROS与nerfstudio桥接,实时在线流式训练NeRF模型
[NeRF进展,自动数据收集] INSA, UCBL, Meta提出AutoNeRF,一种不需要人工干预的自动agent,采集NeRF训练数据,协助完成下游任务
[NeRF+Diffusion进展,少量视触目] Nitantic推出DIffusioNeRF,使用RGBD贴片训练的DDM模型,正则化few-shot重建过程
[NeRF进展,CLIP加NeRF,支持语言查询] 另一位创世大神Matthew新作提出LERF,在NERF中支持语言查询,ChatGPT将可与3D交互?
[NeRF进展,时变3D模型] 浙大,康奈尔,特拉维夫提出neusc,使用网上地标照片,重建可独立控制视点、光照和时间的真实感时变三维模型
[动态NeRF进展] 三星尖端技术研究院提出时域插值动态NeRF方法,通过在时域进行特征向量插值,构建动态场景的神经网络表达,训练速度与质量大幅度提升
[Diffusion生成点云,开源]OpenAI开源大招Point-E,通过文本生成3D point cloud的方法,快速有效地生成多样化复杂的3D模型
[NeRF进展,高精度人头部动作生成] TUM提出NeRSemble,组合变形场和多分辨率3Dhash编码高精度生成人头运动。同时提供多视角高精度运动数据集