V
主页
[NeRF进展,单目视频重建动态人-物-场景] 新加坡国立大学,腾讯等提出HOSNeRF,使用单目视频动态人-物-场景,LPIPS相比SOTA提升40%以上
发布人
HOSNeRF: Dynamic Human-Object-Scene Neural Radiance Fields from a Single Video Jia-Wei Liu(Show Lab, National University of Singapore, ARC Lab), Yan-Pei Cao(ARC Lab),Tianyuan Yang(Show Lab, National University of Singapore),Eric Zhongcong Xu(Show Lab, National University of Singapore), Jussi Keppo(National University of Singapore),Ying Shan(ARC Lab),Xiaohu Qie(Tencent PCG),Mike Zheng Shou(Show Lab, National University of Singapore) 项目主页:https://showlab.github.io/HOSNeRF/ We introduce HOSNeRF, a novel 360° free-viewpoint rendering method that reconstructs neural radiance fields for dynamic human-object-scene from a single monocular in-the-wild video. Our method enables pausing the video at any frame and rendering all scene details (dynamic humans, objects, and backgrounds) from arbitrary viewpoints.The first challenge in this task is the complex object motions in human-object interactions, which we tackle by introducing the new object bones into the conventional human skeleton hierarchy to effectively estimate large object deformations in our dynamic human-object model. The second challenge is that humans interact with different objects at different times, for which we introduce two new learnable object state embeddings that can be used as conditions for learning our human-object representation and scene representation, respectively. Extensive experiments show that HOSNeRF significantly outperforms SOTA approaches on two challenging datasets by a large margin of 40% ∼ 50% in terms of LPIPS. Compelling examples of 360° free-viewpoint renderings from single videos are provided in the following video.
打开封面
下载高清视频
观看高清视频
视频下载器
[NeRF+Diffusion进展,图片生成3D] 上海交通大学,香港科技大学,微软提出MakeIt3D,使用Diffusion Prior将单图转为3D效果
[NeRF进展,文本编辑NeRF] 创始大神Matthew+18岁大学生一作提出Instruct-NeRF2NeRF,使用文本指令进行3D场景的真实感编辑
[NeRF+Diffusion进展,少量输入重建] CMU提出SparseFusion,在最少两个输入视角情况下,可以完成3D一致性高的高质量重建
[动态3DGS与场景编辑] 请香港大学黄熠华博士一起讲讲SC-GS和Deformable 3DGS两项工作
Gaussian Splatting三维重建之沈阳理工大学图书馆
[NeRF进展,单视频大规模场景重建] KAIST,台大,Meta等发表Progressive LocalRF,使用单视频重建大规模场景NeRF,提升显著
[NeRF进展,文本生成NeRF场景] 香港城市大学、腾讯提出Text2NeRF,一种由文本生成NeRF场景的方法,室内外生成效果都不错
[3DGS+无相机位姿] UTAustin,nVidia,厦大等提出InstantSplat,40秒以内,从完全不知道内外参的多视角图片,重建出3DGS
[NeRF进展,3D分割] 上海交通大学、华中科技大学、华为提出SA3D,给定一个NeRF,SA3D可以完成目标物体的3D分割
[NeRF进展,镜头硬件参数校准] 康奈尔大学、Meta提出Neural Lens Modeling,在训练模型时同步优化相机参数,解决光学镜头参数校准问题
[3DGS进展] UCSD,nVidia,伯克利提出CF-3DGS,连续处理视频帧数据,在剧烈相机运动的情况下渐进重建整个场景
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF
[NeRF进展,重着色方向]香港中文大学提是出RocolorNeRF,提取场景中的颜色层信息,在后期使用调色板对NeRF进行重新着色
[NeRF进展,实时建图] 中山大学、香港科技大学提出H2Mapping,第一个基于NeRF构建在可手持设备上运行的建图方法,效果优于NICE-SLAM
[NeRF进展,点云重建] 捷克理工大学提出Tetra-NeRF,使用点云为输入,使用四面体和其德劳内表达进行重建,实现更好的重建性能和效果
[3DGS几何优化]上科大、图宾根大学提出2DGS,一种从多视图图像中建模和重建几何精确辐射场的新方法,解决3DGS几何一致性差的问题
[Diffusion三维重建] 香港城市大学、SFU提出一种新的基于Diffusion的单图或多图NVS方法,无需训练即可生成出色的生成体验
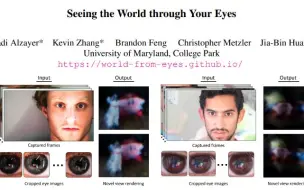
[NeRF进展,反射场景提取] 马里兰大学的新脑洞,通过眼睛反射重建所看到的场景,又一个使用神经场通过反射完成场景重建
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
[NeRF进展,动态系统建模,优于D-NeRF] UCLA、MIT、马里兰大学等提出Pac-NeRF,从多视角视频中提取高动态优物体的几何与物理参数信息
[NeRF进展,CLIP加NeRF,支持语言查询] 另一位创世大神Matthew新作提出LERF,在NERF中支持语言查询,ChatGPT将可与3D交互?
[NeRF进展,单图重建] TUM, MCML和牛津大学提出BTS,一个密度场将输入图像的每个位置映射到体密度上,然后从图片采样颜色,可处理被遮挡区域
[NeRF进展,避免重建干扰,提升重建效果] Google研究院,多伦多大学,SFU提出RobustNeRF,在场景中有影响效果时,用优化算法达到更好的重建效果
[NeRF进展,稀疏输入视角重建]CMU提出GBT,在稀疏图片输入的情况下,使用几何biased Transformer显著提升稀疏图片重建效果
[3DGS进展] 浙大CADCG,字节提出可变形的3DGS方法,对单目动态场景进行建模,在渲染质量和速度取得优势,适合NVS问题,时间序列合成和实时渲染
[NeRF进展,无pose prior的NeRF重建] 牛津大学提出NoPe-NeRF,在没有先验相机pose信息的情况下,优化NeRF和相机姿态(CVPR)
[NeRF进展,渲染质量提升] Google NeRF的几位创始人:Zip-NeRF,解决Mip-NeRF 360锯齿问题,复杂场景渲染提升,训练速度提升22倍
[文本转3D进展] 清华、人大等:ProlificDreamer,使用VSD解决过饱和、过平滑、低多样性问题,SDS是VSD的特殊情况,可应用在NeRF生成场景
[NeRF进展,单视角3D重建]香港大学、未来智联等联合推出S3-NeRF,挖掘Shading和Shadow信息提升单视角3D重建(NeurIPS 2022)
[NeRF进展,使用事件相机生成高质量NeRF] 马克思普朗克研究院,萨尔大学提出EventNeRF,使用事件相机生成高质量NeRF,低功耗、低数据量、快速重建
[NeRF,快速高质量重建] Tri-MipRF(PICO,清华,中科院),结合实时重建和抗锯齿高质量渲染的神经场方法,更小模型可达SOTA渲染质量和重建速度
[Mesh进展] nVidia,多伦多大学提出FlexiCubes,使用isosurface或标量场迭代优化3D表面Mesh,相比MC和DMTeT取得巨大提升
[NeRF进展,交互编辑方向] Inria, 马克斯普郞克学院提出NerfShop,使用基于Cage变形的方法进行物体的交互式选择与编辑,进一步推动实用
[NeRF进展,动态3D场景表达]UC伯克利、意大利技术研究院、丹麦技术大学提出KPlane,使用6-plane特征表现4D体数据,HexPlane类似解决方案
[大佬讲paper第三期] 腾讯AI实验室胡文博大佬讲神经渲染中的Anti-Aliasing问题,以及SIG24中的新作Rip-NeRF等相关工作
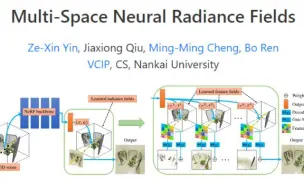
[NeRF进展,反射折射物体表达] 南开大学提出MS-NeRF,一种针对场景中反射和折射物体表达和渲染的方法,低消耗地提升NeRF模型,对相应场景效果提升显著
[NeRF进展,快速人体动态NeRF建模] 浙江大学提出InstantNVR,速度提升100倍以上的快速人体动态NeRF建模方法,CVPR 2023已发布
[NeRF进展,Lidar三维重建]多伦多大学提出TransientNeRF,新的使用多视角lidar,通过捕获皮秒时间尺度瞬态光传输,完成新视角生成和3D重建
[NeRF进展,肖像光照] 中科院、北交大、香港城市大学提出NeRFFaceLighting,使用三平面解决人物肖像的3D感知的真实感光照效果,并达到实时处理