V
主页
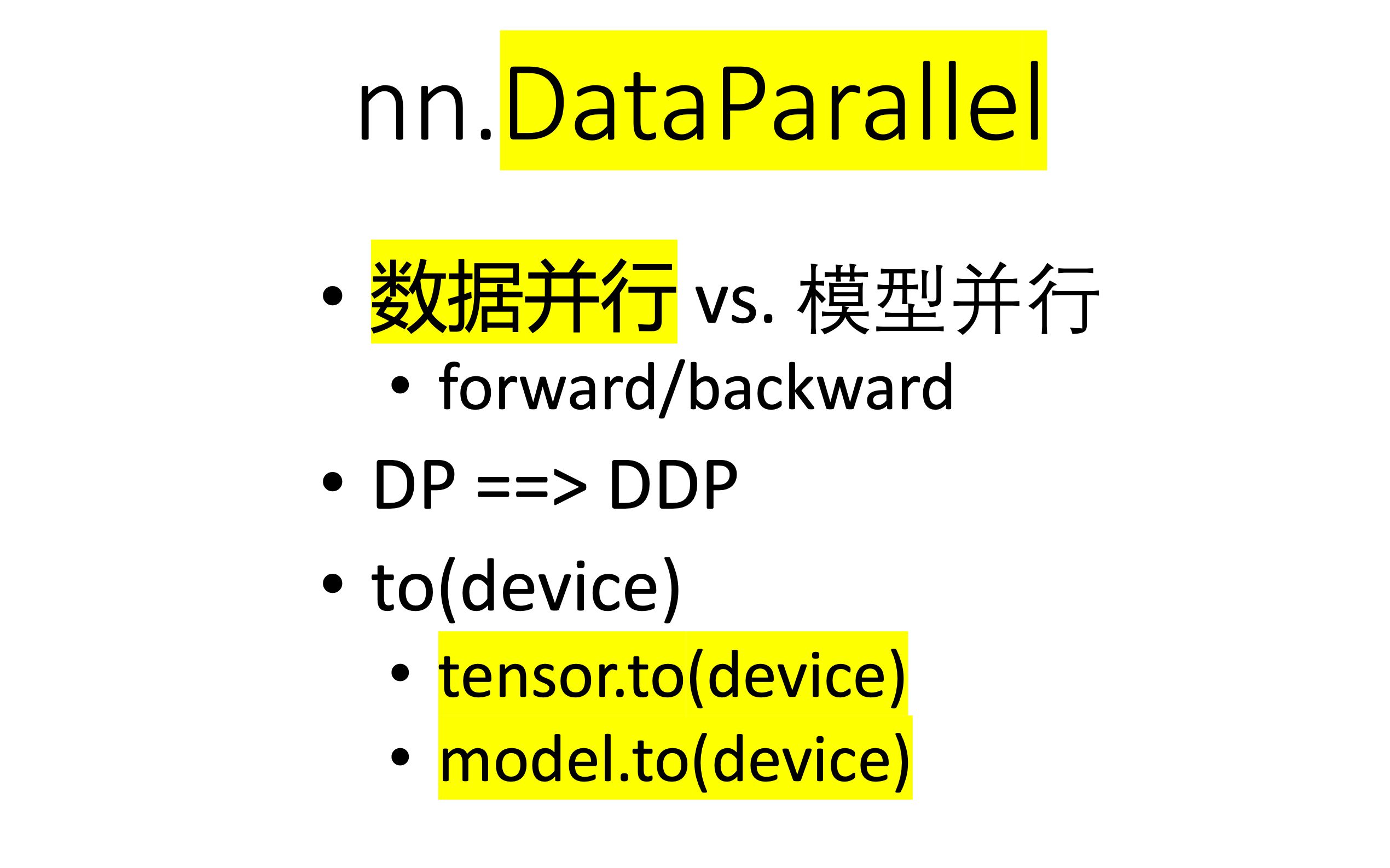
[pytorch distributed] 01 nn.DataParallel 数据并行初步
发布人
本期code:https://github.com/chunhuizhang/pytorch_distribute_tutorials/blob/main/tutorials/01_multi_gpus_data_parallelism.ipynb
打开封面
下载高清视频
观看高清视频
视频下载器
pytorch多GPU并行训练教程
PyTorch数据并行怎么实现?DP、DDP、FSDP数据并行原理?【分布式并行】系列第02篇
DeepSpeed:炼丹小白居家旅行必备【神器】
动画理解Pytorch 大模型分布式训练技术 DP,DDP,DeepSpeed ZeRO技术
33、完整讲解PyTorch多GPU分布式训练代码编写
「分布式训练」原理讲解+ 「DDP 代码实现」修改要点
Deepspeed大模型分布式框架精讲
[pytorch distributed] 从 DDP、模型并行、流水线并行到 FSDP(NCCL,deepspeed 与 Accelerate)
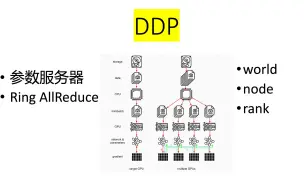
[pytorch distributed] 02 DDP 基本概念(Ring AllReduce,node,world,rank,参数服务器)
[pytorch distributed] 03 DDP 初步应用(Trainer,torchrun)
34 多GPU训练实现【动手学深度学习v2】
[pytorch distributed] deepspeed 基本概念、原理(os+g+p)
[pytorch 加速] CPU传输 & GPU计算的并行(pin_memory,non_blocking)
[pytorch distributed] 04 模型并行(model parallel)on ResNet50
[pytorch distributed] nccl 集合通信(collective communication)
[pytorch distributed] amp 原理,automatic mixed precision 自动混合精度
[pytorch 强化学习] 01 认识环境(environment,gym.Env)以及 CartPole-v0/v1 环境
[pytorch distributed] 05 张量并行(tensor parallel),分块矩阵的角度,作用在 FFN 以及 Attention 上
[调包侠] 使用深度学习模型(paddlehub - humanseg)进行人物提取(前景提取、抠图)
[pytorch distributed] torch 分布式基础(process group),点对点通信,集合通信
[模型拓扑接口] 经典 RNN 模型(一)模型参数及训练参数的介绍
[pytorch optim] Adam 与 AdamW,L2 reg 与 weight decay,deepseed
[leetcode reviews] 01 计算思维与刷题方法
[蒙特卡洛方法] 01 从黎曼和式积分(Reimann Sum)到蒙特卡洛估计(monte carlo estimation)求积分求期望
[小白向-深度学习装机指南] 01 双4090 涡轮版开箱启动 vlog(gpu burn,cpu burn)
[LLMs 实践] 01 llama、alpaca、vicuna 整体介绍及 llama 推理过程
[python 多进程、多线程以及协程] 01 关于进程(multiprocessing,pid、ppid)
[diffusion] 生成模型基础 VAE 原理及实现
[LLMs inference] quantization 量化整体介绍(bitsandbytes、GPTQ、GGUF、AWQ)
[动手写bert系列] 01 huggingface tokenizer (vocab,encode,decode)原理及细节
[QKV attention] kv-cache、decoder only vs. BERT, 单向注意力 vs. 双向注意力
[stable diffusion] 01 本地安装及环境配置(diffusers, StableDiffusionPipeline, text2image)
[手推公式] sigmoid 及其导数 softmax 及其导数性质(从 logits 到 probabilities)
[LLM+RL] 合成数据与model collapse,nature 正刊封面
[LLM & AIGC] 01 openai api 的简单介绍(文本生成/指令,图像生成)
[LLMs 实践] 02 LoRA(Low Rank Adaption)基本原理与基本概念,fine-tune 大语言模型
[五分钟系列] 01 gensim embedding vectors 距离及可视化分析
[动手写神经网络] 如何设计卷积核(conv kernel)实现降2采样,以及初探vggnet/resnet 卷积设计思路(不断降空间尺度,升channel)
[LLMs 实践] 221 llama2 源码分析 generate 的完整过程
[QKV attention] flash attention(Tiling与重计算),operation fused,HBM vs. SRAM