V
主页
[pytorch distributed] 05 张量并行(tensor parallel),分块矩阵的角度,作用在 FFN 以及 Attention 上
发布人
本期 code:https://github.com/chunhuizhang/pytorch_distribute_tutorials/blob/main/tutorials/tensor_parallel.ipynb
打开封面
下载高清视频
观看高清视频
视频下载器
[pytorch distributed] 01 nn.DataParallel 数据并行初步
[pytorch distributed] accelerate 基本用法(config,launch)数据并行
[pytorch distributed] 张量并行与 megtron-lm 及 accelerate 配置
[动手写bert系列] BertSelfLayer 多头注意力机制(multi head attention)的分块矩阵实现
[pytorch distributed] 04 模型并行(model parallel)on ResNet50
注意力机制背后的数学原理(Query,Key,Value)
[pytorch distributed] torch 分布式基础(process group),点对点通信,集合通信
[动手写神经网络] pytorch 高维张量 Tensor 维度操作与处理,einops
[pytorch distributed] 从 DDP、模型并行、流水线并行到 FSDP(NCCL,deepspeed 与 Accelerate)
[pytorch] torch.nn.Bilinear 计算过程与 einsum(爱因斯坦求和约定)
[pytorch] Tensor 轴(axis)交换,transpose(转置)、swapaxes、permute
[矩阵分析] 分块矩阵的角度理解矩阵运算(独热向量与对角矩阵)
[pytorch distributed] deepspeed 基本概念、原理(os+g+p)
[动手写 Transformer] 手动实现 Transformer Decoder(交叉注意力,encoder-decoder cross attentio)
[动手写神经网络] 01 认识 pytorch 中的 dataset、dataloader(mnist、fashionmnist、cifar10)
[pytorch distributed] nccl 集合通信(collective communication)
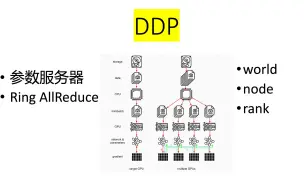
[pytorch distributed] 02 DDP 基本概念(Ring AllReduce,node,world,rank,参数服务器)
[pytorch] nn.Embedding 前向查表索引过程与 one hot 关系及 max_norm 的作用
[QKV attention] kv-cache、decoder only vs. BERT, 单向注意力 vs. 双向注意力
[pytorch 强化学习] 05 迷宫环境(maze environment)策略梯度(Policy Gradient)求解
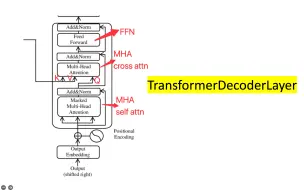
[bert、t5、gpt] 05 构建 TransformerDecoderLayer(FFN 与 Masked MultiHeadAttention)
[pytorch 加速] CPU传输 & GPU计算的并行(pin_memory,non_blocking)
[pytorch] 激活函数,从 ReLU、LeakyRELU 到 GELU 及其梯度(gradient)(BertLayer,FFN,GELU)
[pytorch] torch.einsum 到索引到矩阵运算(index、shape、dimension、axis)
[pytorch 强化学习] 01 认识环境(environment,gym.Env)以及 CartPole-v0/v1 环境
[pytorch distributed] 03 DDP 初步应用(Trainer,torchrun)
[pytorch distributed] amp 原理,automatic mixed precision 自动混合精度
[pytorch] Tensor shape 变化 view 与 reshape(contiguous 的理解)
[QKV attention] flash attention(Tiling与重计算),operation fused,HBM vs. SRAM
[LLMs 实践] 21 llama2 源码分析 GQA:Grouped Query Attention
[矩阵分析] LoRA 矩阵分析基础之 SVD low rank approximation(低秩逼近)
Apache Doris 在正泰集团数据中台的应用实践 | Apache Doris@杭州站
[动手写Bert系列] bertencoder self attention 计算细节及计算过程
[diffusion] 生成模型基础 VAE 原理及实现
[pytorch] [求导练习] 05 计算图(computation graph)构建细节之 inplace operation(data与detach)
[pytorch 强化学习] 10 从 Q Learning 到 DQN(experience replay 与 huber loss / smooth L1)
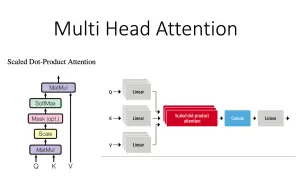
[[bert、t5、gpt] 03 AttentionHead 与 MultiHeadAttention
[pytorch 强化学习] 11 逐行写代码实现 DQN(ReplayMemory,Transition,DQN as Q function)
[动手写神经网络] 05 使用预训练 resnet18 提升 cifar10 分类准确率及误分类图像可视化分析
[pytorch] [求导练习] 06 计算图(computation graph)细节之 retain graph(multi output/backwar)