V
主页
[QKV attention] kv-cache、decoder only vs. BERT, 单向注意力 vs. 双向注意力
发布人
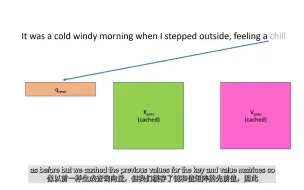
本期 code:https://github.com/chunhuizhang/pytorch_distribute_tutorials/blob/main/tutorials/kv-cache.ipynb llama2 kvcache:BV1FB4y1Z79y,BV1Ea4y1d7wx 之前发过的token连接方式的动态:https://www.bilibili.com/opus/942536178060492803
打开封面
下载高清视频
观看高清视频
视频下载器
从编解码和词嵌入开始,一步一步理解Transformer,注意力机制(Attention)的本质是卷积神经网络(CNN)
注意力机制的本质|Self-Attention|Transformer|QKV矩阵
LLM面试_为什么常用Decoder Only结构
Flash Attention 为什么那么快?原理讲解
kvCache原理及代码介绍---以LLaMa2为例
怎么加快大模型推理?10分钟学懂VLLM内部原理,KV Cache,PageAttention
【研1基本功 (真的很简单)Group Query-Attention】大模型训练必备方法——bonus(位置编码讲解)
Llama 2 模型结构解析
【官方双语】直观解释注意力机制,Transformer的核心 | 【深度学习第6章】
LLM面试_padding side
【官方双语】ChatGPT背后是什么模型和原理?详细阐述decoder-only transformer模型!
LLM面试_模型参数量计算
主流开源大模型LLama基本架构 KV-Cache, Rotary Positional Embedding, RMS Norm, Grouped Query
【研1基本功 (真的很简单)Decoder Encoder】手写Decoder Layer 准备召唤Transformer
[LLMs 实践] 20 llama2 源码分析 cache KV(keys、values cache)加速推理
姚顺雨-从语言模型到语言智能体(From Language Models to Language Agents)
Grouped-Query Attention (GQA)原理及代码介绍---以LLaMa2为例
[LLMs 实践] 01 llama、alpaca、vicuna 整体介绍及 llama 推理过程
姚顺雨-语言智能体博士答辩 Language Agents: From Next-Token Prediction to Digital Automation
自制大模型推理框架-KVCache动手实现-秋招快人一步
【复现】transformer推理速度优化-kvcache技术
KV缓存:Transformer中的内存使用!
[动手写bert系列] 01 huggingface tokenizer (vocab,encode,decode)原理及细节
[QKV attention] flash attention(Tiling与重计算),operation fused,HBM vs. SRAM
75、Llama源码讲解之RoPE旋转位置编码
The KV Cache: Memory Usage in Transformers
【双语·YouTube搬运·生成语言模型中的KV缓存】The KV Cache: Memory Usage in Transformers
[LLMs 实践] 02 LoRA(Low Rank Adaption)基本原理与基本概念,fine-tune 大语言模型
[personal chatgpt] LLAMA 3 整体介绍(与 LLama 2 的不同?)
[AI Agent] llama_index RAG 原理及源码分析
[DRL] 从 TRPO 到 PPO(PPO-penalty,PPO-clip)
解密旋转位置编码:数学基础、代码实现与绝对编码一体化探索
[gpt2 番外] training vs. inference(generate),PPL 计算,交叉熵损失与 ignore_index
[personal chatgpt] gpt-4o tokenizer 及特殊中文tokens(压缩词表),o200k_base
[pytorch distributed] 05 张量并行(tensor parallel),分块矩阵的角度,作用在 FFN 以及 Attention 上
k-Sparse AutorEncoder 与大语言模型可解释性研究(openai、claude),top-K 求导
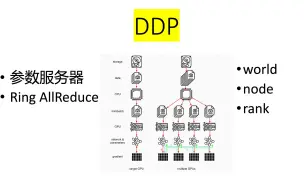
[pytorch distributed] 02 DDP 基本概念(Ring AllReduce,node,world,rank,参数服务器)
[pytorch distributed] 01 nn.DataParallel 数据并行初步
大模型全栈总览-tokenizer
动画理解Pytorch 大模型分布式训练技术 DP,DDP,DeepSpeed ZeRO技术