V
主页
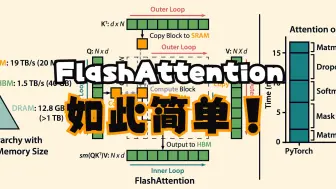
[QKV attention] flash attention(Tiling与重计算),operation fused,HBM vs. SRAM
发布人
本期code:https://github.com/chunhuizhang/bert_t5_gpt/blob/main/tutorials/attention/flash_attn.ipynb Gradient checkpoint:BV1QM4y1H7nH sdpa:https://t.bilibili.com/950688477003907138?spm_id_from=333.999.0.0
打开封面
下载高清视频
观看高清视频
视频下载器
[手写flash attention v1 & v2] baseline的基础实现
⏱️78s看懂FlashAttention【有点意思·1】
Flash Attention 为什么那么快?原理讲解
flash attention的cuda编程
【CUDA Mode 2024】中英字幕
FlashAttention: 更快训练更长上下文的GPT【论文粗读·6】
【研1基本功 (真的很简单)Group Query-Attention】大模型训练必备方法——bonus(位置编码讲解)
[QKV attention] kv-cache、decoder only vs. BERT, 单向注意力 vs. 双向注意力
论文分享:从Online Softmax到FlashAttention-2
第二十课:MoE
一个视频让你对flash attention2下头(比较FA2和sdpa的效率)
超强动画,深入浅出解释Transformer原理!这可能是我看到唯一一个用动画讲解Transformer原理的教程!真的通俗易懂!——(人工智能、神经网络)
19、Transformer模型Encoder原理精讲及其PyTorch逐行实现
[pytorch 强化学习] 01 认识环境(environment,gym.Env)以及 CartPole-v0/v1 环境
怎么加快大模型推理?10分钟学懂VLLM内部原理,KV Cache,PageAttention
[personal chatgpt] Llama2 7B vs. Llama3 8B (词表、attention 及 mlp)
NVIDIA AI 加速精讲堂-TensorRT-LLM量化原理、实现与优化
[generative models] 概率建模视角下的现代生成模型(生成式 vs. 判别式,采样与密度估计)
77、Llama源码讲解之GroupQueryAttention和KV-cache
[[bert、t5、gpt] 02 transformer 架构 scaled dot product self attention(qkv)
[DRL] 从 TRPO 到 PPO(PPO-penalty,PPO-clip)
[动手写bert系列] 01 huggingface tokenizer (vocab,encode,decode)原理及细节
[gpt2 番外] training vs. inference(generate),PPL 计算,交叉熵损失与 ignore_index
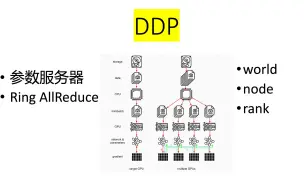
[pytorch distributed] 02 DDP 基本概念(Ring AllReduce,node,world,rank,参数服务器)
[pytorch distributed] 01 nn.DataParallel 数据并行初步
[LLMs inference] quantization 量化整体介绍(bitsandbytes、GPTQ、GGUF、AWQ)
[RLHF] 从 PPO rlhf 到 DPO,公式推导与原理分析
[pytorch distributed] 04 模型并行(model parallel)on ResNet50
[pytorch distributed] deepspeed 基本概念、原理(os+g+p)
[LLMs 实践] 13 gradient checkpointing 显存优化 trick
徒手实现反向传播算法--分布式训练、GPU运算等
[pytorch distributed] torch 分布式基础(process group),点对点通信,集合通信
[LLMs 实践] 01 llama、alpaca、vicuna 整体介绍及 llama 推理过程
[pytorch distributed] 张量并行与 megtron-lm 及 accelerate 配置
[pytorch 加速] CPU传输 & GPU计算的并行(pin_memory,non_blocking)
[pytorch distributed] nccl 集合通信(collective communication)
[pytorch distributed] amp 原理,automatic mixed precision 自动混合精度
CUDA实现矩阵乘法的8种优化策略编程介绍
[pytorch distributed] 从 DDP、模型并行、流水线并行到 FSDP(NCCL,deepspeed 与 Accelerate)
[pytorch distributed] 03 DDP 初步应用(Trainer,torchrun)