V
主页
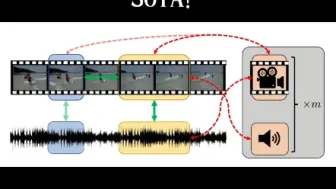
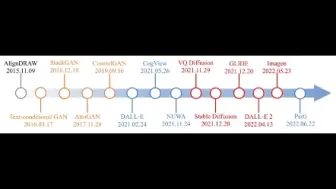
刷爆视频音频Zero-Shot榜单!北大提出LanguageBind!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
继EMO之后又火了!阿里提出Image-to-Video新框架AtomoVideo!
见识一下ChatGPT-4o强大的识图能力!细节不但拉满,还能对图片进行分析并打分!
SAM+CLIP,会擦出什么样的火花!模型组合大法霸榜图像分割Zero-Shot!
图像+音频驱动的口播视频生成!谷歌提出VLOGGER!
AI生成剧烈运动视频,大翻车引起大佬热议, 到底是什么原因造成的?
超过IP-Adapter!中科大提出超保真ID个性化AIGC新方法Infinite-ID!
Stability AI又放大招了!基于SD3蒸馏更快的文生图模型SD3-Turbo!
几秒钟完成图像定制化生成!清华联合腾讯提出无需微调的AIGC新框架!
SAM+扩散模型让图片中的对象动起来!腾讯提出RegionMaker!
本科毕业设计Nature送审Nature Biotechnology发表,中间都经历了什么?
2024【研究生SCI论文写作课程】中科院博士手把手教你SCI论文写作技巧\投稿流程\工具\写作指南等教程,高效完成SCI论文发表
来自真实用户的百万级文本视频数据!Sora时代的视频生成数据集VidProM开源了!
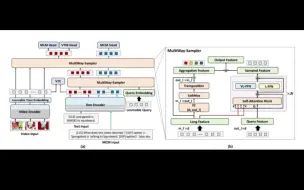
阿里提出用于视频文本理解的高效多模态模型MuLTI,通过设计了Multiway Sampler和多项选择建模任务 在多项视频理解任务上达到新SOTA!
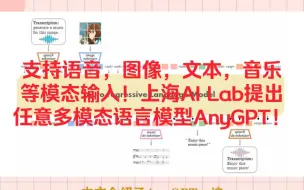
支持语音,图像,文本,音乐等模态输入!上海AI Lab提出任意多模态语言模型AnyGPT!
北大联合南洋理工提出了一种简单有效的开放词汇实例分割框架,分割效果惊艳!
Adobe研究院提出了用于视频和音频多模态数据的视听对比学习的自监督策略,在多项视频和音频数据集上达到新SOTA!
AI:拉过最炸裂的一坨艺术!
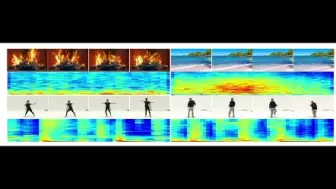
微软联合北大提出了首个用于音视频联合生成的多模态扩散模型MM-Difussion!可以给定视频生成音频或给定音频生成视频!
即插即用的inpainting模型!腾讯提出BrushNet!
腾讯联合新国立提出了一种one-shot文本生成视频的方法!效果超过CogVideo!代码和模型即将开源!
腾讯优图提出啄木鸟(Woodpecker):无需训练即可矫正多模态大语言模型的幻觉问题!
Mamba再下一城!上海AI Lab提出视频领域新SOTA VideoMamba!
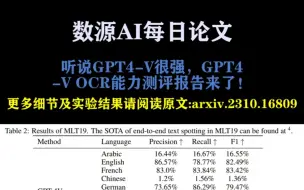
听说GPT4-V很强,GPT4-V OCR能力测评报告来了!
阿里发布最强中文图文多模态模型:Chinese CLIP,基于两亿中文图文多模态数据!
无需定义类别,生成式开放物体检测!字节提出目标检测新框架GenerateU!
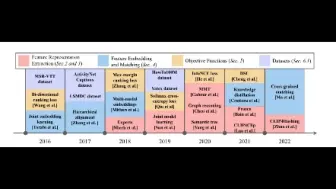
基于深度学习的视频文本的跨模态检索30页综述来了,包含近7年150篇相关论文!
基于Diffusion模型的以文生图综述来了!包含145篇相关论文,涉及Diffusion相关理论和基础介绍!
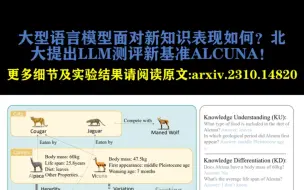
大型语言模型面对新知识表现如何?北大提出LLM测评新基准ALCUNA!
多模态还能助力NLP任务!上交学者提出TILT方法,利用多模态检索图像增强文本表征,多项NLP下游任务达到SOTA!
LLaVA+SEEM+GLIGEN,微软提出多模态交互原型Demo LLaVA-Interactive!
原来AI真的能生成高颜值美女,快来试试多模态生成模型吧!
多模态大模型 MiniCPM-V 2.6「实时视频理解」首次上端!
微软提出了KOSMOS-G,利用MLLM来指导通用视觉-语言输入生成图像!!
清华智源基于LLM提出更全面精细的多模态图文数据集CAPSFUS-120M!
Adobe提出基于预训练图像Diffusion模型的视频编辑器,无需训练即可完成视频编辑功能,效果超过Tune-a-Video等方法!
【NeurIPS 2023】华为诺亚提出新的YOLO检测模型:Gold-YOLO,达到YOLO系列新SOTA!!
DeepMind联合VGG组提出基于Mask的多模态Transformer架构Zorro,联合视频音频输入,在视频分类数据集上取得SOTA性能!
将机器人接入大模型,使其听懂“人话”,自主决策
Mamba卷到多模态了!基于Mamba的多模态大语言模型VL-Mamba来了!