V
主页
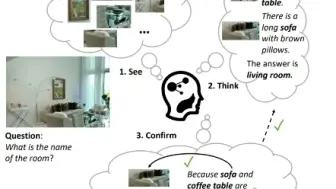
几秒钟完成图像定制化生成!清华联合腾讯提出无需微调的AIGC新框架!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
PDF 完全免费在线工具箱,方便处理任意PDF文件!
用kimi 10秒搞定Excel,效率起飞🚀
支持让AI给视频人物换装+换表情的9月升级版工作流来了
2024最好出创新点的方向:【对比学习+多模态】CLIP模型、Dalle2、多模态3D目标检测、MedCLIP医学图像文本,计算机博士带你轻松搞定论文创新点!
开学季盛宴,全球最强 AI 应用平台联合RAG Flow 知识库系统正式上线!
开学季盛宴,ChatGPT 联合 RAG 知识库应用平台正式上线啦!
解锁CLIP长文本能力!即插即用替换CLIP!上海AI Lab提出Long-CLIP!
百度要放弃基础通用大模型的研发了?
强烈推荐!吴恩达大模型微调+langchain+RAG+Mistral系列教程!不愧是圈内公认的大佬!多模态大模型
【FLUX 大模型微调/Lora训练】Linux一键训练包,Windows部分修复torch2.4.0BUG问题
SAM+扩散模型让图片中的对象动起来!腾讯提出RegionMaker!
上交学者提出了一种利用Diffusion模型生合成语义分割数据集,并基于此训练了一个开放词汇分割的模型,效果惊艳!
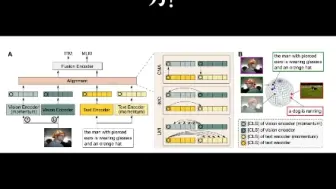
腾讯优图提出啄木鸟(Woodpecker):无需训练即可矫正多模态大语言模型的幻觉问题!
中国AI的短板走一条自己的路!人工智能技术
超过IP-Adapter!中科大提出超保真ID个性化AIGC新方法Infinite-ID!
Comfyui+ICLight一键抠图换背景+重打光,SegmentAnythingUltra_V2
CLIP可以直接拿来做文本检测了!腾讯优图提出TCM结构,文本检测能力在多个数据集上均有较大提升!目前以被CVPR2023接收!
仅需0.5M!可集成任意扩散模型!字节提出灵活分辨率适配器ResAdapter!
15项将改变未来的新型技术( 纳米技术 6G 机器人 无人机 3D打印 人工智能AI AR)
【B站首推】大模型Agent智能体企业级项目实战:手把手带你搭建一套属于你的智能体,原理讲解+代码解析,超详细,LLM_大模型_微调_提示词
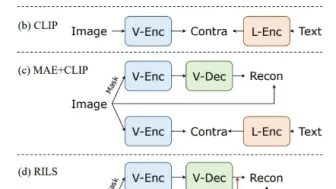
腾讯结合了MAE和CLIP,提出了新的在语言语义上进行掩码重建的预训练框架RILS,超过多种视觉预训练和多模态预训练方案!
阿里发布最强中文图文多模态模型:Chinese CLIP,基于两亿中文图文多模态数据!
鹏城实验室学者提出了一种新的视频语言多模态预训练模型SOTA-VLP,融合了空间时序建模方法,捕获细粒度特征,多项任务取得SOTA!
吴恩达大模型系列:使用Gemini进行大型多模态模型提示|Large Multimodal Model Prompting with Gemini 附课件+代码
文本引导的虚拟试衣来了,多模态在时尚领域的又一杀器!一键更换模特服装!目前代码模型已开源!
北大联合华为诺亚提出了一种增强对比学习的新方法ArCL,通过学习更鲁棒的特征,将MOCO等对比学习方法提升1-2个百分点!目前已被ICLR 2023接收!
1分钟内快速完成学术润色,全网最简易论文润色教程来啦!
SD原班人马,推出超越Midjourney的绘画模型?!
沃顿商学院教授:每个机构都充斥着秘密的半机器人! 他们用AI完成工作但不会告诉你!
MIT联合清华提出基于知识的视觉推理多模态模型IPVR,模拟人类视觉推理,取得较好效果!
Metaf发布,LMMs王者登场!Transformer和Diffusion强势融合,促进语言模型和图像生成大一统
百度联合VIS提出新的文档图像理解预训练框架StrucTextv2,设计了适用于文档数据的掩码自监督策略,目前已被ICLR 2023接收!
当医学图像遇上SAM,会产生什么样的火花,基于SAM的医学图像分割finetune框架来了,附代码!
NVIDIA放大招了!在生成模型基础上提出Action-GPT:利用GPT实现任意文本生成动作!效果绝了!
颠覆传统编程,超越Cursor!Claude Dev最强编程AI智能体!支持ollama和GitHub models!一条prompt实现全自动游戏开发!
真菌和计算机组合机器人问世!人工智能机器人
SD吊打PS垃圾扩图!AI免费扩图神器!零基础也能学会SD如何扩展图像背景,一键安装,手把手教学!
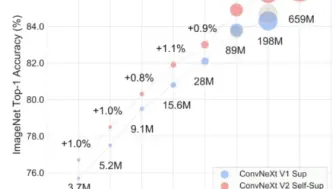
最强视觉backbone网络ConvNext v2来了!Meta AI融合了视觉掩码自监督框架,提出新的新的SOTA算法!目前代码和模型已开源!
亚马逊联合牛津提出了用于多模态理解的三元对比学习TCL,在CLIP的基础上提升了多模态模型的跨模态理解能力!
草莓大模型的技术特色和应用价值