V
主页
上交学者提出了一种利用Diffusion模型生合成语义分割数据集,并基于此训练了一个开放词汇分割的模型,效果惊艳!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
CVPR 2023,EVA升级,智源开源更强的视觉预训练模型EVA-2,Vit-L Imagenet精度达到90+!
中山大学学者提出新的视觉Transfomer结构DilateFormer,减少70%计算量的同时性能更优!目前已开源!
阿里提出了一种无需解码头的轻量化语义分割网络,参数量减少30%的同时性能提升4个百分点!
鹏城实验室学者提出了一种新的视频语言多模态预训练模型SOTA-VLP,融合了空间时序建模方法,捕获细粒度特征,多项任务取得SOTA!
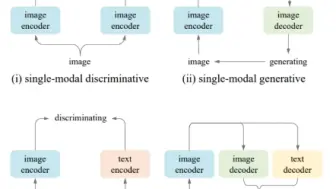
中科大提出All-in-One多模态预训练方法,利用统一的多模态互信息提升多模态性能,下游检测分割性能超过BEIT V3!
谷歌基于多模态预训练模型,提出了一种开放词汇的时序动作检测模型,可以检测视频中任意动作!性能远超之前方法!
微软提出了一种图像分割,视觉语言大一统模型X-Decoder!open-vocabulary语义分割效果惊艳!多项下游任务性能表现SOTA,目前代码和模型已开源
Adobe提出基于预训练图像Diffusion模型的视频编辑器,无需训练即可完成视频编辑功能,效果超过Tune-a-Video等方法!
CLIP可以直接拿来做文本检测了!腾讯优图提出TCM结构,文本检测能力在多个数据集上均有较大提升!目前以被CVPR2023接收!
CVPR|2024|CorMatch:基于相关性匹配的标签传播,用于半监督语义分割
面壁 MiniCPM-V 2.6:最强开源端侧多模态 LLM
ECCV 2024 AI涨点神器!超越DINOv2!显著提升语义分割、深度估计性能!
文本引导的虚拟试衣来了,多模态在时尚领域的又一杀器!一键更换模特服装!目前代码模型已开源!
华为诺亚提出视觉文档理解多模态预训练模型WuKong-Reader,在百万级文档数据上进行了预训练,多项下游任务效果SOTA!
谷歌学者提出了简单的DPN策略,在ViT 的Patch Embedding层前后各加一个LN层就能提升ViT性能!
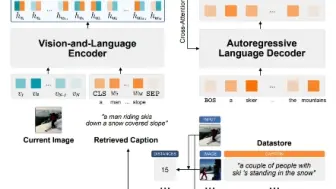
里斯本大学学者提出检索增强的Image Captioning 方法,可以在预训练图文编码器的基础上进一步提升Caption性能!
Meta AI提出新的视觉Transformer结构,相同精度内存减少15倍!代码和模型目前已开源!
真正的万物检测模型,谷歌提出基于VisionTransformer的开放词汇目标检测器
微软提出简单的Open vocabulary检测和分割框架,能够统一处理两种任务,性能超过GLIP等模型!目前已开源!
DeepMind提出De-Diffusion,仅使用图像数据提升多项多模态任务性能!
AI可解释性综述来了,神经网络的黑盒性质经常被许多学者Diss,而可解释性方法让AI不在是完全黑盒!
2024最热门的计算机视觉实战-【图像分割+语义分割】3小时掌握!原理+实战+论文,新手小白首选教程!人工智能/计算机视觉/深度学习/AI/图像处理/机器学习
CLIP助力跨域目标检测,来自EVEN CVLab的学者提出语义增强策略,提升效果明显
斯坦福学者提出ControlNet,通过对Stable Diffussion生成结果进行控制,即将补完AIGC工业化的最后一块拼图!
百度联合VIS提出新的文档图像理解预训练框架StrucTextv2,设计了适用于文档数据的掩码自监督策略,目前已被ICLR 2023接收!
仅需0.5M!可集成任意扩散模型!字节提出灵活分辨率适配器ResAdapter!
新年大礼包,图像分割领域近230页综述开源了!涵盖图像语义分割,实例分割以及3D视频分割等多种场景,涵盖了近百种经典算法,30多个开源数据集!
AI模型的大一统!微软多模态组提出了多模态领域杀疯了的多边形战士BEIT V3!多项视觉,多模态任务达到SOTA!
Kaiming He团队在多模态领域提出的FLIP,结合MAE Masking Image 策略与CLIP,保证精度的同时 大幅提升训练效率!
上海AI Lab提出利用多种预训练模型进行集成学习的新方法CaFo,利用 GPT-3,CLIP,DINO等多种基础预训练模型提升少样本学习能力!
阿里多模态团队基于OFA多模态预训练模型,提出最强中文OCR模型,效果惊艳!
训练日志 | wandb |(1)安装登录
微软总结了视觉Transformer的分类性能,从参数量,计算量等方面对它们进了公平的对比!
谷歌基于Imagen提出了Imagen Editor,文本条件编辑效果超过Stable Diffusion和DALL-E 2!
基于卷积神经网络构建UNET与deeplab 图像分割与语义分割模型,实战医学细胞分割与心脏视频数据分割
商汤科技提出具有双层路由注意力的视觉Transformer,减少原始ViT计算量的同时性能大幅超过Swin Transformer!已被CVPR 2023接收!
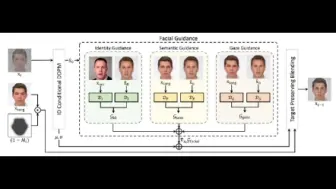
基于Diffusion模型的DiffFace来了,交换效果超过之前的经典模型!代码和模型即将开源!
字节联合爱丁堡大学提出新的视觉预训练方法MUG,取得新的SOTA!模型和代码均已开源,快来领取!
Meta AI助手 视觉识别测试(Quest3 V68)
【EMNLP2023】清华联合阿里提出了利用大型语言模型辅助多模态OOD检测的新方法!