V
主页
微软总结了视觉Transformer的分类性能,从参数量,计算量等方面对它们进了公平的对比!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
统治扩散模型的U-Net结构被取代了!谷歌提出基于Transformer的可扩展扩散模型DiT!计算效率和生成效果均超越ADM和LDM!代码刚刚开源!
腾讯联合浙大提出新的视觉Transformer网络CrossFormer,参数量更少同时性能超过Swin!目前已开源!
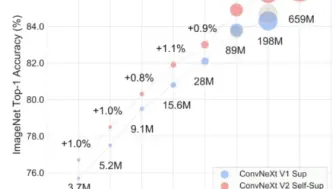
最强视觉backbone网络ConvNext v2来了!Meta AI融合了视觉掩码自监督框架,提出新的新的SOTA算法!目前代码和模型已开源!
开源AI项目爆火!大叔秒变少女,GitHub狂揽7.9K星 | 零度解说
世界上第一本全面解析Transformer的宝藏好书,不管你在学还是想学都一定要看看!——Transformer/机器学习/深度学习
中山大学学者提出新的视觉Transfomer结构DilateFormer,减少70%计算量的同时性能更优!目前已开源!
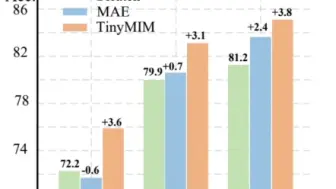
微软亚研提出了小模型蒸馏方法TinyMIM!MIM预训练小模型性能提升4个百分点!目前模型和代码均已开源!
很适合新手用来学习的Transformer工具!超想分享给大家! -神经网络/Transformer/AI by Hand/神经网络入门
超好用的可视化工具,“透视”Transformer
想要通俗易懂地理解Transformer?这本大模型黑书是你的不二选择!
京东提出全球首个面向遥感任务设计的亿级视觉Transformer大模型,基于百万级遥感数据集进行预训练,下游检测,分割等任务性能SOTA,目前模型和代码已开源!
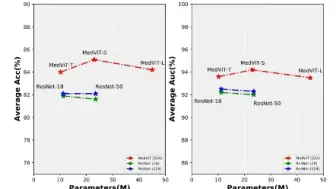
伊朗科技大学学者提出用于医学图像识别的骨干网络MedViT,融合了CNN和Transformer的结构,在多项医学图像任务取得不错效果!
阿里发布最强中文图文多模态模型:Chinese CLIP,基于两亿中文图文多模态数据!
UIUC学者发现冻结LLM中的Transformer是有效的视觉编码器层!多项视觉任务性能均有提升!
最全的30页Loss函数总结综述来了,包含30多种损失函数,涉及分类,回归,Ranking等!
OpenAI绝密文件泄露:2027年实现AGI,人工智能觉醒即将到来
别再质疑AI的变态程度了,用过才知道!
AI可解释性综述来了,神经网络的黑盒性质经常被许多学者Diss,而可解释性方法让AI不在是完全黑盒!
Transformer能否像MobileNets一样快?加州伯克利学者提出Efficient former V2,速度和精度超过之前轻量模型!
Llama 3.1 一键本地部署!Meta 最强开源大模型,100%保证成功,无需GPU也能运行,可离线使用 | 零度解说
AI领域的顶尖论文清单,看完能掌握90%的重要知识?真的假的?-人工智能/Transformer/循环神经网络/长短期记忆
谷歌学者提出了简单的DPN策略,在ViT 的Patch Embedding层前后各加一个LN层就能提升ViT性能!
当医学图像遇上SAM,会产生什么样的火花,基于SAM的医学图像分割finetune框架来了,附代码!
微软提出了KOSMOS-G,利用MLLM来指导通用视觉-语言输入生成图像!!
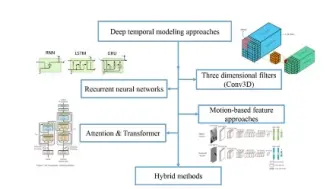
动作识别最新综述来了,包含RNN,3D卷积以及Transformer等算法,涉及近300篇相关论文!
机器人通过模仿学习,做外科手术,网友:手太稳了
它凭什么是换脸直播界的最强软件??deepfacelive
人工智能新突破!登上Nature神坛!首次被证明具有系统泛化能力,能像人类一样举一反三!
终于找到了这个逐行解读代码的网站!全网近百万大学生研究生收藏!github标星超55.6k!----机器学习/深度学习/CV/NLP
还在用GPT的都是冤种!Claude3.5才是最强ai【新手使用教程】
这绝对是2024年【人工智能入门】天花板教程!清华大佬强力打造,68集带你吃透AI基础知识点!
完结撒花!纯手搓Transformer代码最后一期,别再说学不会了!-神经网络/深度学习/pytorch
北大联合华为诺亚提出了一种增强对比学习的新方法ArCL,通过学习更鲁棒的特征,将MOCO等对比学习方法提升1-2个百分点!目前已被ICLR 2023接收!
DeepMind联合VGG组提出基于Mask的多模态Transformer架构Zorro,联合视频音频输入,在视频分类数据集上取得SOTA性能!
用AI还原13位民国佳丽的动态容颜,感受她们100年前的风华正茂!
Absolute Win!3行代码修复Transformer 位置编码插值bug!
基于Transformer的GAN网络综述来了!包含近50种GAN在图像和视频生成上的应用方法,涉及160篇论文!
搞科研论文看不懂咋办?
CVPR2023 | 韩国延边大学提出从图像到视频Transformer的双路自适应网络,仅使用少量学习参数达到多项视频理解任务SOTA,代码已开源!
大模型专家,冒充双非1年,期望40K