V
主页
基于Diffusion模型的DiffFace来了,交换效果超过之前的经典模型!代码和模型即将开源!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
文本引导的虚拟试衣来了,多模态在时尚领域的又一杀器!一键更换模特服装!目前代码模型已开源!
NVIDIA放大招了!在生成模型基础上提出Action-GPT:利用GPT实现任意文本生成动作!效果绝了!
阿里发布最强中文图文多模态模型:Chinese CLIP,基于两亿中文图文多模态数据!
面壁 MiniCPM-V 2.6:最强开源端侧多模态 LLM
上交学者提出了一种利用Diffusion模型生合成语义分割数据集,并基于此训练了一个开放词汇分割的模型,效果惊艳!
“AI读心术”来了,日本学者基于Stable Diffusion模型提出了一个大脑视觉信号重建图像的研究,效果惊人!目前已被CVPR 2023接收!
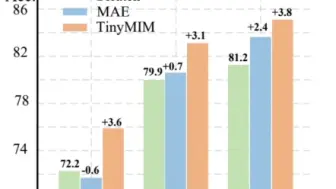
微软亚研提出了小模型蒸馏方法TinyMIM!MIM预训练小模型性能提升4个百分点!目前模型和代码均已开源!
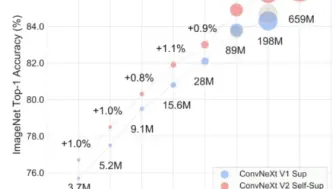
最强视觉backbone网络ConvNext v2来了!Meta AI融合了视觉掩码自监督框架,提出新的新的SOTA算法!目前代码和模型已开源!
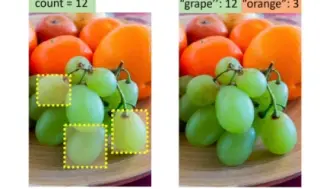
亚马逊学者提出Zero-Shot计数新方法!利用预训练的生成模型生成类别原型特征,然后进行patch最邻近搜索,效果远超之前方法!
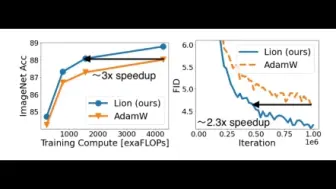
最强优化器来了!谷歌提出适用于多种任务的新型优化器Lion,在多项任务上以更快的训练速度取得更好的性能!目前已开源!
【多模态+大模型+知识图谱】2024最好创新的研究方向!绝对是B站最全的教程,论文创新点终于解决了!——人工智能|深度学习|aigc|计算机视觉
微软提出了一种图像分割,视觉语言大一统模型X-Decoder!open-vocabulary语义分割效果惊艳!多项下游任务性能表现SOTA,目前代码和模型已开源
CVPR 2023,EVA升级,智源开源更强的视觉预训练模型EVA-2,Vit-L Imagenet精度达到90+!
中科大提出All-in-One多模态预训练方法,利用统一的多模态互信息提升多模态性能,下游检测分割性能超过BEIT V3!
AI模型的大一统!微软多模态组提出了多模态领域杀疯了的多边形战士BEIT V3!多项视觉,多模态任务达到SOTA!
2024最新!这可能是目前最系统的【AI大模型】教程了,一口气带你学完LLM主流开源大模型,看完这一下全跑通了!!!(文心一言/百度千帆/讯飞星火大模型)
AI deepfake 人脸交换器 丨让我实时变成了一个可爱的女孩!
当医学图像遇上SAM,会产生什么样的火花,基于SAM的医学图像分割finetune框架来了,附代码!
统治扩散模型的U-Net结构被取代了!谷歌提出基于Transformer的可扩展扩散模型DiT!计算效率和生成效果均超越ADM和LDM!代码刚刚开源!
1分钟内快速完成学术润色,全网最简易论文润色教程来啦!
世界不再有长期,因为五年后的世界将大变样!人工智能
Transformer能否像MobileNets一样快?加州伯克利学者提出Efficient former V2,速度和精度超过之前轻量模型!
仅需0.5M!可集成任意扩散模型!字节提出灵活分辨率适配器ResAdapter!
中山大学学者提出新的视觉Transfomer结构DilateFormer,减少70%计算量的同时性能更优!目前已开源!
鹏城实验室开放了45页多模态预训练大模型综述!总结了近5年多模态预训练相关的算法和数据!多模态预训练学习包!
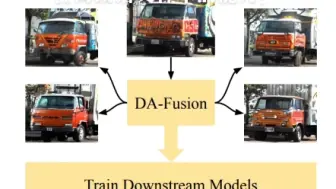
Diffusion Model 可以用来进行图像数据增强了!卡内基梅隆大学学者提出DA-Fusion方法,提升了数据增强产生多样性高级语义样本的能力!
幻方发布超强多模态LLM DeepSeek-VL!支持代码,文档OCR等!
最全的30页Loss函数总结综述来了,包含30多种损失函数,涉及分类,回归,Ranking等!
CLIP可以直接拿来做文本检测了!腾讯优图提出TCM结构,文本检测能力在多个数据集上均有较大提升!目前以被CVPR2023接收!
大学和博士学位已经不值得读了! 牛津大学人类未来研究院院长:AI革命会造成人力资本贬值!
炸裂:上海保姆机器人要上岗!人工智能机器人
解锁CLIP长文本能力!即插即用替换CLIP!上海AI Lab提出Long-CLIP!
【多模态+大模型+知识图谱】2024完整版:这绝对是B站最全的教程,论文创新点终于解决了!——人工智能/深度学习/aigc/计算机视觉
支持语音,图像,文本,音乐等模态输入!上海AI Lab提出任意多模态语言模型AnyGPT!
研究生必备!里面99%的论文都能找到,一个代码复现的神级网站!人工智能/机器学习/深度学习/论文复现/代码
Mamba卷到多模态了!基于Mamba的多模态大语言模型VL-Mamba来了!
国内智驾老兵百度开源BEVWorld:通过统一BEV潜在空间实现自动驾驶的多模态世界模型
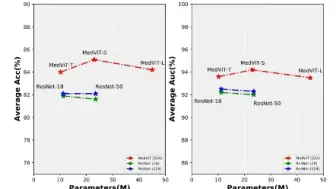
伊朗科技大学学者提出用于医学图像识别的骨干网络MedViT,融合了CNN和Transformer的结构,在多项医学图像任务取得不错效果!
未来每个人都能获得免费的医疗和教育,但不幸的是.... :全球科技投资之王Vinod Khosla !
怎么样保持每天看文献?