V
主页
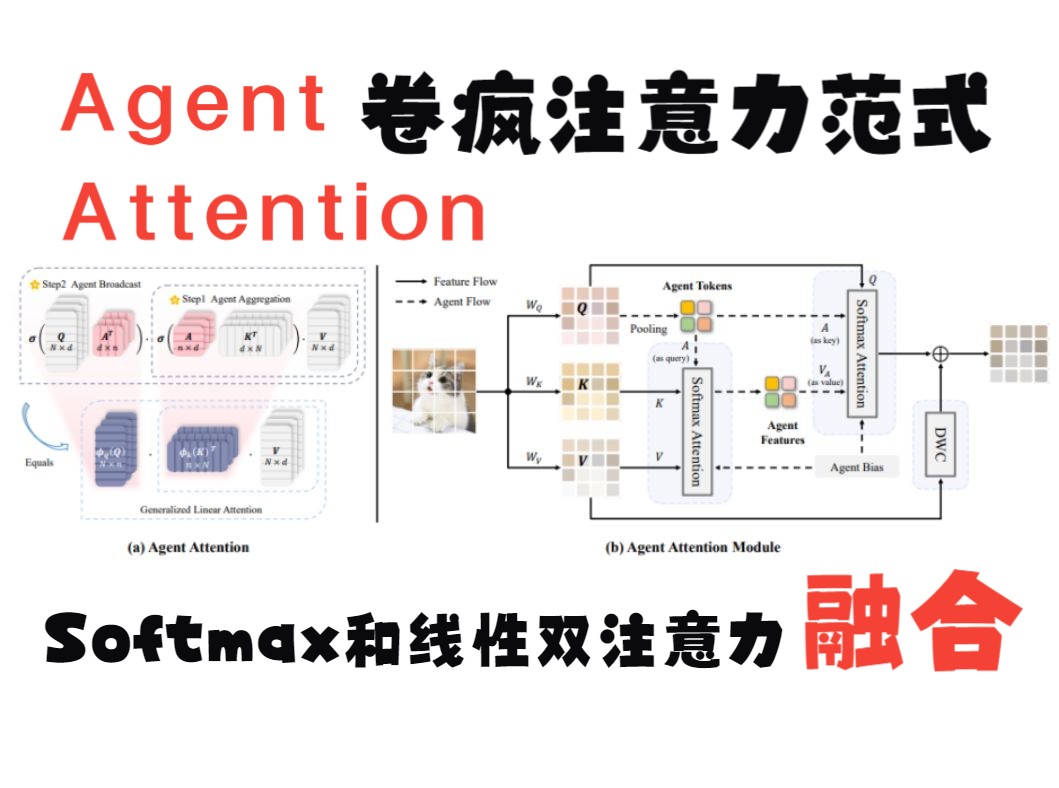
Agent Attention卷疯注意力范式,Softmax和线性双注意力强强联手
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
绝了,A+B竟然可以这么卷!多尺度特征融合+注意力机制,新SOTA准确率高达99%!
涨点神器:清华提出新型注意力机制,深度学习论文创新必备!
CVPR小目标检测:上下文和注意力机制提升小目标检测,一起来看看吧!
注意力机制Pytorch实现:30篇高分Attention论文一次看完!
3分钟带你快速了解注意力(Attention)机制!图文详解,一目了然!
注意力机制创新点都在这里了!51种魔改方法掌握了吗?
【深度学习基本功!启动!】带你手敲Transformer代码之-Muti Head Attention多头注意力篇!
softmax自注意力机制如何使Transformer模型在上下文学习任务表现出彩?
深度学习缝了別的模块的创新点如何描述?思路:魔改attention+多尺度特征融合
中科院一区顶刊:即插即用的多尺度全局注意力机制 【附原文+源码】
7.控制输出平滑度的技巧:带温度的Softmax-最好的Transformer教学视频:通过图形化方式来理解Transformer架构
注意力机制再次升级,自适应Attention展现优异性能,适配多种任务需求
望周知!自回归已击败扩散模型!港大&字节创图像生成全新里程碑
注意力机制是当下每个人科研人都必须掌握技术,30篇高分Attention论文一次看完!
不得不看的Mamba实证研究:英伟达、普林斯顿等联合出品,首创80亿参数Mamba+注意力互补新变体
Transformer颠覆性发现:像素级运算无需局部性归纳偏置 全新像素版性能再升级
给你的U-Net加BUFF!Al Attention出击U-Net,ResNet50+U-Net提升31.8%
2024还做YOLO和U-Net?从0带你基于Qwen-VL搭建一个主流多模态智能体Agent
通用创新点:坐标注意力机制,低成本下表现依旧SOTA!12种主流创新方法汇总
24年图像生成创新潜力股:图像神经场结合扩散模型,任意分辨率就能渲染图像!
何神进MIT后的首篇新作!带队直接大改自回归,借鉴扩散模型进军AI生成
不容错过!24个Transformer重点魔改及其代码复现
英伟达发布最新魔改注意力:简单模型结构+全局信息聚合,SimplifyFormer延迟降低37%,吞吐量提高44%
交叉注意力机制大热!10种前沿创新思路全面汇总,一起见证!
发论文神器!搞深度学习神经网络必知的7个注意力模块!
5.不仅限于词汇:更广泛的嵌入方法-最好的Transformer教学视频:通过图形化方式来理解Transformer架构
深度学习必备创新点:频域+attention,你必须了解!
还在担心生成后的视觉质量?来看基于Transformer的扩散模型新思路!
这绝对是全网最适合新手的huggingface教程了吧,NLP预训练模型、BERT中文模型实战示例、transformer类库、datasets类库快速上手!!
论文新思路:多尺度特征融合13种创新方案,思路格局打开!
【Adobe,加州大学圣克鲁兹分校】Personalized Subject Swapping Topic讲解
用Agent居然可以通关宝可梦!!通过上下文强化学习迭代改进 带你排位赛胜率达到49%
最全模块缝合教程,写论文通用创新点,详解注意力机制插入位置,让模块性能发挥到最佳
Transformer新魔改:性能媲美注意力机制,处理长序列更具优势!
Transformer终于有拿得出手得教程了! 台大李宏毅自注意力机制和Transformer详解!通俗易懂,草履虫都学的会!
自注意力从掩码语言建模中学到了什么?想摸清楚看这篇综述
最新模块及注意力机制缝合教程,十分钟掌握缝合多种模块!深度学习/创新点
第一本全面介绍Transformer架构的书,包含最全155种相关魔改
涨点神器:全局注意力+位置注意力,打造更强深度学习模型,来康8种创新思路
何恺明入职MIT后首次带队,新作再战AI生成!借鉴扩散模型的思想提出Diffusion Loss!-图像生成/扩散模型/深度学习/计算机视觉