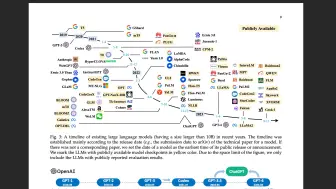
V
主页
李沐-大模型提升主要来自数据清洗工的辛勤工作以及老板大方给了那么多卡
发布人
https://www.bilibili.com/video/BV1Q4421Z7Tj
打开封面
下载高清视频
观看高清视频
视频下载器
李沐-全世界不少人用大模型搞搞成人内容
奇葩问题把李沐大神整不会了
李沐-YOLOv3史上写的最烂的论文-但很work
李沐-我们不知道为什么但是有用
李沐-大模型训练半年-数据来源不清不白-数据不能公开的原因
李沐-除非你是专家否则不建议搞图神经网络
李沐-GPT的能力远不如人类大脑(60w灯泡耗能)
很多研究人员都放弃具身智能了
【李沐】因为过拟合刷题,我最后只能去MIT和CMU这种学校
我的本科毕业设计(2000年)
李沐-打电话叫皮衣黄吃饭饭
李沐-还是要读论文
李沐-学术界数据通常比较干净-工业界的数据一般比较脏
如何看待华为在发布会展示大模型能力,按下 Ctrl-C 中断,对应代码是 time.sleep(6)?
李沐-当年错过一个亿
伤害性不大,侮辱性极强
吴恩达表示,他看到的最令人兴奋的趋势是,生成式人工智能使人们能够以前所未有的水平创建软件,推动事物发展的速度比以往任何时候都快
我是如何快速阅读和整理文献
如何找研究想法 1【论文精读】
【研1基本功 (真的很简单)MoE】混合专家模型—作业:写一个MoELoRA
何恺明MIT第一课-卷积神经网络
李沐-All models are wrong, but some are useful
transformers一个非常严重的bug——在使用梯度累计的时候 loss不等效
杰出系友专访|@BosonAI李沐:找到强烈的动机
李开复透露「GPT5训练遇到困难,O1模型被迫放出来」OpenAI还有很多私货没有发布
李沐-假如你是卖音响的
论文复现:Training on the Benchmark Is Not All You Need上
李沐-预测未来比完形填空昨天难
开发TensorSensor的人真是个天才,快速对张量维度进行对齐、可视化等各种操作!
大模型时代下做科研的四个思路【论文精读·52】
【动手学习大模型 1/12】LLM 面试和工作的区别,让我们一起 import transformers,了解大模型的基本使用流程 (有较好基础同学不推荐观看)
用高铁的电挖比特币 算力达到4T 真猛啊!!!
杨立昆哥大演讲:大语言模型成发展瓶颈,AI真正突破在于理解物理世界
Llama 3.1论文精读 · 5. 模型训练过程【论文精读·54】
大模型被实习生投毒如何防?
大语言大模型(Large Language Models,LLM)-综述-训练流程-实测现状 汇报
GPT-4论文精读【论文精读·53】
姚顺雨-语言智能体博士答辩 Language Agents: From Next-Token Prediction to Digital Automation
Llama 3.1论文精读 · 3. 模型【论文精读·54】
论文复现:Training on the Benchmark Is Not All You Need 下