V
主页
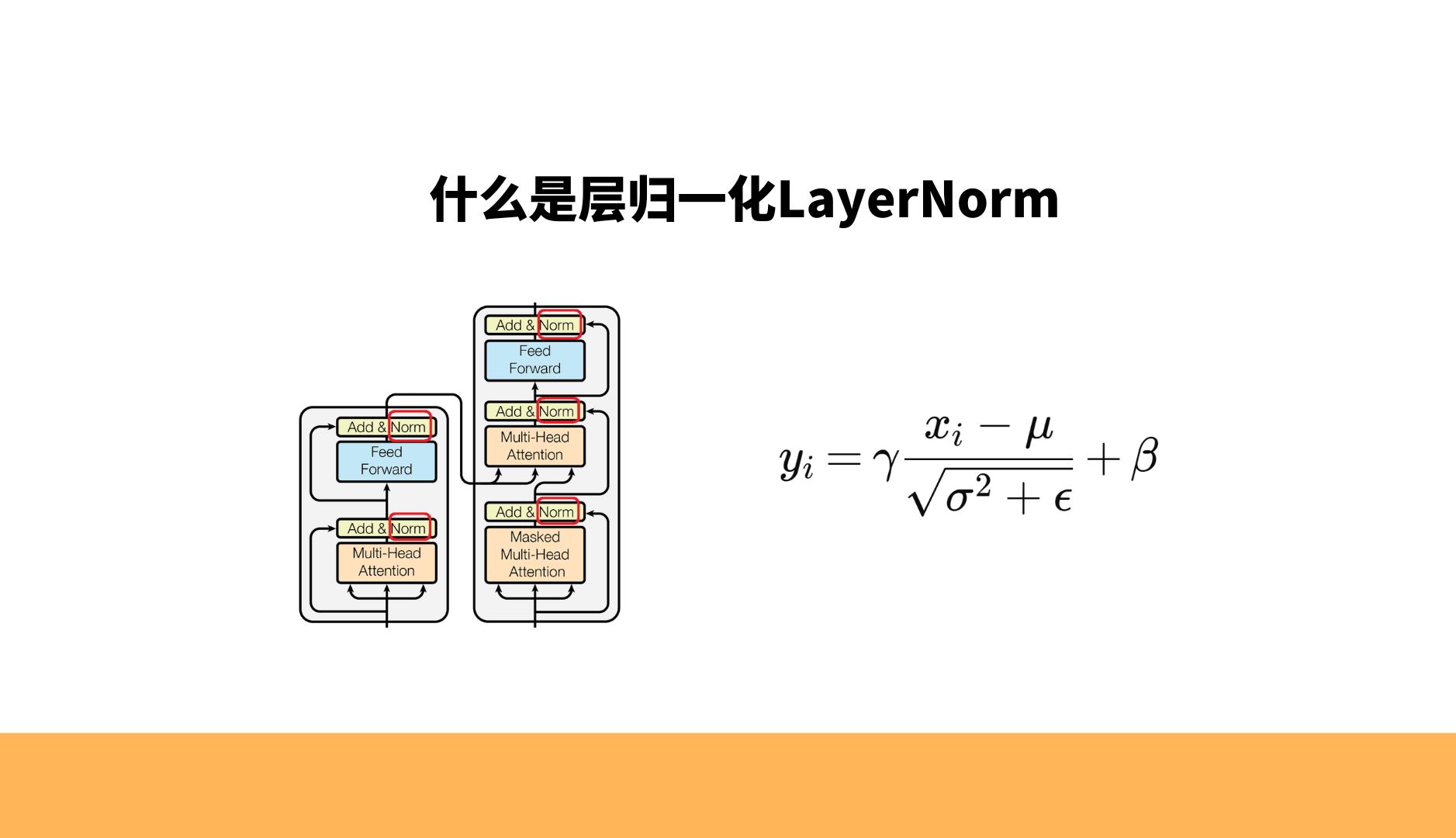
什么是层归一化LayerNorm,为什么Transformer使用层归一化
发布人
什么是层归一化LayerNorm,为什么Transformer使用层归一化
打开封面
下载高清视频
观看高清视频
视频下载器
【研1基本功 (真的很简单)注意力机制】手写多头注意力机制
19、Transformer模型Encoder原理精讲及其PyTorch逐行实现
手推transformer
【官方双语】GPT是什么?直观解释Transformer | 深度学习第5章
从编解码和词嵌入开始,一步一步理解Transformer,注意力机制(Attention)的本质是卷积神经网络(CNN)
Transformer论文逐段精读【论文精读】
【研1基本功 JAX加速框架】pytorch太慢,我偶尔选jax~
学习Transformer,应该从词嵌入WordEmbedding开始
Batch Normalization(批归一化)和 Layer Normalization(层归一化)的一些细节可能和你想的并不一样
从零设计并训练一个神经网络,你就能真正理解它了
手写self-attention的四重境界-part1 pure self-attention
必懂!LayerNorm和BatchNorm的区别-基于Pytorch
LayerNorm层归一化到底做什么的?
transformers一个非常严重的bug——在使用梯度累计的时候 loss不等效
几行代码发一区?SHAP可解释分析,即插即用,保姆级教程来了
Transformer模型详解,Attention is all you need
如何理解Transformer的位置编码,PositionalEncoding详解
直观理解Vision Transformer(ViT)及Diffusion Models使用扩散模型进行图像合成,
彻底弄懂,神经网络的误差反向传播算法
基于yolov8,训练一个安全帽识别的目标检测模型
【LLM前沿】6小时精讲四大多模态大模型CLIP BLIP VIT MLLM及对话机器人办公助手!绝对的通俗易懂的大模型应用教程!
【大模型高效微调】从原理到实战讲明白大模型微调方法LoRA
学习神经网络,最好从逻辑回归开始
【官方双语】一个视频理解神经网络注意力机制,详细阐释!
2024最新模型Mamba详解,Transformer已死,你想知道的都在这里
基于词向量和神经网络,训练文本分类模型
为什么神经网络可以学习任何东西?首次使用动画讲解,带你吃透神经网络!(CNN卷积神经网络、RNN循环神经网络、GAN生成式对抗网络、人工智能、AI)
直接带你把Transformer手搓一遍,这次总能学会Transformer了吧!
十分钟搞明白Adam和AdamW,SGD,Momentum,RMSProp,Adam,AdamW
【中英双语】ChatGPT背后的数学原理是什么?带你看懂Transformer模型的数学矩阵实现!
【官方双语】Transformer模型最通俗易懂的讲解,零基础也能听懂!
从零实现一个卷积神经网络,Lenet5网络详解
完整60讲!计算机博士手把手教学的【Transformer】入门到精通,从零讲解基础原理及模型架构,绝对通俗易懂!
深度学习论文里的数学看不懂?那一定是你还不知道这个方法!
零基础也看得懂,从零实现一个多元线性回归模型
神经网络经典案例,用神经网络模拟正弦函数
LSTM+ASSA+itransformer时间序列预测
[动手写神经网络] 手动实现 Transformer Encoder
动画解释自编码器如是如何工作的及其应用
李开复透露「GPT5训练遇到困难,O1模型被迫放出来」OpenAI还有很多私货没有发布