V
主页
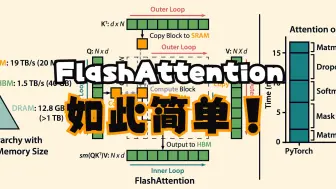
Flash Attention 为什么那么快?原理讲解
发布人
Flash Attention 为什么那么快?原理讲解
打开封面
下载高清视频
观看高清视频
视频下载器
Attention机制(大白话系列)
伤害性不大,侮辱性极强
一层神经网络也可以拟合任意函数?
深入GPU原理:线程和缓存关系【AI芯片】GPU原理01
⏱️78s看懂FlashAttention【有点意思·1】
第24集:AI当道,未来人类会退化吗?
kvCache原理及代码介绍---以LLaMa2为例
Transformer论文逐段精读【论文精读】
AI 工程师都应该知道的GPU工作原理,TensorCore
DPO (Direct Preference Optimization) 算法讲解
【李沐】因为过拟合刷题,我最后只能去MIT和CMU这种学校
多模态论文串讲·上【论文精读·46】
flashattention原理深入分析
注意力机制的本质|Self-Attention|Transformer|QKV矩阵
推理能力最强的llama3.1 405B,不属于中国人
最近火爆的GraphRAG是什么? 真的那么有用吗?
09 Transformer 之什么是注意力机制(Attention)
Batch Normalization(批归一化)和 Layer Normalization(层归一化)的一些细节可能和你想的并不一样
LLM面试_为什么常用Decoder Only结构
作者亲自讲解:LoRA 是什么?
[手写flash attention v1 & v2] baseline的基础实现
再不了解昇腾 AI服务器就要被公关掉了,随时删库跑路! #大模型 #昇腾 #AI芯片
奇葩问题把李沐大神整不会了
李沐-YOLOv3史上写的最烂的论文-但很work
通俗易懂理解自注意力机制(Self-Attention)
论文分享:新型注意力算法FlashAttention
论文分享:从Online Softmax到FlashAttention-2
如何知道一个大模型在推理和训练时需要多少显存?
[强化学习]AI挑战是男人就下100层
flash attention的cuda编程
FlashAttention: 更快训练更长上下文的GPT【论文粗读·6】
Flash Attention原理!数据布局转换与内存优化!【推理引擎】离线优化第04篇
微调一个模型需要多少GPU显存?
【大模型面试】Flash Attention面试连环炮,淘汰80%面试竞争者
1001 Attention 和 Self-Attention 的区别(还不能区分我就真的无能为力了)
半块RTX4090 玩转70B大语言模型
19、Transformer模型Encoder原理精讲及其PyTorch逐行实现
【13】Attention的QKV输出的到底是什么?
你真的理解交叉熵损失函数了吗?
【官方双语】直观解释注意力机制,Transformer的核心 | 【深度学习第6章】