V
主页
亚马逊学者提出了既能看又能读的多模态场景理解模型,支持传统的VQA以及文本VQA!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
仅需0.5M!可集成任意扩散模型!字节提出灵活分辨率适配器ResAdapter!
斯坦福大学AI博士,揭秘最新多模态AI - 杨俊睿 Jackie,MAUI
继EMO之后又火了!阿里提出Image-to-Video新框架AtomoVideo!
图像+音频驱动的口播视频生成!谷歌提出VLOGGER!
Mamba卷到多模态了!基于Mamba的多模态大语言模型VL-Mamba来了!
ChatSpot:更精确的带参考坐标多模态指令微调,目前已开源!#计算机 #论文 #nlp #ai #chatgpt
InternVL 多模态模型语音功能小剧透!
多模态还能助力NLP任务!上交学者提出TILT方法,利用多模态检索图像增强文本表征,多项NLP下游任务达到SOTA!
解锁CLIP长文本能力!即插即用替换CLIP!上海AI Lab提出Long-CLIP!
解锁CLIP长文本能力!即插即用替换CLIP!上海AI Lab提出Long-CLIP!
一小时深度解析【Sora分析】视频生成模型,如何做到文本生成视频?详解背后的技术原理与应用案例!!!
开源AI项目爆火!大叔秒变少女,GitHub狂揽7.9K星 | 零度解说
腾讯优图提出啄木鸟(Woodpecker):无需训练即可矫正多模态大语言模型的幻觉问题!
阿里发布最强中文图文多模态模型:Chinese CLIP,基于两亿中文图文多模态数据!
字节联合爱丁堡大学学者提出新的多模态预训练方法MUG,结合MAE和Caption生成
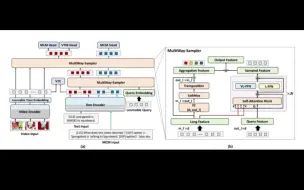
阿里提出用于视频文本理解的高效多模态模型MuLTI,通过设计了Multiway Sampler和多项选择建模任务 在多项视频理解任务上达到新SOTA!
原来AI真的能生成高颜值美女,快来试试多模态生成模型吧!
【多模态+大模型+知识图谱】2024最好创新的研究方向!绝对是B站最全的教程,论文创新点终于解决了!——人工智能|深度学习|aigc|计算机视觉
几秒钟完成图像定制化生成!清华联合腾讯提出无需微调的AIGC新框架!
SAM+扩散模型让图片中的对象动起来!腾讯提出RegionMaker!
微软学者整理了100页图文多模态预训练综述,涉及各种多模态模型和应用,并且附带视频教程,需要的同学快来领取!
给多模态加Buffer,GNN在视觉语言下游任务的应用综述来了!包含125篇相关论文,涉及Image Captioning,VQA,Retrieval三大方向!
超过IP-Adapter!中科大提出超保真ID个性化AIGC新方法Infinite-ID!
即插即用的inpainting模型!腾讯提出BrushNet!
谷歌提出利用语言大模型重写caption来提升图文多模态预训练模型,简单技巧即可提升CLIP多项zeroshot 性能!代码已开源!
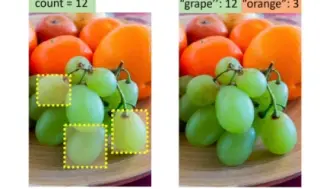
亚马逊学者提出Zero-Shot计数新方法!利用预训练的生成模型生成类别原型特征,然后进行patch最邻近搜索,效果远超之前方法!
NVIDIA放大招了!在生成模型基础上提出Action-GPT:利用GPT实现任意文本生成动作!效果绝了!
Adobe提出超越Stable Diffusion的GAN网络,10亿参数量模型速度吊打Stable Diffusion!目前已被CVPR2023接收!
中科大提出All-in-One多模态预训练方法,利用统一的多模态互信息提升多模态性能,下游检测分割性能超过BEIT V3!
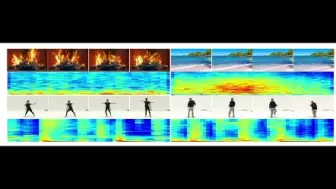
谷歌基于多模态预训练模型,提出了一种开放词汇的时序动作检测模型,可以检测视频中任意动作!性能远超之前方法!
Stability AI又放大招了!基于SD3蒸馏更快的文生图模型SD3-Turbo!
见识一下ChatGPT-4o强大的识图能力!细节不但拉满,还能对图片进行分析并打分!
【NeurIPS 2023】华为诺亚提出新的YOLO检测模型:Gold-YOLO,达到YOLO系列新SOTA!!
微软联合北大提出了首个用于音视频联合生成的多模态扩散模型MM-Difussion!可以给定视频生成音频或给定音频生成视频!
精选【人工智能课程】大模型时代 如何学习人工智能?零基础学习教程!人工智能学习路线 人工智能就业方向 人工智能 大模型 多模态技术路线 人工智能项目开发
SAM+CLIP,会擦出什么样的火花!模型组合大法霸榜图像分割Zero-Shot!
Mamba再下一城!上海AI Lab提出视频领域新SOTA VideoMamba!
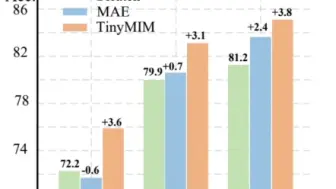
微软亚研提出了小模型蒸馏方法TinyMIM!MIM预训练小模型性能提升4个百分点!目前模型和代码均已开源!
DeepMind提出De-Diffusion,仅使用图像数据提升多项多模态任务性能!
鹏城实验室开放了45页多模态预训练大模型综述!总结了近5年多模态预训练相关的算法和数据!多模态预训练学习包!