V
主页
Adobe提出超越Stable Diffusion的GAN网络,10亿参数量模型速度吊打Stable Diffusion!目前已被CVPR2023接收!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
上交学者提出了一种利用Diffusion模型生合成语义分割数据集,并基于此训练了一个开放词汇分割的模型,效果惊艳!
统治扩散模型的U-Net结构被取代了!谷歌提出基于Transformer的可扩展扩散模型DiT!计算效率和生成效果均超越ADM和LDM!代码刚刚开源!
“AI读心术”来了,日本学者基于Stable Diffusion模型提出了一个大脑视觉信号重建图像的研究,效果惊人!目前已被CVPR 2023接收!
Claude AI创始人Dario Amodei 大胆预测:下一代千亿参数AI模型智力将媲美诺奖得主,
【GAN+自动编码器】DCGAN模型实现生成数字图片!博士精讲GAN原理及实战,GAN生成对抗网络代码讲解!
Meta AI提出新的视觉Transformer结构,相同精度内存减少15倍!代码和模型目前已开源!
CNN-LSTM-Attention:神经网络时间序列预测代码逐行解读,Informer源码解读,Time-LLM:基于大语言模型的时间序列预测!
POV:你得到一个电镀GAN魔方
文本引导的虚拟试衣来了,多模态在时尚领域的又一杀器!一键更换模特服装!目前代码模型已开源!
GAN12ui pro测速
北大联合华为诺亚提出了一种增强对比学习的新方法ArCL,通过学习更鲁棒的特征,将MOCO等对比学习方法提升1-2个百分点!目前已被ICLR 2023接收!
【全187集】字节跳动大佬终于把AI大模型(LLM)讲清楚了!通俗易懂,2024最新内部版!拿走不谢,学不会我退出IT圈!
Adobe提出基于预训练图像Diffusion模型的视频编辑器,无需训练即可完成视频编辑功能,效果超过Tune-a-Video等方法!
NVIDIA放大招了!在生成模型基础上提出Action-GPT:利用GPT实现任意文本生成动作!效果绝了!
PDF 完全免费在线工具箱,方便处理任意PDF文件!
谷歌学者提出了简单的DPN策略,在ViT 的Patch Embedding层前后各加一个LN层就能提升ViT性能!
超越所有YOLO检测模型,mmdet开源当今最强最快的目标检测器RTMDet!
又火了!SDV4.9+flux大模型炸裂大更新(附秋叶SD全套超强整合包+超强模型整合包)yyds 感谢秋枼大佬!sd安装教程 Stablediffusion
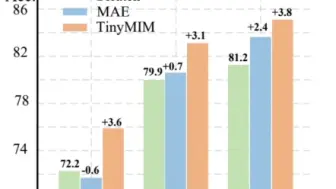
微软亚研提出了小模型蒸馏方法TinyMIM!MIM预训练小模型性能提升4个百分点!目前模型和代码均已开源!
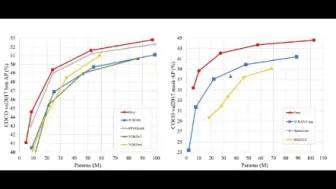
微软提出简单的Open vocabulary检测和分割框架,能够统一处理两种任务,性能超过GLIP等模型!目前已开源!
【多模态+大模型+知识图谱】2024完整版:这绝对是B站最全的教程,论文创新点终于解决了!——人工智能/深度学习/aigc/计算机视觉
【GAN GURUS战报】天才少年王艺衡!4.25秒第四次打破三阶平均世界纪录!
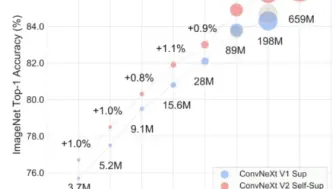
最强视觉backbone网络ConvNext v2来了!Meta AI融合了视觉掩码自监督框架,提出新的新的SOTA算法!目前代码和模型已开源!
CLIP可以直接拿来做文本检测了!腾讯优图提出TCM结构,文本检测能力在多个数据集上均有较大提升!目前以被CVPR2023接收!
【多模态大模型高峰论坛】金连文教授:多模态大模型技术及其在OCR的应用
CVPR2023发表,LayoutDiffusion:用于Layout控制图像生成的新方法,比之前方法取得了更好的生成质量和更多的可控制性!
即插即用的inpainting模型!腾讯提出BrushNet!
解锁CLIP长文本能力!即插即用替换CLIP!上海AI Lab提出Long-CLIP!
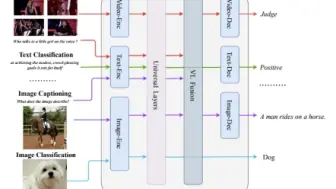
阿里达摩院提出了新的多边形战士模型mPLUG-2,在各种视觉,文本以及多模态任务上均取得不错的性能,超过BEIT V3和EVA!
【劝退】自学StableDiffusion能救一个是一个!这里面的水可深了!人工智能大佬专为零基础研制的StableDiffusion教学教程,太牛了!AI绘图
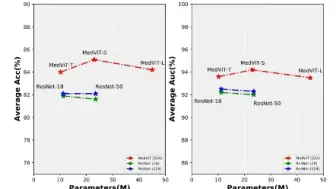
伊朗科技大学学者提出用于医学图像识别的骨干网络MedViT,融合了CNN和Transformer的结构,在多项医学图像任务取得不错效果!
百度联合VIS提出新的文档图像理解预训练框架StrucTextv2,设计了适用于文档数据的掩码自监督策略,目前已被ICLR 2023接收!
亚马逊学者提出了既能看又能读的多模态场景理解模型,支持传统的VQA以及文本VQA!
【全198集】CV入门到起飞!一口气学完Python、OpenCV、深度学习基础、Pytorch、卷积神经网络、物体检测、图像分割、等八大计算机视觉必备基础!
上海AI Lab提出利用多种预训练模型进行集成学习的新方法CaFo,利用 GPT-3,CLIP,DINO等多种基础预训练模型提升少样本学习能力!
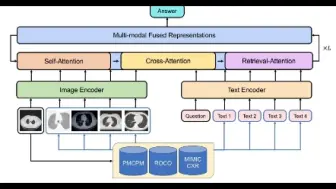
阿里联合清华提出了用于医学VQA的新方法RAMM,利用检索增强的策略在医学VQA数据集上取得新SOTA!数据集,代码即将开源!
AI蛋白质设计详解!基于RF diffusion实现多肽设计
华为诺亚提出视觉文档理解多模态预训练模型WuKong-Reader,在百万级文档数据上进行了预训练,多项下游任务效果SOTA!
CLIP助力跨域目标检测,来自EVEN CVLab的学者提出语义增强策略,提升效果明显
神马!只用60行Numpy代码手搓出GPT大模型!这老哥简直太牛啦