V
主页
微软学者整理了100页图文多模态预训练综述,涉及各种多模态模型和应用,并且附带视频教程,需要的同学快来领取!
发布人
-
打开封面
下载高清视频
观看高清视频
视频下载器
斯坦福大学AI博士,揭秘最新多模态AI - 杨俊睿 Jackie,MAUI
幻方发布超强多模态LLM DeepSeek-VL!支持代码,文档OCR等!
仅需0.5M!可集成任意扩散模型!字节提出灵活分辨率适配器ResAdapter!
GPT4o-mini:为什么模型越做越小
上交学者提出了一种利用Diffusion模型生合成语义分割数据集,并基于此训练了一个开放词汇分割的模型,效果惊艳!
基于Diffusion模型的以文生图综述来了!包含145篇相关论文,涉及Diffusion相关理论和基础介绍!
精选【人工智能课程】大模型时代 如何学习人工智能?零基础学习教程!人工智能学习路线 人工智能就业方向 人工智能 大模型 多模态技术路线 人工智能项目开发
我们把ALOHA机器人和多模态大模型结合了起来,来看看效果如何?
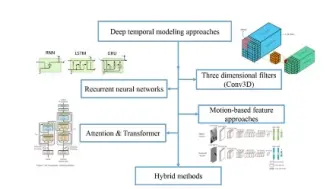
Human Action Recognition综述来了,近10年160篇论文,涉及RNN和CNN类型的方法,需要的同学快来领取!
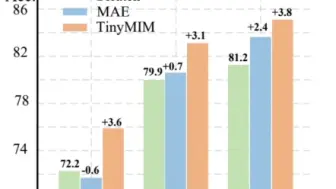
微软亚研提出了小模型蒸馏方法TinyMIM!MIM预训练小模型性能提升4个百分点!目前模型和代码均已开源!
【多模态+大模型+知识图谱】2024最好创新的研究方向!绝对是B站最全的教程,论文创新点终于解决了!——人工智能|深度学习|aigc|计算机视觉
黄仁勋 下一波AI是物理人工智能,它需要......来实现 !人工智能技术
原来AI真的能生成高颜值美女,快来试试多模态生成模型吧!
鹏城实验室学者提出了一种新的视频语言多模态预训练模型SOTA-VLP,融合了空间时序建模方法,捕获细粒度特征,多项任务取得SOTA!
阿里多模态团队基于OFA多模态预训练模型,提出最强中文OCR模型,效果惊艳!
图像+音频驱动的口播视频生成!谷歌提出VLOGGER!
字节联合爱丁堡大学学者提出新的多模态预训练方法MUG,结合MAE和Caption生成
零基础创建属于自己的AI多模态智能体(agent),并且集成到自己的Web应用(网站)中,通义千问大模型,扣子(Coze)平台教程
开源AI项目爆火!大叔秒变少女,GitHub狂揽7.9K星 | 零度解说
多模态大模型的幻觉类型和产生原因!大模型微调
【EMNLP2023】清华联合阿里提出了利用大型语言模型辅助多模态OOD检测的新方法!
InternVL 多模态模型语音功能小剧透!
太强了!终于找到了这个逐行解读代码的网站!github标星超52.4k!----机器学习/深度学习/CV/NLP
解锁CLIP长文本能力!即插即用替换CLIP!上海AI Lab提出Long-CLIP!
字节联合爱丁堡大学提出新的视觉预训练方法MUG,取得新的SOTA!模型和代码均已开源,快来领取!
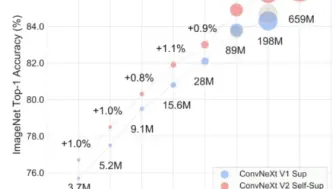
最强视觉backbone网络ConvNext v2来了!Meta AI融合了视觉掩码自监督框架,提出新的新的SOTA算法!目前代码和模型已开源!
膜拜大佬!2024最新的多模态模型CLIP教程,半小时讲明白CLIP模型的原理以及底层逻辑,看完就能全面了解神器CLIP!人工智能|深度学习|计算机视觉|NLP
NEURA 与 NVIDIA 携手重新定义机器人技术的未来!
动作识别最新综述来了,包含RNN,3D卷积以及Transformer等算法,涉及近300篇相关论文!
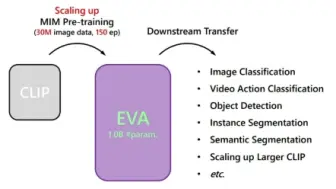
北京智源多模态团队提出EVA:多模态助力视觉自监督预训练,加入掩码,视觉表征学习更上一层楼!目前代码和模型已开源!
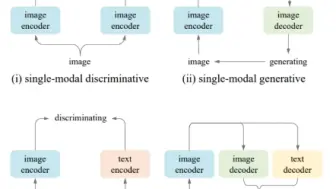
字节提出新的多边形战士,通用基础模型X-FM,将视觉,文本和多模态的训练做到了一个阶段,在多项下游任务表现不错!
05_多模态_基于MiniCPM-V进行全参微调和lora微调
中科大提出All-in-One多模态预训练方法,利用统一的多模态互信息提升多模态性能,下游检测分割性能超过BEIT V3!
微软多模态团队提出了新的语言增强多模态预训练大模型,可以类似BLIP2进行多模态chat,效果很惊艳!
基于Transformer的GAN网络综述来了!包含近50种GAN在图像和视频生成上的应用方法,涉及160篇论文!
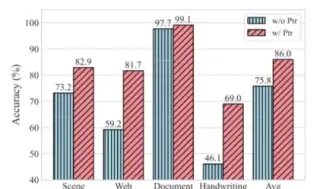
华为诺亚提出视觉文档理解多模态预训练模型WuKong-Reader,在百万级文档数据上进行了预训练,多项下游任务效果SOTA!
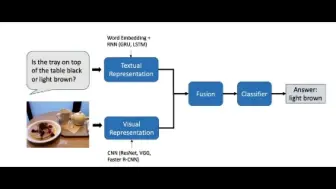
39页视觉问答(VQA)和视觉推理综述论文来了!涉及近30个数据集,50多种经典方法,VQA终于学会了!
将机器人接入大模型,使其听懂“人话”,自主决策
LLaVA+SEEM+GLIGEN,微软提出多模态交互原型Demo LLaVA-Interactive!
字节联合浙大提出新的视频语言预训练模型TemPVL,能够显著提升下游多模态视频理解任务性能!