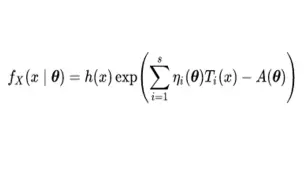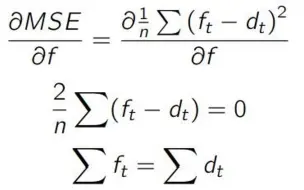V
主页
【手推公式】xgboost自定义损失函数(cross entropy/squared log loss)及其一阶导数gradient二阶导数hessian
发布人
打开封面
下载高清视频
观看高清视频
视频下载器
[数学!数学] 最大似然估计(MLE)与最小化交叉熵损失(cross entropy loss)的等价性
【手推公式】从二分类(二项分布)到多分类(多项分布),最大似然估计与交叉熵损失的等价
【手推公式】从二分类到多分类,从sigmoid到softmax,从最大似然估计到 cross entropy
数据降维方法:PCA, t-SNE, UMAP | 动画讲解
【手推公式】logistic regression 为什么不采用 squared loss作为其损失函数,如何从最大似然估计得到交叉熵损失函数
【手推公式】可导损失函数(loss function)的梯度下降(GD)、随机梯度下降(SGD)以及mini-batch gd梯度优化策略
[LLM 番外] 自回归语言模型cross entropy loss,及 PPL 评估
【手推公式】从 logodds 到 sigmoid 概率化输出,用于 LR、XGBoost 的分类任务
【手推公式】指数族分布(exponential family distribution),伯努利分布及高斯分布的推导
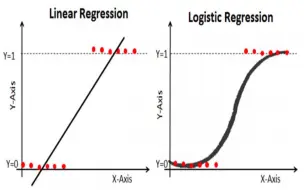
【手推公式】logistic regression 及其与 linear regression 的区别,对数线性与对数几率
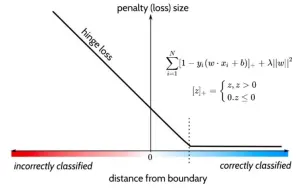
【机器学习】【手推公式】从Hinge loss(合页损失)到 SVM(hard margin/soft margin)
【手推公式】odds(几率)与对数几率(logodds)在logistics regression及xgboost classification中的应用
[动手写 Transformer] 手动实现 Transformer Decoder(交叉注意力,encoder-decoder cross attentio)
[手推公式] sigmoid 及其导数 softmax 及其导数性质(从 logits 到 probabilities)
通俗统计学原理入门 28 线性回归 找到那条直线 回归直线 最优拟合直线 最小二乘法 梯度下降算法 损失函数 权重 偏置
【手推公式】【目标检测】【Fast RCNN】RoIPooling 的作用及计算
[pytorch] F.binary_cross_entropy(二分类) 与 F.cross_entropy(多分类)
【手推公式】【销量预测】【回归分析】MAE与MSE在回归分析时的区别,为什么MSE倾向于回归均值,MAE倾向于回归中位数
[pytorch optim] pytorch 作为一个通用优化问题求解器(目标函数、决策变量)
【python 运筹】约束满足规划问题 | CP-SAT solver | ortools | 自定义打印所有可行解的回调函数
【手推公式】multi-classification多分类评估(precision/recall,micro averaging与macro averaging
[pytorch 强化学习] 10 从 Q Learning 到 DQN(experience replay 与 huber loss / smooth L1)
【手推公式】梯度下降(一阶泰勒展开)的一种直观形式
【数据处理】数据变换的三种形式,(几率)对数线性(log linear)、线性对数(linear log)、双对数log-log
[损失函数设计] 为什么多分类问题损失函数用交叉熵损失,而不是 MSE
[personal chatgpt] instructGPT 中的 reward modeling,概率建模与损失函数性质
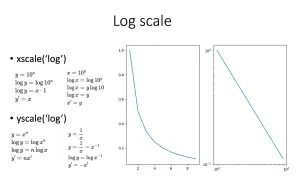
【数据变换】【可视化】xscale('log') , yscale('log'), log-log plot 非线性转换为线性
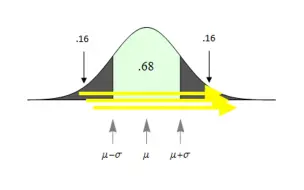
【机器学习中的数学】【概率论】正态分布的导数与拐点(inflection points)
【python 数学编程】SymPy 数学家的朋友 | hessian | Jacobian
[pytorch] [求导练习] 04 前向计算与反向传播与梯度更新(forward,loss.backward(), optimizer.step)
[python nlp] 01 词频分析与 Zipf law 齐夫定律(log-log plot)
[pytorch 模型拓扑结构] 深入理解 nn.BCELoss 计算过程及 backward 及其与 CrossEntropyLoss 的区别与联系
[RLHF] 从 PPO rlhf 到 DPO,公式推导与原理分析
[pytorch 强化学习] 01 认识环境(environment,gym.Env)以及 CartPole-v0/v1 环境
[LLMs 实践] 13 gradient checkpointing 显存优化 trick
如何求贝叶斯风险函数以及求贝叶斯风险
【销量预测】R2(r_squared)与相关系数(correlation)的区别和联系,什么情况下R2=correlation,R2与MAE,RMSE
[pytorch] 激活函数,从 ReLU、LeakyRELU 到 GELU 及其梯度(gradient)(BertLayer,FFN,GELU)
[多元变量微分] 方向导数与梯度下降方法(directional derivatives)
[AI 核心概念及计算] 优化 01 梯度下降(gradient descent)与梯度上升(gradient ascent)细节及可视化分析