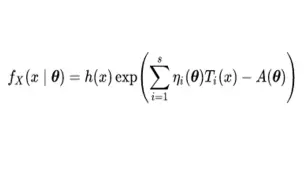V
主页
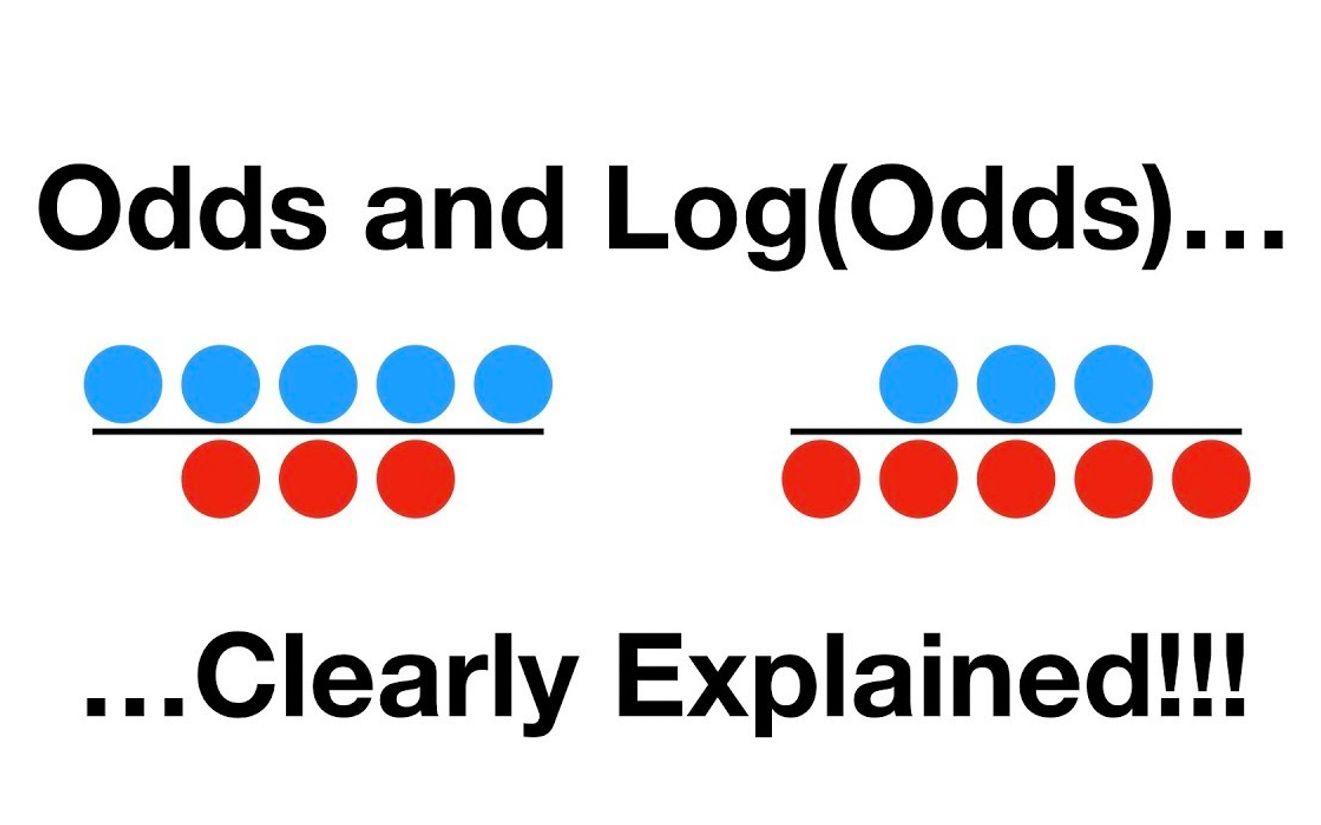
【手推公式】odds(几率)与对数几率(logodds)在logistics regression及xgboost classification中的应用
发布人
最后的二阶导数的推导: e^x/(1+e^x) ==> (e^x(1+e^x)-e^x)/(1+e^x)^2 ==> e^x/(1+e^x) * 1/(1+e^x)
打开封面
下载高清视频
观看高清视频
视频下载器
【机器学习】线性回归(linear regression)逻辑回归(logistics regression)特征重要性与 odds ratio
【手推公式】从二分类到多分类,从sigmoid到softmax,从最大似然估计到 cross entropy
【手推公式】可导损失函数(loss function)的梯度下降(GD)、随机梯度下降(SGD)以及mini-batch gd梯度优化策略
【手推公式】xgboost自定义损失函数(cross entropy/squared log loss)及其一阶导数gradient二阶导数hessian
【统计学】p-value(p值) 与 z-score(标准分/z得分/z分数)定义,计算以及适用场景
[蒙特卡洛方法] 04 重要性采样补充,数学性质及 On-policy vs. Off-policy
【矩阵分析】斐波那契数列(Fibonacci)通项公式的(矩阵矢量)推导
【手推公式】multi-classification多分类评估(precision/recall,micro averaging与macro averaging
[personal chatgpt] peft LoRA merge pipeline(lora inject,svd)
[LangChain] 03 LangGraph 基本概念(AgentState、StateGraph,nodes,edges)
[bert、t5、gpt] 11 知识蒸馏(knowledge distill)huggingface trainer pipeline
[sbert 01] sentence-transformers pipeline
【Python 金融】72法则 | 本金翻倍 | 每年复利 1 次 | 每年复利多次 | 连续复利 | 泰勒级数 | 麦克劳林公式
【回归】多元线性回归分析(最小二乘法,矩阵矢量形式,解析解)
[pytorch distributed] 张量并行与 megtron-lm 及 accelerate 配置
[sbert 02] sbert 前向及损失函数pooling method计算细节
[矩阵分析] 旋转矩阵的计算机与应用(复平面,RoPE)
【手推公式】指数族分布(exponential family distribution),伯努利分布及高斯分布的推导
[mcts] 02 mcts from scartch(UCTNode,uct_search, pUCT,树的可视化)
【手推公式】logistic regression 为什么不采用 squared loss作为其损失函数,如何从最大似然估计得到交叉熵损失函数
【统计】统计检验(从t-distribution(t分布)到t-test(t检验),t-score(t-统计量)以及卡方检验(chi-test),excel计算
[模型拓扑接口] 经典 RNN 模型(一)模型参数及训练参数的介绍
[全栈 docker] 03 docker 容器开发(start,exec)及 commit、save、load 持久化,docker vscode
【数学基础】高跟鞋该怎么选?黄金分割比与黄金分割矩形
[LLMs inference] quantization 量化整体介绍(bitsandbytes、GPTQ、GGUF、AWQ)
[程序员说金融] 对数回报率(收益率)及其性质(可加性,负对称性,及泰勒展开下的近似相等)
【python 运筹】混合整数规划 | MIP | ortools | SCIP | CBC
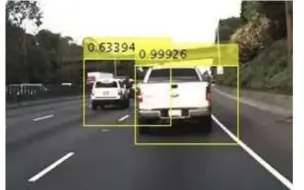
【手推公式】【目标检测】【Fast RCNN】RoIPooling 的作用及计算
[调包侠] python opencv 实现基础 object tracking(目标跟踪)
【数字图像处理】前景背景分割GrabCut实现(python-opencv)类似PhotoShop抠图的功能
[番外] float16 与 bf16 表示和计算细节
[程序员说金融] 等额本息概念及计算(月供还款分析:月供本金,月供利息)
【PS教程】100集(附素材)从零开始学Photoshop软件基础(2024新手入门实用版)PS2024零基础入门教程!!!
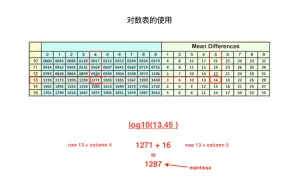
[数值计算] 快速计算、妙算对数,之对数表(logarithm table)的使用,如何将任意一个数转换为10-99,或0-0.99之间的可查表形式
【基础数学】1.01^365/0.99^365有数量级的变化,为什么1.001^365/0.999^365却没有数量级的变化。它们跟自然常数e关系,复利与年化
[动手写神经网络] 01 认识 pytorch 中的 dataset、dataloader(mnist、fashionmnist、cifar10)
【计算机基础算法】从排列到随机,字典序(lexicographic order)排列算法的实现
[实战kaggle系列] 1. 使用 kaggle 命令行 api,进行数据集的下载
【回归分析】最小二乘法的 python 实现以及 excel 回归分析及其可视化
[数值计算] 一阶泰勒展开快速计算一个数的平方根