V
主页
【研1基本功 (真的很简单)Group Query-Attention】大模型训练必备方法——bonus(位置编码讲解)
发布人
课件来自清华大学龙明盛老师(超级无敌厉害)深度学习课程(欢迎清华同学选修课程)
打开封面
下载高清视频
观看高清视频
视频下载器
作者亲自讲解:LoRA 是什么?
【研1基本功 别人不教的,那就我来】SSH+Git+Gitee+Vscode 学会了就是代码管理大师
【研1基本功 (真的很简单)注意力机制】手写多头注意力机制
从编解码和词嵌入开始,一步一步理解Transformer,注意力机制(Attention)的本质是卷积神经网络(CNN)
从0开始训练1.4b中文大模型的经验分享
【研1基本功 (真的很简单)Diffusion Model】构建预测噪声网络
[手写flash attention v1 & v2] baseline的基础实现
边睡边学算法丨第一期
【研1基本功 (真的很简单)Decoder Encoder】手写Decoder Layer 准备召唤Transformer
哥们还中了一篇CVPR2024——多模态时代让卷积网络再次伟大!
19、Transformer模型Encoder原理精讲及其PyTorch逐行实现
Transformer论文逐段精读【论文精读】
Flash Attention 为什么那么快?原理讲解
师傅,我真的悟了!Visual Transformer代码从头写一遍~
我大抵是难毕业了,效果巨烂。Yolov5+deepsort+1DCNN
姚顺雨-语言智能体博士答辩 Language Agents: From Next-Token Prediction to Digital Automation
深度解析Group-Query Attention的finetune和推理加速原理
【研1基本功 (真的很简单)Encoder Embedding】手写编码模块、构建Encoder Layer
Grouped-Query Attention (GQA)原理及代码介绍---以LLaMa2为例
第二十课:MoE
【研1基本功 (真的很简单)LoRA 低秩微调】大模型微调基本方法1 —— bonus "Focal loss"
扩散模型 - Diffusion Model【李宏毅2023】
【研1基本功 (真的很简单)Diffusion Vision Transformer (DiT)】构建DiT核心代码
【研1基本功 JAX加速框架】pytorch太慢,我偶尔选jax~
【研1基本功 (真的很简单)Diffusion Model】完成扩散模型!!结尾有bonus!!
从transformer到cnn到vit,两个半小时板书搞懂原理(上)
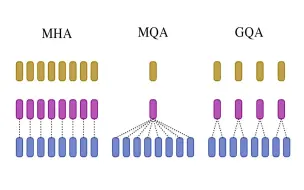
多头注意力(MHA)的变体:多查询(MQA)和分组查询注意力(GQA)
实验室的新4090深度学习工作站,从未有如此美妙的声音
认识混合专家模型(MoE)
手搓深度学习的代码?60分钟足够了!
【深度学习基本功!启动!】带你手敲Transformer代码之-Embedding篇!-神经网络/pytorch深度学习
德国华为“天才少年”读博经验分享会全记录
【很直接但很有用】多模态融合暴力涨点!一个有前景且易中稿的好思路!(附代码)
CVPR2024中的多特征融合,附即插即用代码
【研1基本功MultiGPU】多卡并行训练(以手写数字体识别为例)
【研1基本功 (真的很简单)Test-Time Training (TTT) part1】超越Transformer | Mamba 真的假的?
【研1基本功 (真的很简单)MoE】混合专家模型—作业:写一个MoELoRA
【官方双语】直观解释注意力机制,Transformer的核心 | 【深度学习第6章】
[QKV attention] flash attention(Tiling与重计算),operation fused,HBM vs. SRAM
大模型全栈总览