V
主页
[Diffusion进展,声音生成动画] 瑞典皇家理工学院的Listen-Denoise-Action,首个使用谈话或音乐生成动作或舞蹈(SIGGRAPH23)
发布人
Listen, denoise, action! Audio-driven motion synthesis with diffusion models Simon Alexanderson, Rajmund Nagy, Jonas Beskow, Gustav Eje Henter 项目主页:https://www.speech.kth.se/research/listen-denoise-action/ 代码即将开源 Diffusion models have experienced a surge of interest as highly expressive yet efficiently trainable probabilistic models. We show that these models are an excellent fit for synthesising human motion that co-occurs with audio, e.g., dancing and co-speech gesticulation, since motion is complex and highly ambiguous given audio, calling for a probabilistic description. Specifically, we adapt the DiffWave architecture to model 3D pose sequences, putting Conformers in place of dilated convolutions for improved modelling power. We also demonstrate control over motion style, using classifier-free guidance to adjust the strength of the stylistic expression. Experiments on gesture and dance generation confirm that the proposed method achieves top-of-the-line motion quality, with distinctive styles whose expression can be made more or less pronounced. We also synthesise path-driven locomotion using the same model architecture. Finally, we generalise the guidance procedure to obtain product-of-expert ensembles of diffusion models and demonstrate how these may be used for, e.g., style interpolation, a contribution we believe is of independent interest.
打开封面
下载高清视频
观看高清视频
视频下载器
[3D生成] 港科大、LightIllusions等提出CraftsMan(匠心),使用3D原生diffusion生成高质量3D网格,也可支持可交互的网格生成
SIGGRAPH Asia 2024 Technical Papers Trailer
[NeRF进展] 香港中文大学提出双边滤波器引导的NeRF重构,可以消除相机拍摄变化引起的artifact,也可以进行3D风格化渲染
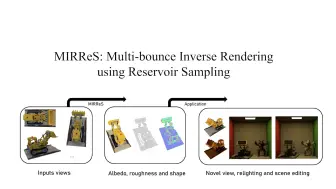
[逆渲染] 南洋理工、浙大、商汤等提出MIRReS,一种NeRF逆渲染算法,加入多次反弹光追,在复杂场景下达到更好的几何、材质和光照的重建效果
一段濒死时的音频
[CLIP进展,3D内容理解与检索] 约翰霍普金斯大学提出CG3D,使用点云、2D图像和文字训练,使CLIP可提取3D几何特征时,ChatGPT 3D又一方案
[点云法向,SIGGRAPH最佳论文] 山东大学、香港大学等提出通过正则化Winding-number场,全局一致性点云法向算法
原声来喽
[法线估计] StableNormal:香港中文大学(深圳)、阿里、西湖大学的二阶段法线估计器,有效解决了扩散模型做法线估计'锐利但不稳定'的问题,TOG接收
[3D生成] 南洋理工、香港中文、上海AI实验室提出DiffTF,一个基于扩散模型和三平面的前馈框架,用于生成多样化的、大语料量规模的真实世界3D物体
[可泛化GS重建] 华中科技大学、南洋理工等提出MVSGaussian,一种从MVS快速的可泛化的GS重建方法,可以有效、通用地重建未见的场景,并达到实时渲染
欧美满星推荐翻拍经典电影《壮志凌云二》
千人千图,AI实时生成游戏画面,CS:GO也被攻略了
[NeRF 3D场景理解] UC伯克利、Luma AI提出GARField,使用辐射场对任何事物进行分组,从姿势图像输入分解为具有语义意义的组的层次结构的方法
[Diffusion,人体动画进展] nVidia提出PhysDiff,在diffusion生成动画中加入物理规律优化,昨日关注度高,效果极好
声音变好听的6个方法
SIGGRAPH 2024 最佳论文- A Unified Theory of Light Transport With Stochastic Geometry
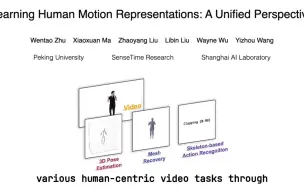
[Transformer进展,人体运动表达模型] 北京大学、商汤等开源MotionBERT,通过构建空时域双流Transformer,从2D视频提取人体运动表达
睡不着就听一下吧 猫爪白袜与圆木台的声音
这声音能听得出来40吗?30多了有娃雌竞拿到这么多嘿嘿
讲座 | HiDiffusion:高效、无需训练的更高分辨率图像生成框架——旷视研究院高级研究员张慎
[NeRF进展,镜头硬件参数校准] 康奈尔大学、Meta提出Neural Lens Modeling,在训练模型时同步优化相机参数,解决光学镜头参数校准问题
[NeRF报告] Google I3D 2023 Keynote,NeRF落地的两个方向,大场景与实时渲染各自的发展路线和现状,和一些关键问题的看法
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
直观理解Vision Transformer(ViT)及Diffusion Models使用扩散模型进行图像合成,
[NeRF进展,稀疏视角+depth先验] 南洋理工大学ICCV提出SparseNeRF,利用现实世界不准确观测的深度先验来蒸馏深度排名,达到较好的重建效果
Talk|香港中文大学汪福运:Rectified Diffusion - 一般扩散模型的ODE轨迹修正
[NeRF进展] Strivec(USC, UCSD, Adobe研究院),稀疏分布紧凑分解的局部张量特征grid的辐射场,比TensoRF和NGP效果好参数少
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
[NeRF进展,街景重建方向] 复旦大学提出S-NeRF,将街景重建PSNR提升45%,可以兼顾大规模场景背景与前景移动车辆处理
[NeRF进展,使用事件相机生成高质量NeRF] 马克思普朗克研究院,萨尔大学提出EventNeRF,使用事件相机生成高质量NeRF,低功耗、低数据量、快速重建
【ExplainingAI】中文字幕|DiT说明与代码实现 - Scalable Diffusion Models with Transformers
2024.11.24组会-生成模型专题汇报
帅气干净利索的格斗动画
[NeRF进展,单视角3D重建]香港大学、未来智联等联合推出S3-NeRF,挖掘Shading和Shadow信息提升单视角3D重建(NeurIPS 2022)
[文本转3D进展] 清华、人大等:ProlificDreamer,使用VSD解决过饱和、过平滑、低多样性问题,SDS是VSD的特殊情况,可应用在NeRF生成场景
[NeRF进展] 图宾根大学、Google提出Binary Opacity Grids,加强版本BakedSDF,生成视图质量更高,移动设备场景实时渲染
《捉刀人》2024最新高燃武侠大片,动作打戏酣畅淋漓,斩恶锄奸全程暴爽!
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影
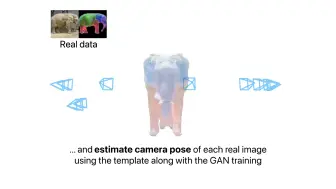
[3DGAN]浙江大学、香港理工和蚂蚁提出TeFF,无相机位姿3D感知GAN训练方法,在多个挑战的2D数据集上训练,生成样本可360度图像合成,并有完整几何形状