V
主页
[Diffusion,人体动画进展] nVidia提出PhysDiff,在diffusion生成动画中加入物理规律优化,昨日关注度高,效果极好
发布人
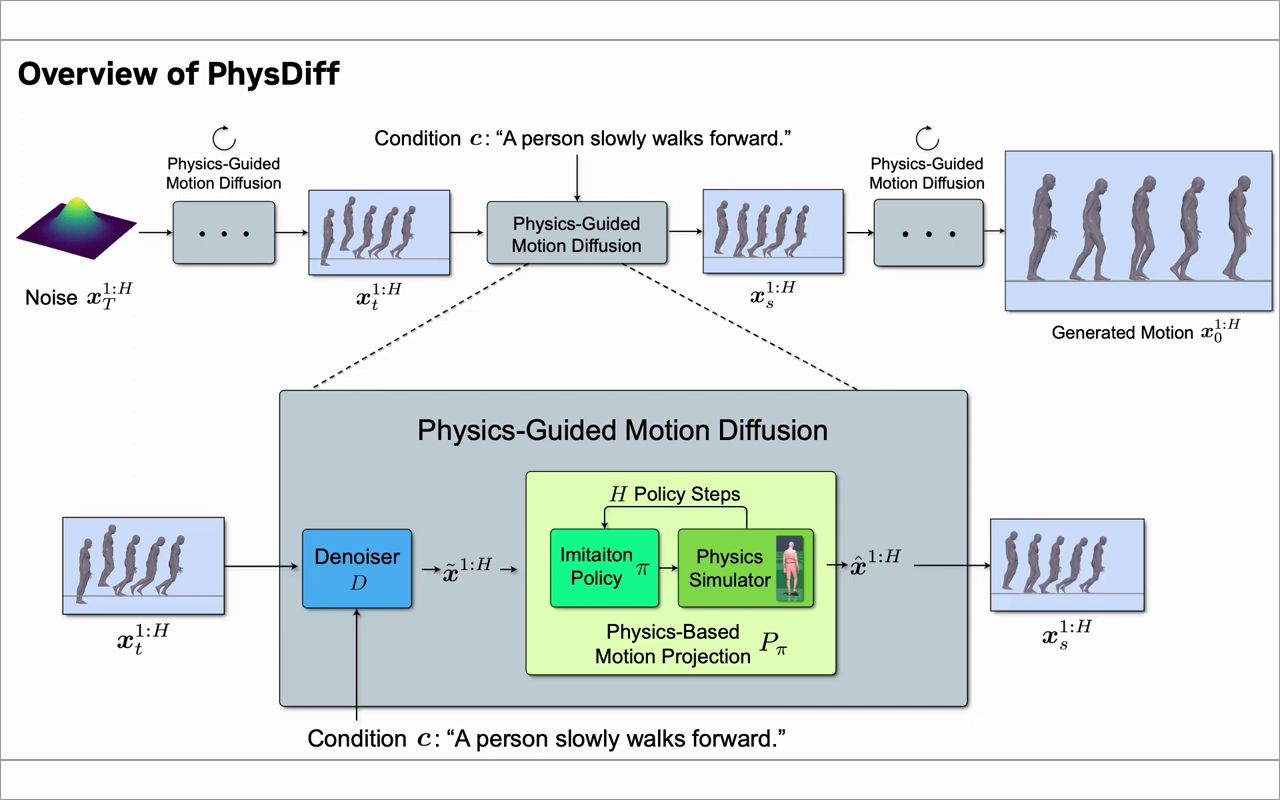
PhysDiff: Physics-Guided Human Motion Diffusion Model(arXiv preprint) Ye Yuan, Jiaming Song, Umar Iqbal, Arash Vahdat, Jan Kautz (nVidia) 项目地址:https://nvlabs.github.io/PhysDiff/ 文章地址:https://arxiv.org/abs/2212.02500 代码地址:https://github.com/nvlabs/physdiff(已创建,代码还未公布。有更新后,我发通知给关注的朋友们) 去嗓扩散模型在生成真实感多样化的人体动画有非常好的前景。然而,已有的运动扩散模型在处理过程中是不考虑物理学原理的,所以经常能产生出物理上不合理的缺陷动作,比如漂浮,脚步滑动或地面穿透等。这非常严重地影响到了生成的动画效果,并限制了它们在真实世界中的应用。为了解决这个问题,我们提出了一种新的物理指导的扩散模型PhysDiff,它可以把物理约束整合到扩散过程中,具体的说,我们提出了一种基于物理运动映射的模型。这个模型可以使用在物理模拟过程中,进行运动模仿,将扩散过程中被去嗓的动作映射到一个物理规则合理的运动。被映射的动作可以在后续的扩散步骤中继续使用,来指导其他的去嗓扩散过程。显然,在我们的模型中,迭代地使用物理规则,可以不断地将生成的运动变得符合物理规律。在大规模的人体运动集数据集验证,我们的方法可以极大的实现当前最佳的、符合物理规律的运动动画的质量和效果(对所有数据集错误因子提升78%) Denoising diffusion models hold great promise for generating diverse and realistic human motions. However, existing motion diffusion models largely disregard the laws of physics in the diffusion process and often generate physically-implausible motions with pronounced artifacts such as floating, foot sliding, and ground penetration. This seriously impacts the quality of generated motions and limits their real-world application. To address this issue, we present a novel physics-guided motion diffusion model (PhysDiff), which incorporates physical constraints into the diffusion process. Specifically, we propose a physics-based motion projection module that uses motion imitation in a physics simulator to project the denoised motion of a diffusion step to a physically-plausible motion. The projected motion is further used in the next diffusion step to guide the denoising diffusion process. Intuitively, the use of physics in our model iteratively pulls the motion toward a physically-plausible space. Experiments on large-scale human motion datasets show that our approach achieves state-of-the-art motion quality and improves physical plausibility drastically (>78% for all datasets).
打开封面
下载高清视频
观看高清视频
视频下载器
[Diffusion+NeRF进展]慕尼黑工业大学、Meta研究院提出DiffRF (也许是首次)基于扩散模型的3D辐射场生成方法
[NeRF进展,动画方向] 东京大学在同年提出与我国CageNeRF类似的NeRF动画控制方法,同步了解别人的想法(ECCV 2022)
[NeRF+Diffusion进展,图片生成3D] 上海交通大学,香港科技大学,微软提出MakeIt3D,使用Diffusion Prior将单图转为3D效果
[Diffusion进展] Google Research Imagen模型,提出一种新的图片生成文字的AIGC框架,更好的生成效果(NeurIPS 2022)
[Neural Rendering]Facebook Reality Lab提出AutoAvatar,推进神经场技术到真实人体动效生成领域(ECCV 2022)
[NeRF进展,单视角3D重建]香港大学、未来智联等联合推出S3-NeRF,挖掘Shading和Shadow信息提升单视角3D重建(NeurIPS 2022)
[NeRF进展,雾状鬼影消除] 伯克利提出NeRFBusters,使用3D Diffusion模型,对随意捕捉的NeRF去除雾状鬼影
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[NeRF进展,实时渲染方向]格拉茨科技大学与Meta提出AdaNeRF,通过双网络模型自适应采样实现NeRF的实时渲染(ECCV 2022)
[GAN进展,真实感人图片生成] 3DHumanGAN,上海人工智能实验室与商汤提出3D-Aware的真实感人全身图片生成方法
[Diffusion+SDF,三维重建] 港中文、上海AI实验室、浙大提出DiffRoom,基于occupancy先验重建TSDF,生成高质量3D室内重建效果
[NeRF进展,高保真3D Avatar生成]香港科技大学、微软研究院提出Rodin,自动高保真、高细节度生成3D Avatar NeRF模型,数字虚拟人再突破
[NeRF进展,大规模3DSRF数据集与合成模型]KAUST与慕尼黑工业大学Matthias团队提出SPARF数据集和SuRFNet,提升SRF渲染质量与性能
[NeRF,场景语义建模与应用]Meta提出SSDNeRF,首个通用NeRF场景语义分割方法,将场景按语议分割建模,让NeRF二次编辑、丰富动画场景变为可能
[NeRF进展,文本生成3D] Google,Ben、Jonathan提出DreamBooth3D,DreamBooth+DreamFusion,文本生成3D
[点云进展,单图生成3D图片动画] 华中科技大学,Adobe,南洋理大学CVPR提出使用单图片生成3D图片动画的工作,提升图片内容表现力
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[Diffusion进展,文本转视频]新加坡国立大学、腾讯ARC实验室提出Tune-A-Video,使用文本生成图片模型One-Shot精调至视频,效果很棒
[神经渲染,自动驾驶方向] Waabi,多大,MIT提出UniSim,一种神经sensor模拟器,可以用从录制结果生成真实的close-loop多传感器仿真效果
[NeRF进展,3D形状表达] KAUST和TUM发表3DShape2VecNet,面向扩散生成模型的形状神经场表达,对3D形状编码和生成及多个下游任务非常有效
[NeRF进展,使用不同场景时期图片重建NeRF] 华盛顿大学、Google Research提出PersonNeRF,灵活使用各场景、时期图片重建人物NeRF
[NeRF进展,文本转3D,20221228发表]腾讯ARC Lab、PCG,上海科技大学等提出Dream3D,使用文本转形状+CLIP,提升文本转3D效果
[NeRF进展,点云重建] 捷克理工大学提出Tetra-NeRF,使用点云为输入,使用四面体和其德劳内表达进行重建,实现更好的重建性能和效果
[人体3D动画] 清华、哈工大、MPI提出ProxyCap,首个使用2D骨架序列和3D旋转运动数据集,使用单目采集视频实时进行3D人体动作采集
[NeRF进展,避免重建干扰,提升重建效果] Google研究院,多伦多大学,SFU提出RobustNeRF,在场景中有影响效果时,用优化算法达到更好的重建效果
[NeRF+自动驾驶]浙江大学提出READ,使用神经渲染方法完成大尺度级别的街景场景渲染,合成、缝合、编辑真实感自动驾驶场景(AAAI 2023)
[NeRF进展,高精度人头部动作生成] TUM提出NeRSemble,组合变形场和多分辨率3Dhash编码高精度生成人头运动。同时提供多视角高精度运动数据集
[NeRF+Diffusion进展,无条件或单视角重建] 同济大学、Apple等提出SSDNeRF,使用单阶段扩散prior生成NeRF,支持无条件或单视角重建
[Avatar生成] 快手、卡迪夫大学提出TRAvatar,高保真度、实时动态全局光照,可变表情的Avatar生成方法
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%
[NeRF进展,人脸动画,褶皱渲染] 华沙工业大学、UBC、微软、Google等提出BlendFields,在少量数据下,结合图形学方法,生成细节表情动画
[NeRF进展,街景重建方向] 复旦大学提出S-NeRF,将街景重建PSNR提升45%,可以兼顾大规模场景背景与前景移动车辆处理
[NeRF进展,移动实时渲染方向]Snapchat与东北大学联合推出MobileR2L,在移动设备上实时、低消耗、高质量地渲染NeRF三维场景,移动应用有突破
[Transformer进展,人体运动表达模型] 北京大学、商汤等开源MotionBERT,通过构建空时域双流Transformer,从2D视频提取人体运动表达
[SDF进展,哈希+SDF] nVidia, 约翰霍普金斯大学提出Neuralangelo,综合了多分辨率的hash grid和SDF,实现了更好的从RGB视频
[NeRF进展,快速人体动态NeRF建模] 浙江大学提出InstantNVR,速度提升100倍以上的快速人体动态NeRF建模方法,CVPR 2023已发布
[Generative AI进展,基于2D Label的3D感知的生成模型] CMU提出pix2pix3D,基于2D Label的3D感知的可控真实感图生成模型
[NVS和三维生成进展] 香港大学、腾讯等提出SyncDreamer,不使用SDS损失,使用单图生成多视角一致性图片,进而使用Neus和NeRF重建三维模型
[Diffusion生成NeRF] TUM, Apple提出HyperDiffusion,用Diffusion计算神经场权重,统一框架下生成3D权重或4D动画
[NeRF进展] MoFaNeRF,基于NeRF的面部可变形模型,让面部拟合、生成、面部绑定、面部编辑更容易,效果更好(ECCV 2022)