V
主页
[可泛化GS重建] 华中科技大学、南洋理工等提出MVSGaussian,一种从MVS快速的可泛化的GS重建方法,可以有效、通用地重建未见的场景,并达到实时渲染
发布人
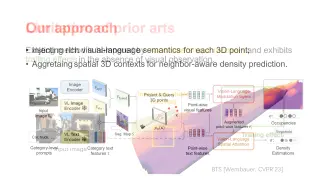
MVSGaussian: Fast Generalizable Gaussian Splatting Reconstruction from Multi-View Stereo Tianqi Liu, Guangcong Wang, Shoukang Hu, Liao Shen, Xinyi Ye, Yuhang Zang, Zhiguo Cao, Wei Li, Ziwei Liu 项目主页:https://mvsgaussian.github.io/ We present MVSGaussian, a new generalizable 3D Gaussian representation approach derived from Multi-View Stereo (MVS) that can efficiently reconstruct unseen scenes. Specifically, 1) we leverage MVS to encode geometry-aware Gaussian representations and decode them into Gaussian parameters. 2) To further enhance performance, we propose a hybrid Gaussian rendering that integrates an efficient volume rendering design for novel view synthesis. 3) To support fast fine-tuning for specific scenes, we introduce a multi-view geometric consistent aggregation strategy to effectively aggregate the point clouds generated by the generalizable model, serving as the initialization for per-scene optimization. Compared with previous generalizable NeRF-based methods, which typically require minutes of fine-tuning and seconds of rendering per image, MVSGaussian achieves real-time rendering with better synthesis quality for each scene. Compared with the vanilla 3D-GS, MVSGaussian achieves better view synthesis with less training computational cost. Extensive experiments on DTU, Real Forward-facing, NeRF Synthetic, and Tanks and Temples datasets validate that MVSGaussian attains state-of-the-art performance with convincing generalizability, real-time rendering speed, and fast per-scene optimization.
打开封面
下载高清视频
观看高清视频
视频下载器
[数字人] 华中科大、南洋理工、大湾区大学等提出WildAvatar,开源的在不可控自然场景中,利用普通只能手机重建数字人形象的数据集和方法
[群友SIGGRAPH工作] 上科大等推出DressCode,使用文本生成真实感服装,通过大语言模型交互生成CG友好的服装
[NeRF+自动驾驶] 浙大、图宾根大学提出PanopticNeRF360,将3D标记与带噪声的2D语义线索组合生成一致性全景标签和高质量任意视角图片的方法
[3DGS] 南开大学实时新视图合成、HDR 渲染、重新聚焦和色调映射更改,相比体渲染,训练速度缩短至1%,2K分辨率渲染提升4000倍
[三维重建] nVidia提出NKSR,一种新的从噪声的稀疏的点云重建地球级别3D表面的方法,可以在数秒中内完成对百万点的重建,并达到极好的效果
[3DGS几何优化]上科大、图宾根大学提出2DGS,一种从多视图图像中建模和重建几何精确辐射场的新方法,解决3DGS几何一致性差的问题
【新加坡】南洋理工大学 走进校园
[3DGS大规模场景] 3DGS原作者在大规模场景高斯层次细节表达新工作,可达到覆盖数公里的超大规模数据集上的实时渲染
[NeRF进展,稀疏视角+depth先验] 南洋理工大学ICCV提出SparseNeRF,利用现实世界不准确观测的深度先验来蒸馏深度排名,达到较好的重建效果
[Diffusion+SDF,三维重建] 港中文、上海AI实验室、浙大提出DiffRoom,基于occupancy先验重建TSDF,生成高质量3D室内重建效果
[NeRF进展,风格化与重着色,NPR方向]东京大学使用一种新的Palette提取方法,使NeRF重着色可达到实时性能,实现NPR效果(EGSR 2022)
[单视图重建]ETH、Google和TUM提出KYN,一种基于NeRF的3D密度重建方法,使用单视图恢复3D形状,提升了零样本泛化能力
TUM AI Lecture Series - Ben Poole(Google Brain)基于2D先验的3D生成方法(2023.07.18)
[3D生成] 港科大、LightIllusions等提出CraftsMan(匠心),使用3D原生diffusion生成高质量3D网格,也可支持可交互的网格生成
[3DGS] 作者Bernhard Kerbl讲讲3DGS的历史、思考过程(感谢群友的投喂)
[NeRF进展,稀疏视角重建] 斯坦福,Google, SFU提出SCADE,使用cIMLE和space carving方法,提升稀疏无约束室内NeRF重建效果
[NeRF进展,单目视频重建动态人-物-场景] 新加坡国立大学,腾讯等提出HOSNeRF,使用单目视频动态人-物-场景,LPIPS相比SOTA提升40%以上
[3DGS进展] UT Austin,厦门大学提出LightGaussian,装饰3D高斯表达为更高效和紧凑的格式,存储效能提升15倍,渲染达120fps
[Avatar生成] 快手、卡迪夫大学提出TRAvatar,高保真度、实时动态全局光照,可变表情的Avatar生成方法
[NeRF App] Luma AI推出新APP:Flythroughs,unbounded场景通过iPhone即可完成建模和漫游,已经发布上线,可开放体验
[街景重建]浙大、华为等提出EDUS,一种高效深度引导城市视图合成方法,在新街景合成有良好的泛化效果,并在稀疏视图输入达到很好的鲁棒性
【三维重建】InstantSplat:稀疏视角重建三维场景(无需SFM位姿)
[群友工作] 上科大,Deemos等推出Media2Face,语音合成 3D 面部动画的新算法以及多型、多样化的扫描级别语音与3D协同数据集M2M-D
[NeRF进展,使用事件相机生成高质量NeRF] 马克思普朗克研究院,萨尔大学提出EventNeRF,使用事件相机生成高质量NeRF,低功耗、低数据量、快速重建
【几何直觉】3D Gaussian Splatting(三维高斯泼溅), SuGaR 背后的几何 insight 讲解
[3DGS进展] 浙大CADCG,字节提出可变形的3DGS方法,对单目动态场景进行建模,在渲染质量和速度取得优势,适合NVS问题,时间序列合成和实时渲染
[NeRF进展] 香港中文大学提出双边滤波器引导的NeRF重构,可以消除相机拍摄变化引起的artifact,也可以进行3D风格化渲染
【计算材料学-从算法原理到代码实现】视频教程 | 7.20_机器学习势模拟Pt纳米颗粒在TiO2表面上的烧结
[NVS和三维生成进展] 香港大学、腾讯等提出SyncDreamer,不使用SDS损失,使用单图生成多视角一致性图片,进而使用Neus和NeRF重建三维模型
双非一本中外合办,申到南洋理工?
[NeRF进展] MPI提出NeuralClothSim,一种使用Kirchhoff-Love布料模拟方法,将表面变化过程编码到神经网络中,实现更好的模拟效果
[3D特征] 克莱姆森大学,微软,CMU提出CVRecon,一个新的端到端 的3D神经重建框架,挖掘cost volume中的几何信息,提供了优质的3D特征
[NeRF报告] Google I3D 2023 Keynote,NeRF落地的两个方向,大场景与实时渲染各自的发展路线和现状,和一些关键问题的看法
[人体建模] 浙大CADCG、达摩院提出TransHuman,基于Transformer和TransHE、DPaRF和FDI实现可泛化的神经人体渲染任务
【3DGS】自定义相机教程(含代码)(三维高斯泼溅)
[NeRF+Diffusion进展,无条件或单视角重建] 同济大学、Apple等提出SSDNeRF,使用单阶段扩散prior生成NeRF,支持无条件或单视角重建
[NeRF进展,2D图片生成3D人体] 南洋理工大学提出EVA3D,通过使用人体的分解NeRF表达,使用2D图片集训练生成高质量3D人体模型
[点云进展,单图生成3D图片动画] 华中科技大学,Adobe,南洋理大学CVPR提出使用单图片生成3D图片动画的工作,提升图片内容表现力
[3DGS进展] 南京大学、复旦大学提出Relightable 3DGS,基于点的可微分渲染,从多视图中进行材质和照明分解,实现3D点云的编辑、光线追踪和重照明
[NeRF进展,深度估计方向,群友推荐] 博洛尼亚大学、Google等提出NeRF监督的深度立体方法,使用NeRF监督更加准确的深度度和视差图,提升超过30%